本文是接着上一篇深度学习之 10 卷积神经网络3_水w的博客-CSDN博客
目录
◼ 2种方案实现:自定义卷积层和 torch.nn.Conv2d
◼ 2种方案实现结果:自定义卷积层和 torch.nn.Conv2d
卷积神经网络
1 卷积基本操作
◼卷积运算:定义卷积运算
卷积层的输出形状与 输入形状、卷积核窗口 有关。
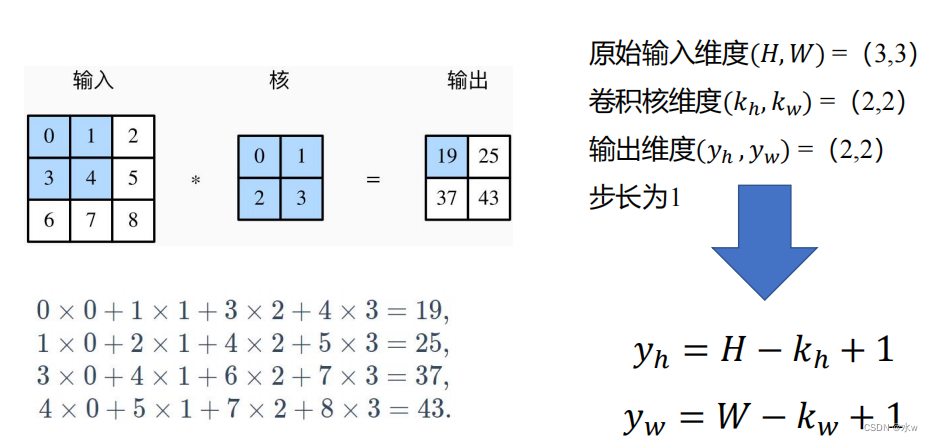

◼ 构造卷积层:将卷积运算封装成卷积层
卷积层参数: 卷积核、偏差 (随机初始化)

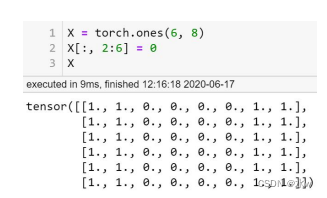
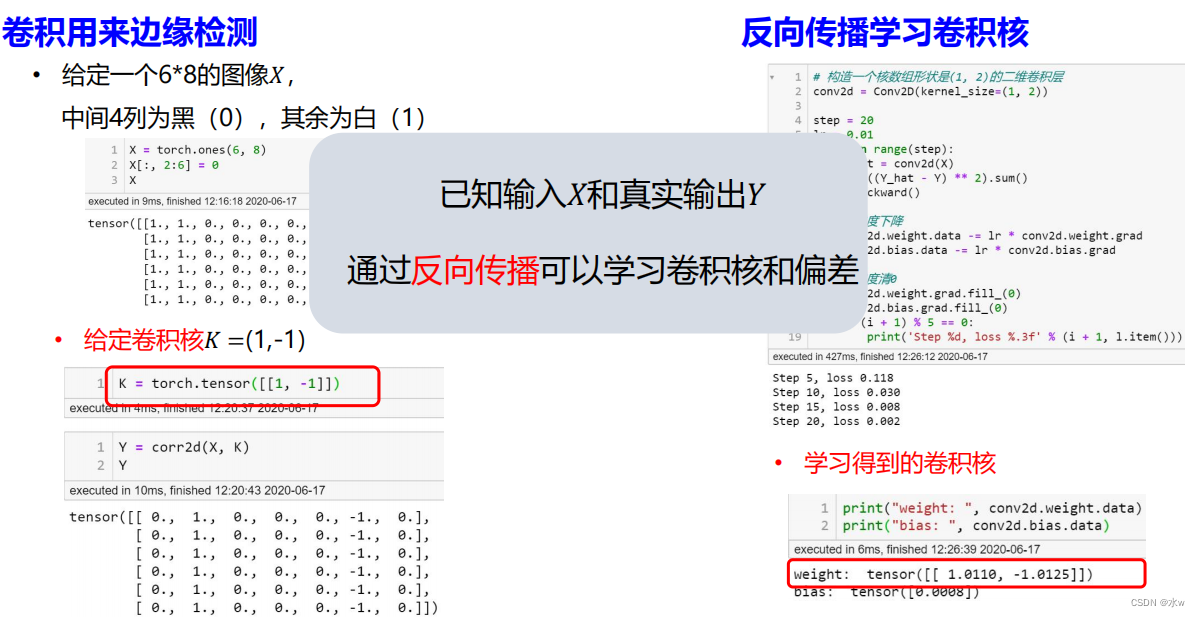
◼ 卷积的应用:卷积用来边缘检测

在实际上的训练过程中,我们面临的情况是什么样的呢?
我们实际面临的情况就是有斑马的真实图片和斑马的边缘图片,但是我们并不知道这个实际上的这个卷积盒,它是什么样子的。也就是说我们需要去设计一个模型来学习这个卷积核,学习完这个卷积核之后,之后,就可以通过卷积核以及输入来得到我们的输出。

那么对于我们这个例子而言,如果说知道X,然后知道我们的Y。怎么样去求这一个卷积核?这是我们需要学习的一个过程。
对于刚才提到的对于知道X和知道Y,然后怎么样去学习那个卷积核。其实这就进入到这个深度学习中的反向传播训练卷积核这一块来了。 ↓
◼ 反向传播训练卷积核
首先,我们先实例化一个自定义的卷积层。然后这个卷积层的卷积 核大 小是1x2的。然后我们假设训练的轮数是20轮,将学习率设置为0.01。然后之后就是开始进行训练。而训练中的每一轮,刚开始我们是先把输入X,通过一个卷基层来得到我们的输出y_hat。然后呢,因为我们的目标是想让这个神经网络输出的y_hat和我们真实的Y是要尽可能的一致的。所以说这里我们用的这个是回归的MSE损失作为这个损失函数,得到损失之后作一个梯度下降,然后梯度清零(目的:为了下次的梯度计算可以正常运行)。
通过20轮的训练,我们可以看到我们学习到的卷积核的结果是1.0110和-1.0125,偏置是0.0008,和我们给定的原始的值1和-1,偏置b=0已经很接近了。
结论:已知输入X和真实输出Y通过反向传播可以学习卷积核和偏差。
2 填充和步幅
卷积层的2个超参数:填充、步幅• 填充:通常用“0”填充• 步幅:通常用来减少输出的高和宽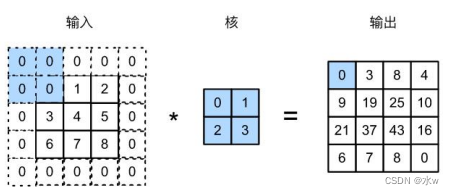
◼ 实现填充和步幅
输入X的大小是8x8的,通过填充和步幅之后,输出的Y是4x4的。

◼ 实现多输入通道
卷积核通道数 = 输入通道数

◼ 实现多输出通道
输出通道数 = 卷积核个数

3 池化层
最大池化、平均池化 、 自定义池化• 减少输出的高和宽• 缓解卷积层对位置的过度敏感性
◼ 最大池化
对于我们框住的这个范围中的数据,选择最大的元素来作为输出的结果放在结果矩阵中。

◼ 平均池化
对于我们框住的这个范围中的数据,选择所有元素的平均值来作为输出的结果放在结果矩阵中。
◼ 自定义池化

4 卷积神经网络模型 CIFAR-10数据集分类任务
用以下2种方式实现卷积神经网络模型,实现CIFAR-10图像分类任务。• 自定义的卷积层(N=1)• PyTorch已封装的卷积层(N=3)CIFAR-10数据集:包含60,000张32*32的彩色图像,维度(3, 32, 32) ,一共有10类,每类有6,000个图像=5,000个训练集+1,000个测试集

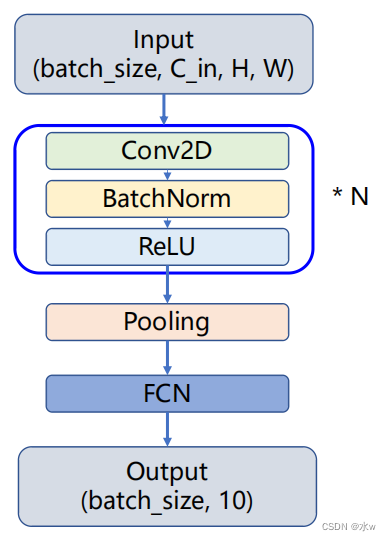
◼ 大致模型结构:
- Input:输入:
- batch_size:批量大小
- C_in:输入通道数
- H,W:图像高,图像宽
- 输入到N个卷积模块中,每一个卷积模块包括三个组件:
- Conv2D:卷积操作
- BatchNorm层(可选):会对输入的数据作一个标准化的操作, 用来缓解过拟合现象和帮助训练更加稳定。
- ReLu:激活函数
- Pooling:通过堆叠多个卷积模块,再通过一个池化层,进行进一步的图片降维。
- FCN:经过全连接网络,就可以得到我们的输出,输出结果的维度是batch_size x 10这么一个二维张量。输出的第i列就代表我们对应的样本的属于第i个类别的可能性大小。
◼ 2种方案实现:自定义卷积层和 torch.nn.Conv2d
◼ 自定义卷积层

◼ torch.nn.Conv2d


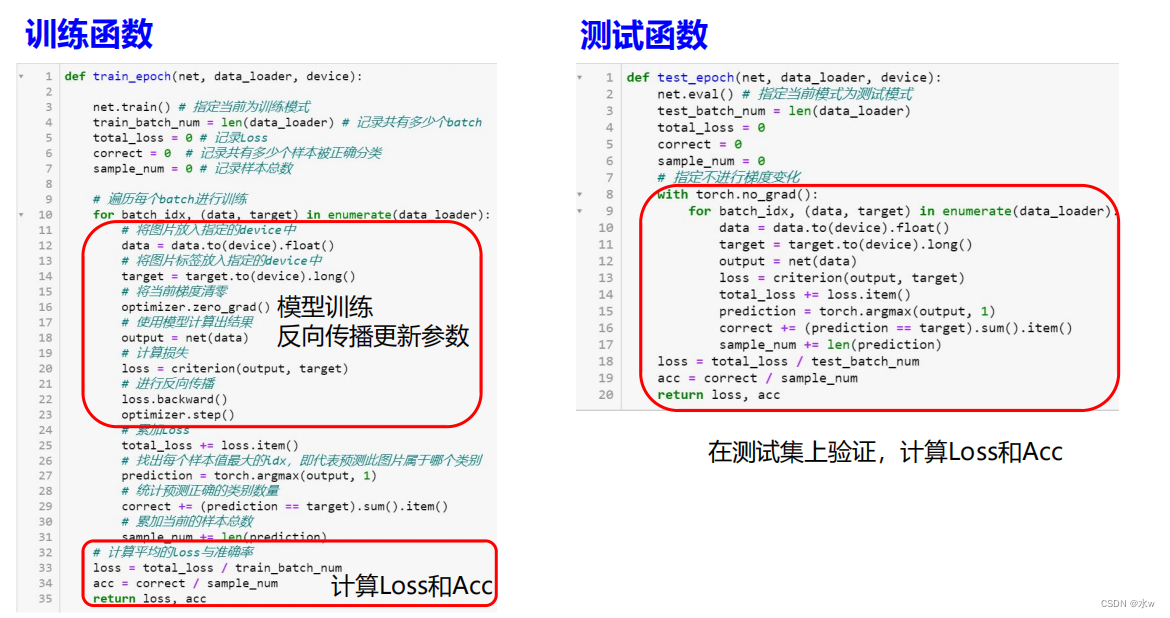
◼ 定义训练和测试函数
有了模型之后,我们定义一下训练和测试函数。
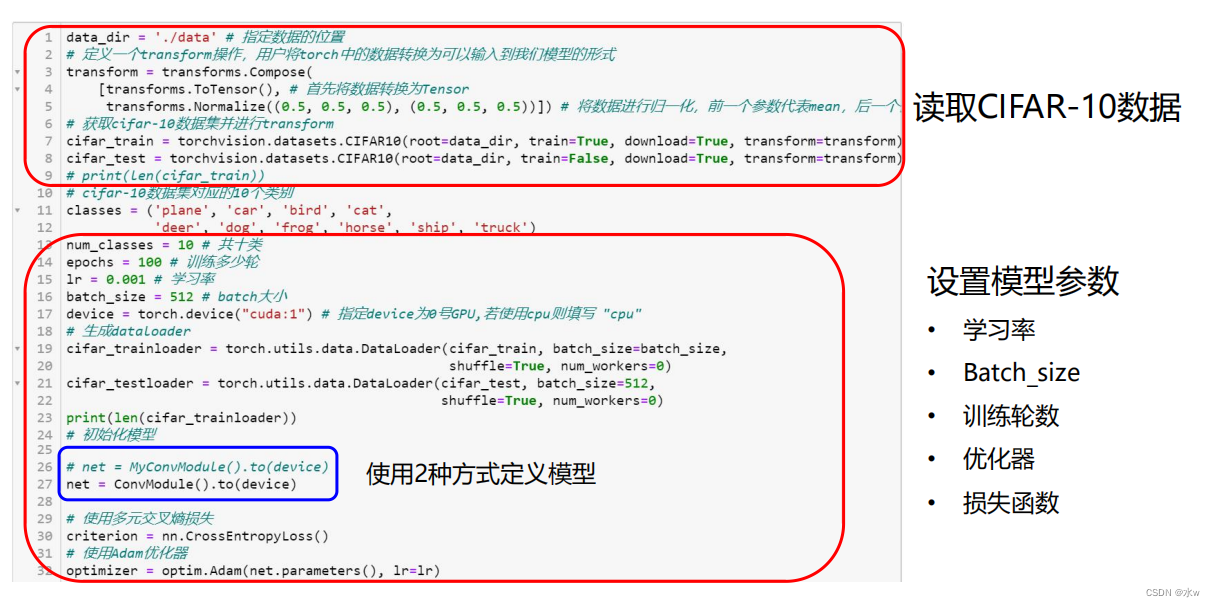
◼ 读取数据
刚才我们已经完成了整个模型的搭建过程,接下来就是要把我们的数据集进行加载,
◼ 2种方案实现结果:自定义卷积层和 torch.nn.Conv2d
◼ 自定义卷积实验结果:跑了5轮
• 耗时太长,1轮耗时>5h• 分析原因:卷积操作使用for循环实现,而不是矩阵操作
◼ PyTorch封装卷积实验结果:跑了100轮

随着模型的训练,我们可以发现训练集上的曲线不断下降,从准确率而言,以一个比较稳定的方式下降,说明模型具备了一定的学习能力。但是测试集上的曲线下降了一段时间之后就不怎么下降了,甚至有的时候上升,比较抖动,这说明模型接近过拟合了。
一般情况下,loss曲线都没有想象中的那么光滑,也就是说我们设计的模型都不是比较完美的,肯定会有缺陷,从而导致各种各样的结果,这时我们就需要分析导致结果产生的可能性。