卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,长期制霸计算机视觉领域。其核心主要是“卷积与池化”接下来我将介绍卷积神经网络进行特征提取的原理
1、基本概念
对比普通的神经网络,卷积神经网络包含了由 卷积层 和 池化层 构成的特征提取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。而不会像神经网络一样全连接
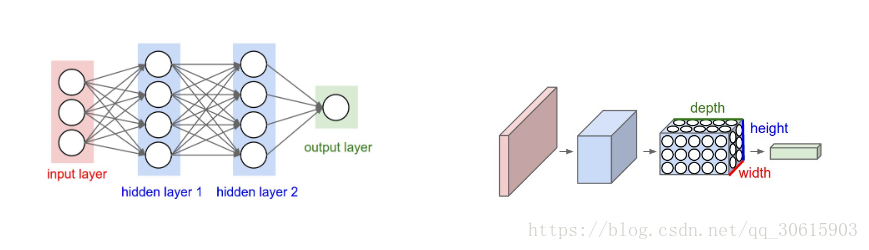
在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
网络结构主要包含以下层次
- 输入层/input layer
- 卷积层/conv layer
- Relu激励层/Relu layer
- 池化层/Pooling layer
- 全连接层/FC layer
- Batch normalization层(可能存在)/BN layer
1.1、卷积层
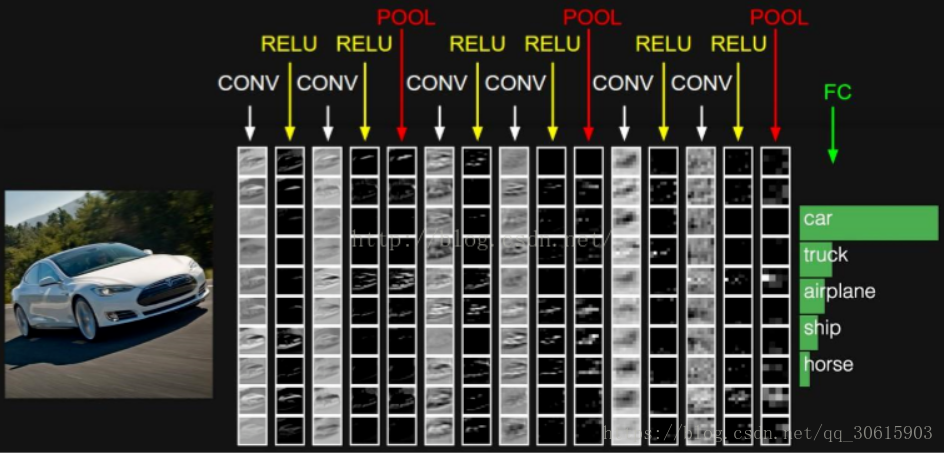
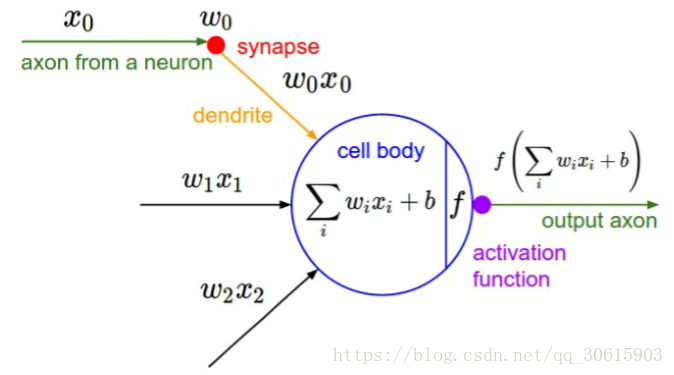
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。举例说明,我们人脑看一张图片的时候其实在背后有着不同的神经元共同工作使得我们的大脑得以理解的,每个神经元都不一样有的对方块敏感,有的对圆形敏感。我们就可以把这个神经元看做我们的滤波器 filter 也叫卷积核 kernel,在我们的卷积神经网络中就是通过这写 filter 进行图片识别的。
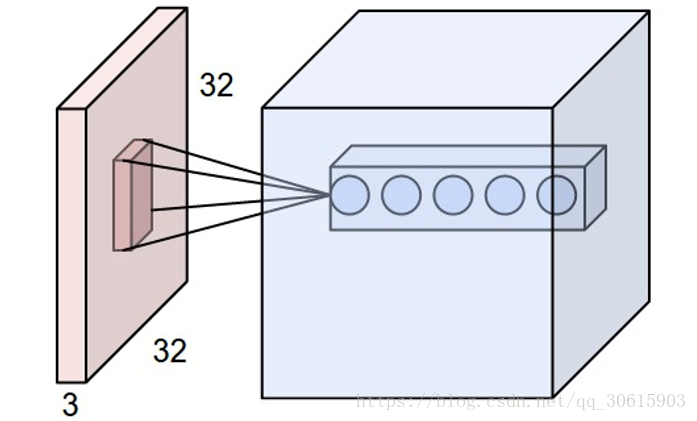
- 局部连接 :在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。所以那就让每个神经元与只其中一部分相连接。该连接的空间大小叫做神经元的感受野(receptivefield),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。
- 深度:卷积之后输出数据体的深度是一个超参数,他和滤波器filter的数量一致,这也就是为什么与神经网络相比卷积网络变成立体的原因。
- 步长:在滑动滤波器的时候,步长为每次滑动的像素,常用1和2,步长会导致输出的数据体在空间上变小。
- 零填充:也就是padding 就是在输入数据体的边缘上使用0补充大小,使用零填充可以有效地控制输出数据体的尺寸。
- 权重共享:每个神经元连接窗口的权重都是一样的,因为就像我之前所说每个神经元只负责提取特定的特征,只认识直线或者弧线等。否则的话由于图片转移成矩阵之后,很多参数在经过卷积之后就变得更庞大了,而且还只是一层,这也是为什么CNN训练会消耗很多资源的原因。
在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。
可查看动态图
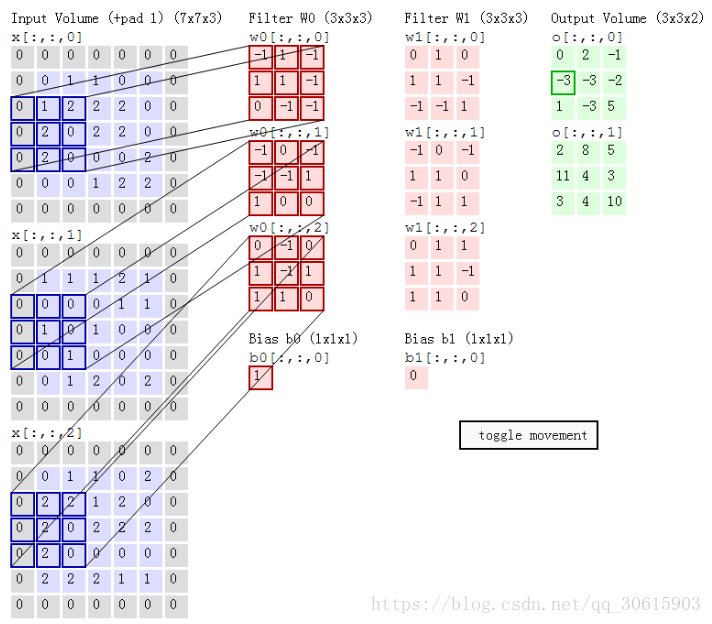
接下来给出卷积层超参数设置规律
- 输入数据体大小为
- 滤波器数量 K; 滤波器大小 F ;步长 S ;零填充 P
- 输出数据体的尺寸为
1.2、池化层
在连续的卷积层之间用来压缩数据和参数的量,使得计算资源耗费变少,也能有效控制过拟合。
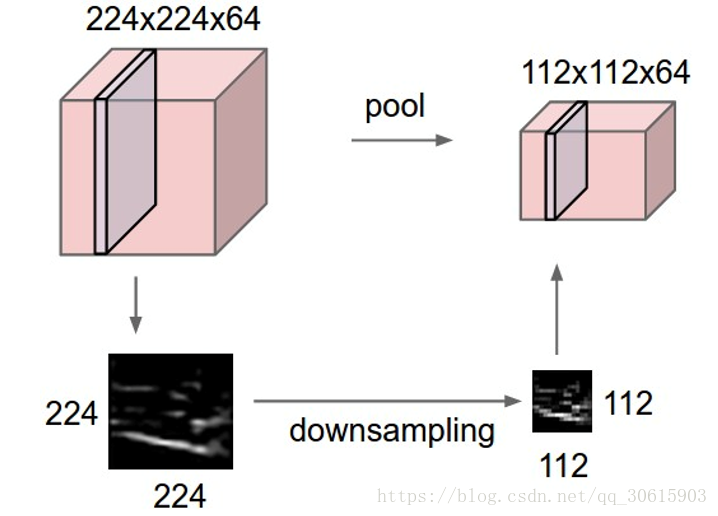
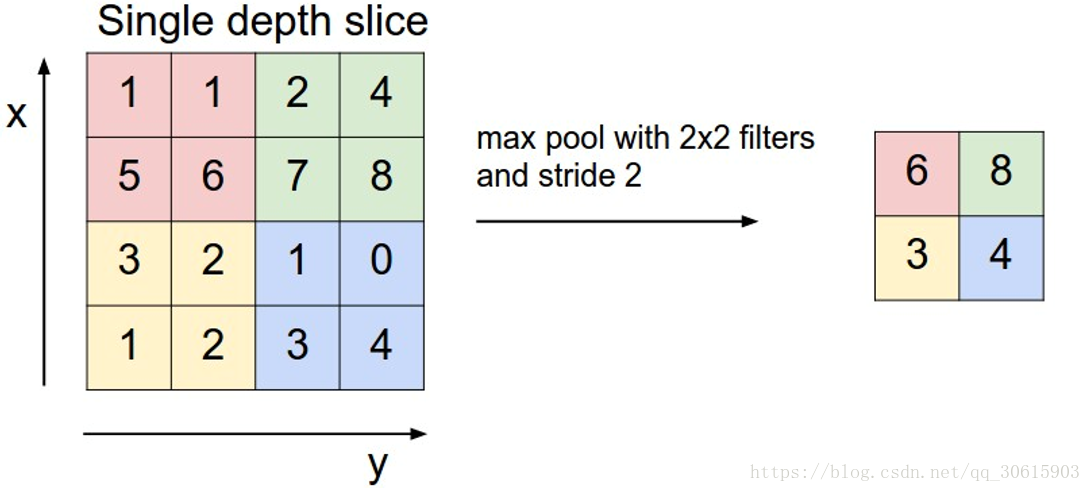
通常使用Max pooling 最大池化,当然也存在 average pooling 平均池化等其他池化方式
1.3、激励层
把卷积层输出结果做非线性映射
1.4、 全连接层 / FC layer
这里没什么说的,在全连接层中,神经元对于前一层中的所有激活数据是全部连接的,这个常规神经网络中一样。它们的激活可以先用矩阵乘法,再加上偏置。

1.5、 层级排列规律
- INPUT 输入层
- [[CONV -> RELU]*N -> POOL?]*M 多次卷积接一个池化层
- [FC -> RELU]*K 全连接层
- FC 全连接层输出其中
*指的是重复次数,POOL?指的是一个可选的汇聚层。其中N >=0,通常N<=3,M>=0,K>=0,通常K<3
2、应用场景
卷积神经网络因为其对图像的特征提取的特点被广泛应用
- 被用于OCR文字识别领域,最简单的就是mnist手写体识别,本片末尾我将根据上篇神经网络为例,使用卷积神经网络重新建立模型进行手写体识别
- 图片分类:Alex Krizhevsky等人2012年的文章“ImageNet classification with deep convolutional neural networks”对ImageNet的一个子数据集进行了分类。ImageNet一共包含1500万张有标记的高分辨率图像,包含22,000个种类。这些图像是从网络上搜集的并且由人工进行标记。从2010年开始,有一个ImageNet的图像识别竞赛叫做ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)。 ILSVRC使用了ImageNet中的1000种图像,每一种大约包含1000个图像。总共有120万张训练图像,5万张验证图像(validation images)和15万张测试图像(testing images)。
- 文本分类:卷积神经网络不仅可以识别图像,因为其独特的网络结构使得他也可以被应用于文本分类
- AlphaGo:DeepMind所研究的AlphaGo使用了卷积神经网络来学习人类下棋的方法,最终取得了突破。AlphaGo在没有任何让子的情况下以5:0完胜欧洲冠军,职业围棋二段樊麾。研究者也让AlphaGo和其他的围棋AI进行了较量,在总计495局中只输了一局,胜率是99.8%。它甚至尝试了让4子对阵Crazy Stone,Zen和Pachi三个先进的AI,胜率分别是77%,86%和99%。
3、代码实现
仍然使用mnist手写体作为例子(tensorflow官网同款,因为只是讲解原理所以找的例子没有很复杂),因为是图片识别,使用CNN后对图片识别的准确率会上升,优于传统的神经网络。
卷积神经网络发展至今已经产生了很多nb的研究成果(VGG、盗梦空间、ResNEt等),我会在接下来的博客中介绍,同时也会使用CNN做一个有趣的应用。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("input_data/", one_hot=True)
# 定义超参数
learning_rate = 1e-4
epochs = 3000
batch_size = 50
input_size = 784
class_num = 10
dropout = 0.25
weights = {
# 5x5 卷积 1 输入, 32 输出
'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])),
# 5x5 卷积, 32 输入, 64 输出
'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])),
# 全连接, 7*7*64 输入, 1024 输出
'wd1': tf.Variable(tf.random_normal([7*7*128, 1024])),
# 1024 输入, 10 输出
'out': tf.Variable(tf.random_normal([1024, class_num]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([64])),
'bc2': tf.Variable(tf.random_normal([128])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([class_num]))
}
# 定义卷积操作
def conv2d(x, W, b, strides=1):
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x,b)
return tf.nn.relu(x)
# 定义池化下采样操作
def max_pooling2d(x, k=2):
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')
# 卷积网络
def conv_basic(input):
x = tf.reshape(input, shape=[-1, 28, 28, 1])
conv_1 = conv2d(x, weights['wc1'], biases['bc1'])
conv_1 = max_pooling2d(conv_1, k=2)
conv_2 = conv2d(conv_1, weights['wc2'], biases['bc2'])
conv_2 = max_pooling2d(conv_2, k=2)
dense = tf.reshape(conv_2, shape=[-1, weights['wd1'].get_shape().as_list()[0]])
fc_1 = tf.nn.relu(tf.add(tf.matmul(dense, weights['wd1']), biases['bd1']))
fc_1 = tf.nn.dropout(fc_1, dropout)
out = tf.add(tf.matmul(fc_1, weights['out']), biases['out'])
out = tf.nn.softmax(out)
return out
# 定义输入占位符
X = tf.placeholder(tf.float32, shape=[None, input_size])
Y = tf.placeholder(tf.float32, shape=[None, class_num])
keep_prob = tf.placeholder(tf.float32)
logits = conv_basic(X)
pred = tf.nn.softmax(logits)
loss = -tf.reduce_sum(Y*tf.log(pred))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
saver = tf.train.Saver()
for epoch in range(1, epochs+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.5})
if epoch % 100 == 0 or epoch == 1:
train_accuracy = sess.run(accuracy, feed_dict={X: batch_x, Y: batch_y, keep_prob: 1.0})
print("step {} training accuracy {}".format(epoch, train_accuracy))
saver.save(sess, "./model/cnn_mnist.ckpt")
print("训练结束!")