卷积神经网络(Convolutional Neural Network, CNN)简介
卷积神经网络,听起来像是计算机科学、生物学和数学的诡异组合,但它们已经成为计算机视觉领域中最具影响力的革新的一部分。神经网络在 2012 年崭露头角,Alex Krizhevsky 凭借它们赢得了那一年的 ImageNet 挑战赛(大体上相当于计算机视觉的年度奥林匹克),他把分类误差记录从 26% 降到了 15%,在当时震惊了世界。自那之后,大量公司开始将深度学习用作服务的核心。Facebook 将神经网络用于自动标注算法、谷歌将它用于图片搜索、亚马逊将它用于商品推荐、Pinterest 将它用于个性化主页推送、Instagram 将它用于搜索架构。CNNs目前在很多很多研究领域取得了巨大的成功,例如: 语音识别,图像识别,图像分割,自然语言处理等。虽然这些领域中解决的问题并不相同,但是这些应用方法都可以被归纳为:CNNs可以自动从(通常是大规模)数据中学习特征,并把结果向同类型未知数据泛化。

卷积神经网络(CNN)与传统神经网络(ANN)的区别
ANN是一种深度学习模型,由于数据量的膨胀式发展以及芯片计算能力的提升,在近些年大放异彩。卷积神经网络是传统神经网络的一种,它包含了至少一层卷积层,他们能够很好的捕捉到数据的局部信息。相比于传统神经网络,CNN有很大不同。首先,CNN将一维的神经元变为了二维的卷积核。对于股票数据来说,传统神经网络将某只股票时间截面上的因子变为一维数据输入,下期的超额收益作为输出值;而CNN输入的数据是二维的,横向是因子在时间截面上的数据,纵向是因子的时间序列,这样将数据变为二维矩阵进行输入;其次,CNN将二维数据进行卷积层处理后采用了一种称之为pooling的降采样的做法,降低了数据的复杂程度;最后,CNN采用了稀疏交互和权值共享的做法,这些我们在接下来的章节中会详细讲到。
卷积神经网络
卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
如图x所示,卷积神经网络通常包含以下几种层:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
Drop out, 通常我们在训练Covnets时,会随机的丢弃一部分训练获得的参数,这样可以在一定程度上来防止过度拟合
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
CNN运算原理详解
卷积层的卷积运算是整个卷积神经网络的灵魂,在介绍卷积运算之前,首先需要了解卷积核的概念。相比于传统神经网络,卷积核类似于神经元,如图x所示,它是一个二维的矩阵,卷积核与输入的二维数据经过卷积运算后得到输出的结果。在传统神经网络当中,假设输入数据维度为1*1000,那么需要的1000个神经元,加入有1000份这样的数据,那个需要的神经元也变成了1000
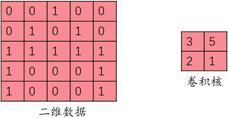
如图2所示,假设55输入数据与22卷积核进行卷积运算,卷积核会在输入数据上取出一块22大小的数据(怎么取的在接下来内容中会讲到),假设取出的数据为[[0, 0], [0, 1]],将取出的数据与卷积核相对应的元素两两相乘后累加得到一次运算的结果:03+05+20+1*1=1,将得到的1填入到输入矩阵相对应的位置当中。
如图x为在股票当中的做法:其中输入的数据横轴为每个因子的时间序列,这里每个矩阵取5个月的时间序列,10个因子截面作为纵轴数据,使用的卷积核为2*2,每个卷积核有一个bias,计算方法如图x所示,我们再把得到的结果填入到图中卷积结果的灰色区域。

上面的步骤只包含了一次运算,卷积运算需要将二维数据上的所有数据都运算一遍,这里需要讲到步长(stride)的概念,如果步长为(x,y),这代表了卷积核在横轴上面每次移动x个各子,在纵轴上面移动y个格子。如图x所示,代表了卷积核分别在x轴和y轴上步进一个格子进行卷积运算的结果。

在实际操作过程中输入的数据矩阵卷积核步长映射的过程当中会发生个数不匹配的情况,比如55的输入矩阵用22的卷积核来运算的时候,如果步长取(1,2)的话,那个横轴只能取四次卷积运算,将会多出一行;在纵轴只能取两次卷积运算,也会多出一行无法运算,这样的结果是边缘信息可能缺失。所以深度学习当中也对这种情况进行了不同的处理,这种处理方法叫做Padding。在谷歌深度学习框架tensorflow中,Padding的方式也有“VALID”和“SAME”两种,其中“SAME”是在二维数据的四周进行补零,使得经过卷积运算之后得到的输出矩阵还是和输入矩阵相同的维度。“VALID”的做法是不进行任何补偿,直接舍去边缘信息,在上面的例子当中便是直接舍去最后一行和最后一列。

在图像处理中Padding的方法一般选择“SAME“,而在股票收益预测当中,使用” SAME “的方法进行补零对我们的预测结果会产生不必要的噪声,造成预测结果的不准确,所以我们的做法是直接舍去边缘的数据,采用的方法是”VALID“。如图x所示,105的股票输入数据进行”VALID“方式的卷积运算后得到输出数据的维度为94.
如果只有一个卷积核的话,那么得到的数据量是有限的,一个105的输入数据最后得到94的输出数据,大量的信息可能都丢失掉了,所以卷积核都会有很多个,每个都是完全不同的卷积核,假如我们有n个卷积核,那个我们最后得到的结果就会有n和9*4的输出矩阵,这些矩阵包含的信息各不相同,差异化也让我们能够得到更多未知的有用信息。
可以看到,卷积运算的过程都是线性过程,但是线性运算的表达效果很有限,大部分的规律性东西都是非线性的,为了提高模型的泛化能力,我们需要将数据进行进一步的处理,需要引入非线性的运算,激活函数便产生了用武之地。常见的激活函数有sigmod、tanh和ReLU,ReLU函数因为运算简单、能够很好的解决梯度消失、将负样例剔除提高模型泛化能力等特点得到广泛应用。在卷积神经网络激活函数的选择中,也都将ReLU作为首选。
ReLU激活函数的运算公式为:y = max(0, x); 也就是卷积运算之后得到的输出矩阵中我们将所有的负值都设置为0,将所有的正值都保留原值得到激活函数之后的结果。