什么是卷积神经网络
- 卷积神经网络的历史就不多阐述了,它的灵感来源于对生物的视觉系统的研究,卷积神经网络是受生物学上感受野的机制而提出的,感受野(receptive field)主要是指听觉、视觉等神经系统中一些神经元的特性,即神经元只接受其所支配的刺激区域内的信号。一个神经元的感受野是指视网膜上的特定区域,只有区域内的刺激才会激活该神经元。
- 目前卷积神经网络一般由卷积层、汇聚层和全连接层交叉堆叠而成,利用反向传播算法进行训练。卷积神经网络有三个特性:局部连接、权重共享以及子采样,这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性,这也符合人的视觉特点,和前馈神经网络相比,其参数更少。
- 卷积神经网络(CNN) 属于人工神经网络的一种,它的权重共享的网络结构显著降低了模型的复杂度,减少了权值的数量。卷积神经网络可以直接将图片作为网络的输入,自动提取特征,并且对图片的变形(如平移、比例缩放、倾斜)等具有高度不变形。
- 卷积神经网络(Convolutional Neural Networks,CNN),CNN可以有效的降低 反馈神经网络(传统神经网络)的复杂性,常见的CNN结构有LeNet-5、AlexNet、 ZFNet、VGGNet、GoogleNet、ResNet等等,CNN的应用主要是在图像分类和物体识别等应用场景应用比较多
卷积网络的发展
LeNet:(最早用于数字识别的CNN
)
- 广为流传LeNet诞生于1998年,网络结构比较完整,包括卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。被认为是CNN的开端。
AlexNet:(2012年ILSVRC比赛冠军,远超第二名的CNN,比LeNet更深,用多层 小卷积叠加来替换单个的大卷积)
- 2012年Geoffrey和他学生Alex在ImageNet的竞赛中,刷新了image classification的记录,一举奠定了deep learning 在计算机视觉中的地位。这次竞赛中Alex所用的结构就被称为作为AlexNet。
对比LeNet,AlexNet加入了:
(1)非线性激活函数:ReLU;
(2)防止过拟合的方法:Dropout,Data augmentation。同时,使用多个GPU,LRN归一化层。其主要的优势有:网络扩大(5个卷积层+3个全连接层+1个softmax层);解决过拟合问题(dropout,data augmentation,LRN);多GPU加速计算。
ZFnet:(2013ILSVRC冠军)
- ZFNet 是由 Matthew D.Zeiler 和 Rob Fergus 在 AlexNet 基础上提出的大型卷积网络,在 2013 年 ILSVRC 图像分类竞赛中以 11.19% 的错误率获得冠军。ZFNet 实际上并不是 ILSVLC 2013 的赢家。相反,当时刚刚成立的初创公司 Clarifai 是 ILSVLC 2013 图像分类的赢家。又刚刚好 Zeiler 是 Clarifai 的创始人兼首席执行官,而 Clarifai 对 ZFNet 的改动较小,故认为 ZFNet 是当年的冠军
VGG-Net:(2014ILSVRC比赛中算法模型,效果率低于GoogleNet)
- VGG-Net来自 Andrew Zisserman 教授的组 (Oxford),在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名,其不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。同时,VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
GoogLeNet:(2014ILSVRC冠军)
- 提出的Inception结构是主要的创新点,这是(Network In Network)的结构,即原来的结点也是一个网络。其使用使得之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
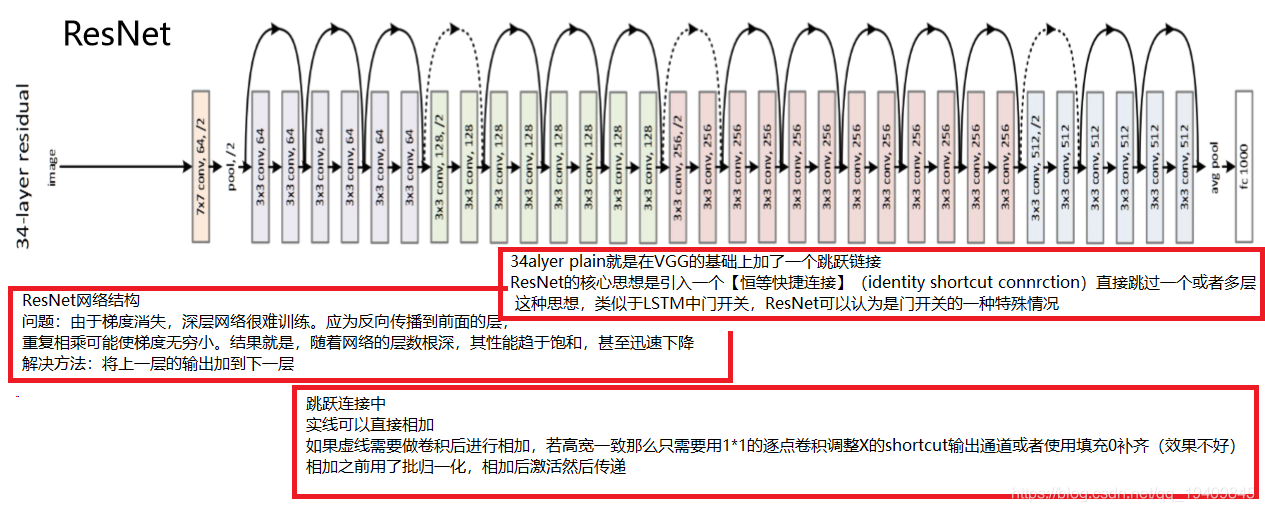
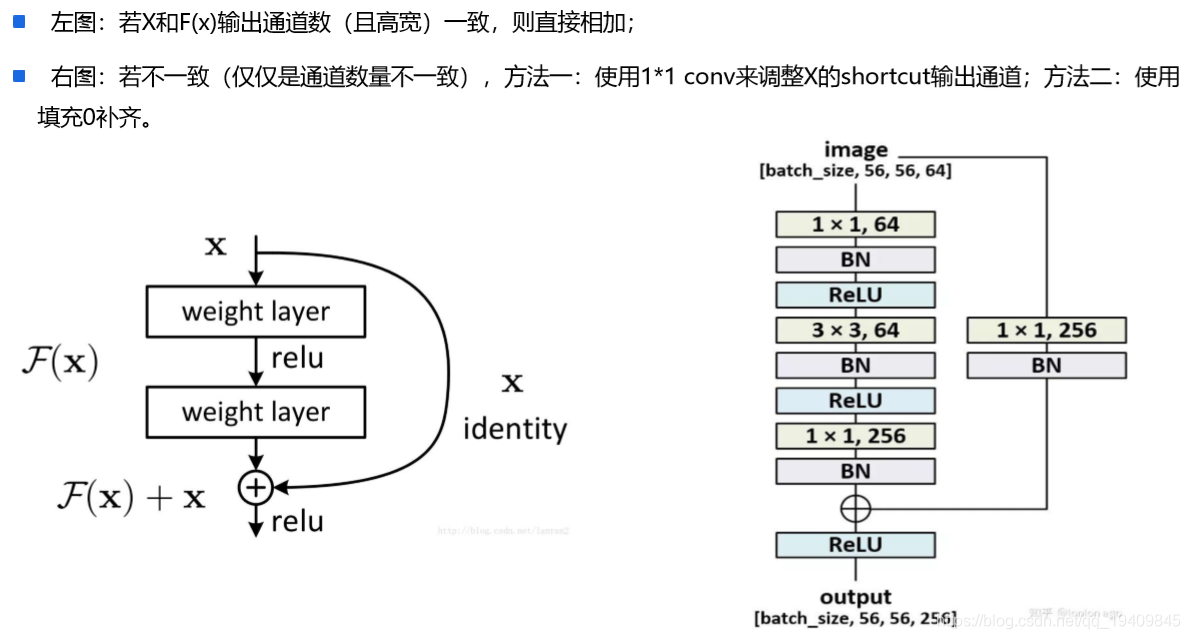
Resnet:(2015ILSVRC冠军,结构修正以适应更深层次的CNN训练 )
- ResNet提出了一种减轻网络训练负担的残差学习框架,这种网络比以前使用过的网络本质上层次更深。其明确地将这层作为输入层相关的学习残差函数,而不是学习未知的函数。在ImageNet数据集用152 层(据说层数已经超过1000==)——比VGG网络深8倍的深度来评估残差网络,但它仍具有较低的复杂度。在2015年大规模视觉识别挑战赛分类任务中赢得了第一。
卷积神经网络
主要层次结构
数据输入层:Input Layer
作用:卷积网络的原始输入,可以是原始或预处理后的像素矩
- 需要把图片处理成同样大小的图片才能够进行处理。
- 对于输入的数据需要做预处理,原因如下:
-
输入数据单位不一样,可能会导致神经网络收敛速度慢,训练时间长
-
数据范围大(方差大)的输入在模式分类中的作用可能偏大,而数据范围小的作用就有可 能偏小
-
由于神经网络中存在的激活函数是有值域限制的,因此需要将网络训练的目标数据映射到 激活函数的值域
-
S形激活函数在(-4, 4)区间以外区域很平缓,区分度太小。例如S形函数f(X),f(100)与f(5) 只相差0.0067
-
预处理方式:
在数据预处理的时候一般都采用去均值和者归一化比较多!!!-
去均值:将输入数据的各个维度中心化到0
-
归一化:将输入数据的各个维度的幅度归一化到同样的范围

-
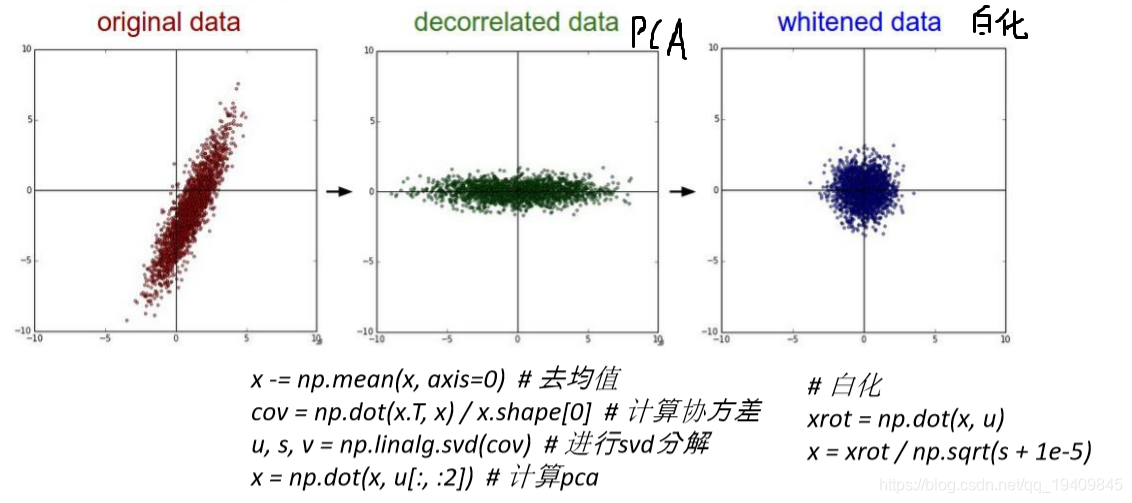
PCA/白化
- 用PCA降维(去掉特征与特征之间的相关性)
- 白化是在PCA的基础上,对转换后的数据每个特征轴上的幅度进行归一化
-
-
卷积计算层:CONV Layer
作用:参数共享、局部连接,利用平移不变性从全局特征图提取局部特征
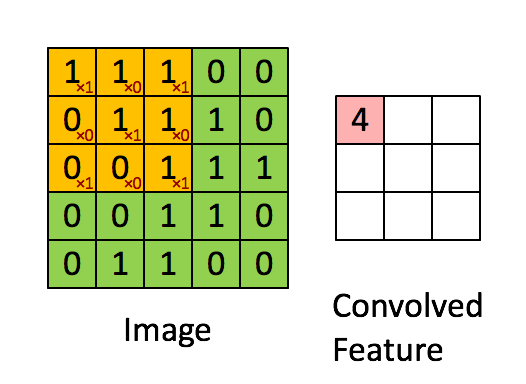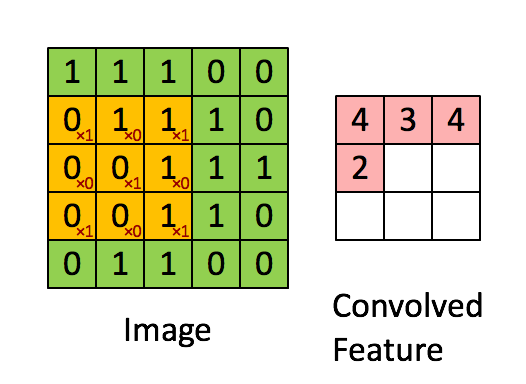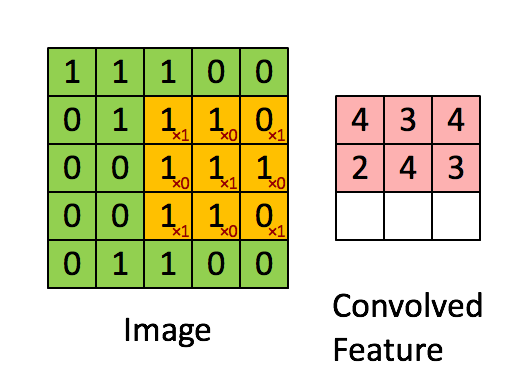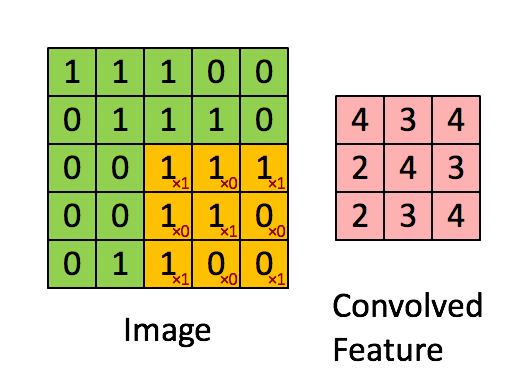
卷积就是通过卷积核(滤波器)来提取高阶特征!!!
-
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
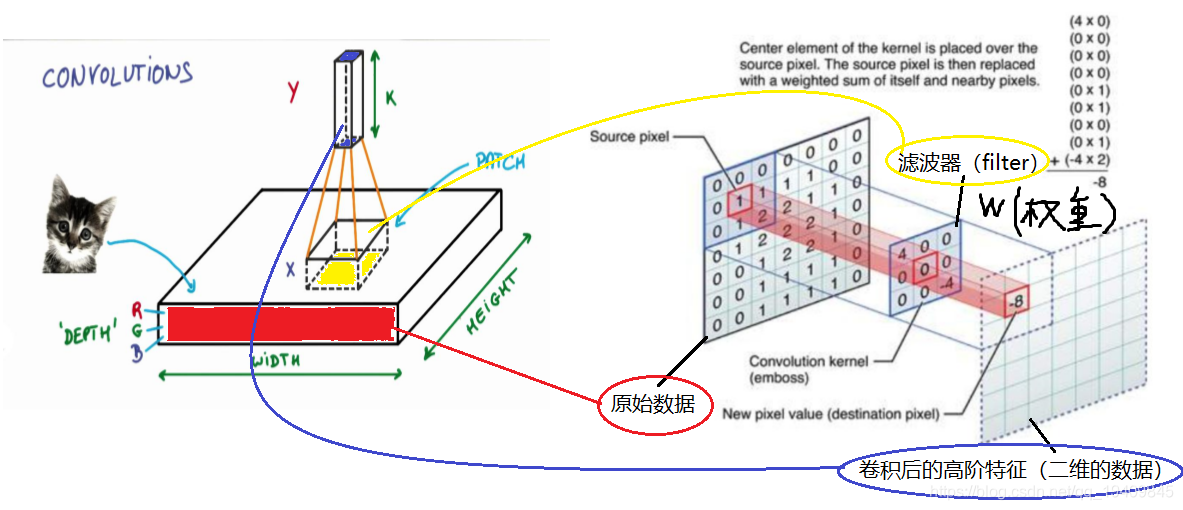
不同大小的滤波器提取不同的特征(颜色深浅,轮廓大小)

-
卷积计算层:
-
局部关联:每个神经元看做一个filter/kernel
-
窗口(receptive field)滑动,filter对局部数据进行计算
-
相关概念
- 输入特征图的深度: depth == channel
- 卷积核大小(滤波器): kernel size
- 输出深度==卷积核个数 (神经元个数,决定输出的depth厚度。同时代表滤波器个数。)
- 步幅:stride决定滑动多少步可以到边缘。(取值:1 2 4 )
- 填充值:zero-padding (在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。)
- 填充方式:same 或者 valid
“SAME”:不填充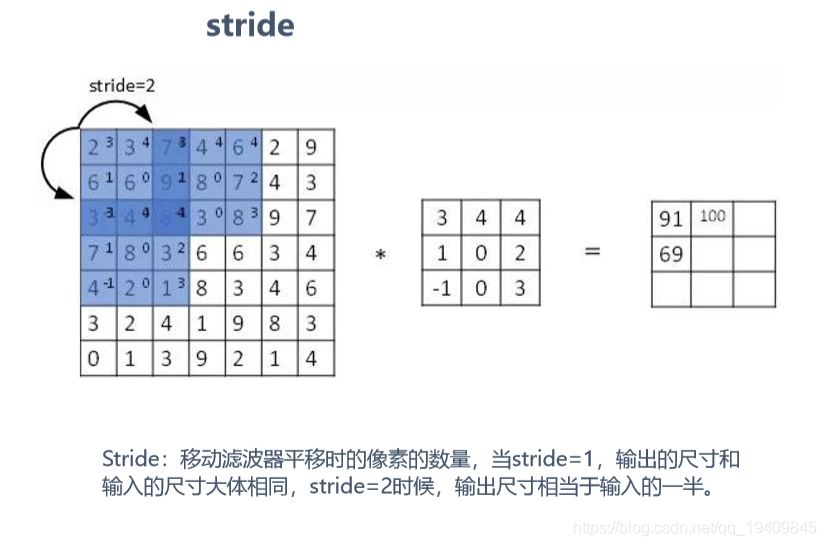
“VALID”:首先尝试两边均匀填充(如果没法平分,就将平分之后剩余的填充在右边或下面)
-
卷积过程如图:
一 组 固 定 的 权 重 和 窗 口 内 数 据 做 矩 阵 内 积 后 求 和 的 过 程 叫 做 卷 积
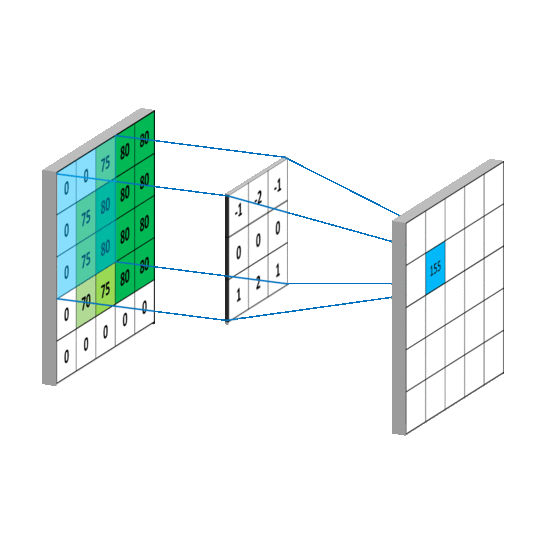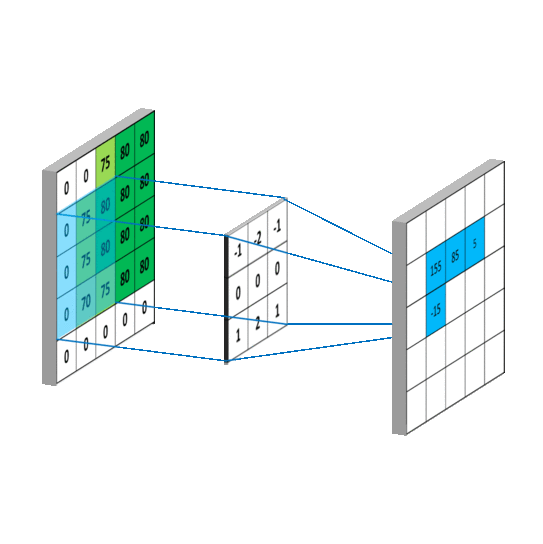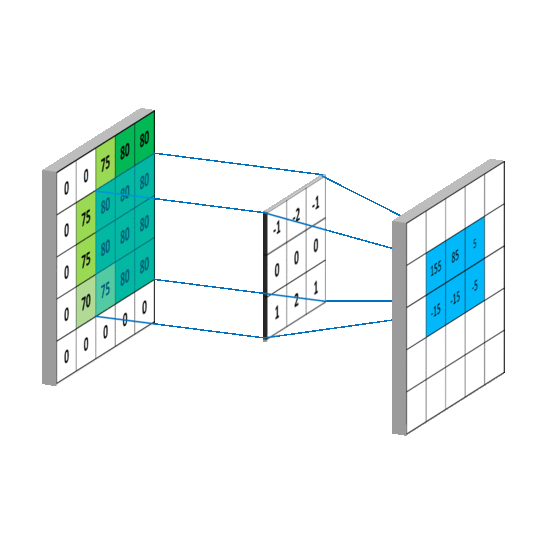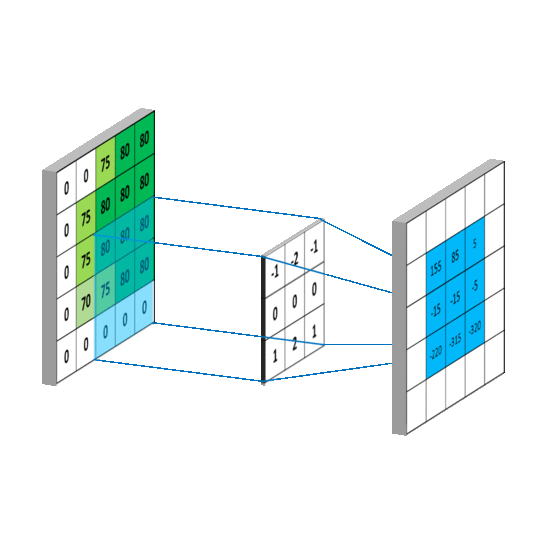
-
-
局部感知: 在进行计算的时候,将图片划分为一个个的区域进行计算/考虑;
-
参数共享机制:假设每个神经元连接数据窗的权重是固定的
-
滑动窗口重叠:降低窗口与窗口之间的边缘不平滑的特性。
-
固定每个神经元的连接权重,可以将神经元看成一个模板;也就是每个神经元只 关注一个特性
-
需要计算的权重个数会大大的减少
-
卷积shape的计算方式:

ReLU激励层:ReLU Incentive Layer
作用:将卷积层的输出结果进行非线性映射
将卷积层的输出结果做一次非线性的映射,也就是做一次‘’激活‘’。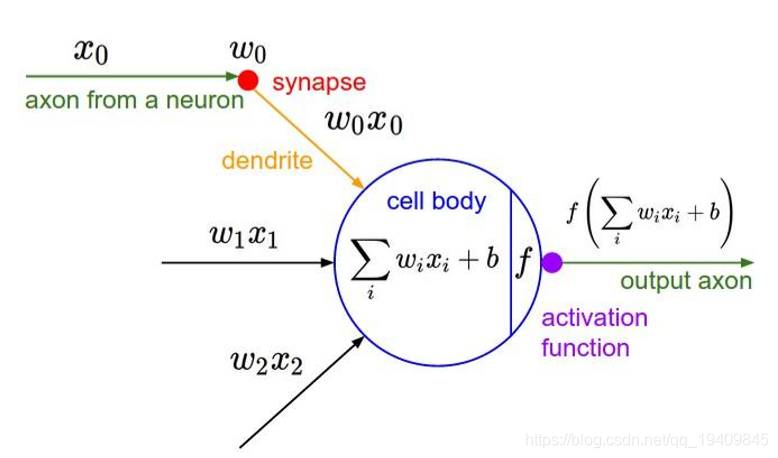
激活函数是将输出结果做非线性映射,为了使模型获得非线性的能力
-
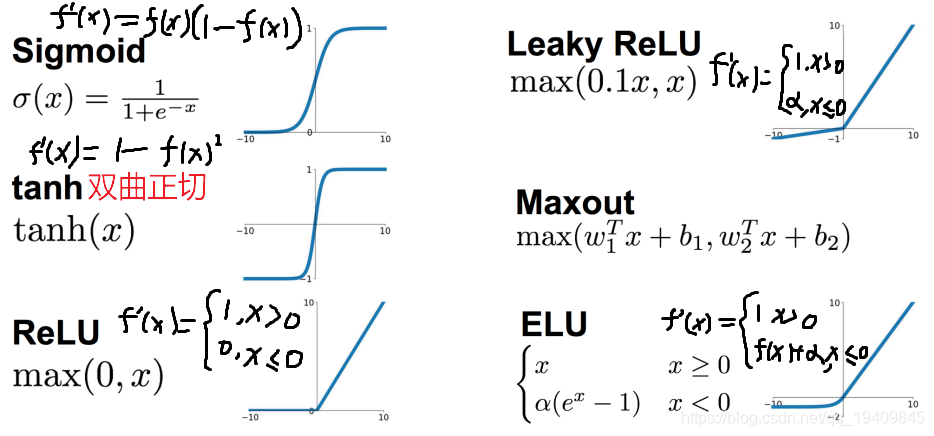
sigmoid函数:
- 优点:
- 取值范围(0~1)、简单、容易理解
- 缺点:
- 容易饱和和终止梯度传递(“死神经元”);
- sigmoid函数的输出没有0中心化。
- 优点:
-
tanh函数:
- 优点:取值范围(-1~1)、易理解、0中心化
- 缺点: 容易饱和和终止梯度传递(“死神经元”)。
-
ReLu函数:修正线性单元,有可能出现斜率为0,但概率很小,因为mini-batch是一批样本损失求导之和。
- 缺点: 没有边界,可以使用变种ReLU6: min(max(0,x), 6) 比较脆弱,比较容易陷入出现”死神经元”的情况
- 优点: 相比于Sigmoid和Tanh,提升收敛速度 梯度求解公式简单,不会产生梯度消失和梯度爆炸
-
Leaky ReLU激活函数:
- 在ReLU函数的基础上,对x≤0的部分进行修正;
- 目的是为了解决ReLU激活函数中容 易存在的”死神经元”情况的;不过实际场景中:效果不是太好。
-
ELU激活函数:
- 指数线性激活函数,同样属于对ReLU激活函数的x≤0部分的转换进行指数修正,而 不是和Leaky ReLU中的线性修正。
激活函数建议:CNN隐藏层一般不使用sigmoid(排除做attention用),如果要使用,建议只在全连接层使用。首先使用ReLU,因为迭代速度快,但是有可能效果不佳。如果使用ReLU失效的情况下,考虑使用Leaky ReLu或者ELU,此时一般情况都可以解决。tanh激活函数在某些情况下有比较好的效果,但是应用场景比较少
池化层:Pooling Layer
作用:进一步筛选特征,可以有效减少后续网络层次所需的参数量
也叫下采样层,就算通过了卷积层,维度还是很高 ,需要进行池化层操作。
在池化层中,可以获得更大视野特征图。但又无需增加参数量(比如通过7*7获得同样特征图)
- 主要功能是:
- 通过逐步减小表征的空间 尺寸来减小参数量和网络中的计算;
- 池化层在每个特征图上独立操作。
- 使用池化 层替代卷积层可以达到压缩数据和参数的量,减小过拟合
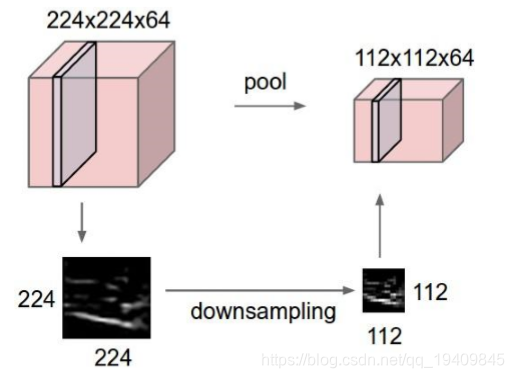
方式有:Max pooling、average pooling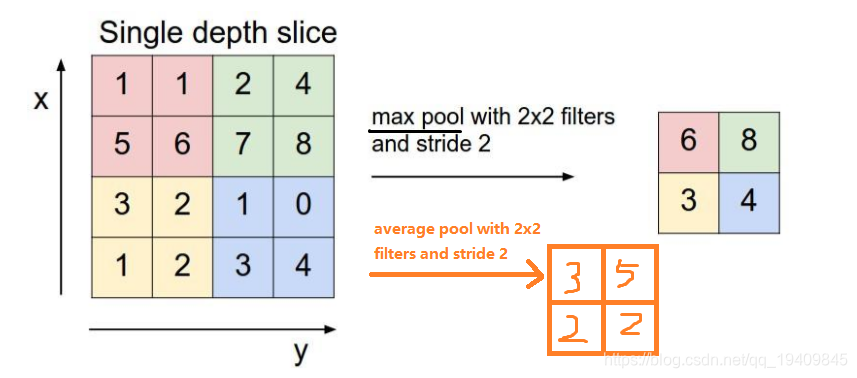
最大池化Max pooling,3,4
- 取出每个部分的最大值作为输出,例如上图左上角的4个粉色方块取最大值为6作为输出,以此类推(8,3,4)。
平均池化:average pooling
- 每个部分进行计算得到平均值作为输出,例如上图左上角的4个粉色方块取得平均值3作为输出,以此类推(5,2,2)。
全连接层:FC Layer
作用:用于把该层之前提取到的特征综合起来。
- 类似传统神经网络中的结构,FC层中的神经元连接着之前层次的所有激活输出; 换一句话来讲的话,就是两层之间所有神经元都有权重连接;通常情况下,在 CNN中,FC层只会在尾部出现
备注:Batch Normalization Layer(可能有)
- Batch Normalization Layer(BN Layer)是期望我们的结果是服从高斯分布的, 所以对神经元的输出进行一下修正,一般放到卷积层/FC层后,池化层前。
- 在模型训练的时候,由于模型参数在发生更新,那么除了输入层 的数据之外,后面网络的每一层的输入数据分布都是一直在发生 变化的。网络中间层的训练过程中,数据分布的改变被称为 ‘内部协方差偏移(Internal Covariate Shift)’。而BN的提出就是为了解决在训练过程中,中间层数据分布发生改变的情况。
批归一化计算方式
强制的进行归一化操作可能存在一些问题,eg: 方差为1等
 若仅做归一化,而不重新缩放和位移(BN),则模型会不学习。
若仅做归一化,而不重新缩放和位移(BN),则模型会不学习。
如Sigmoid激活函数。这个函数在-1~1之间的梯度变化不大,可以近视为线性函数,如下图: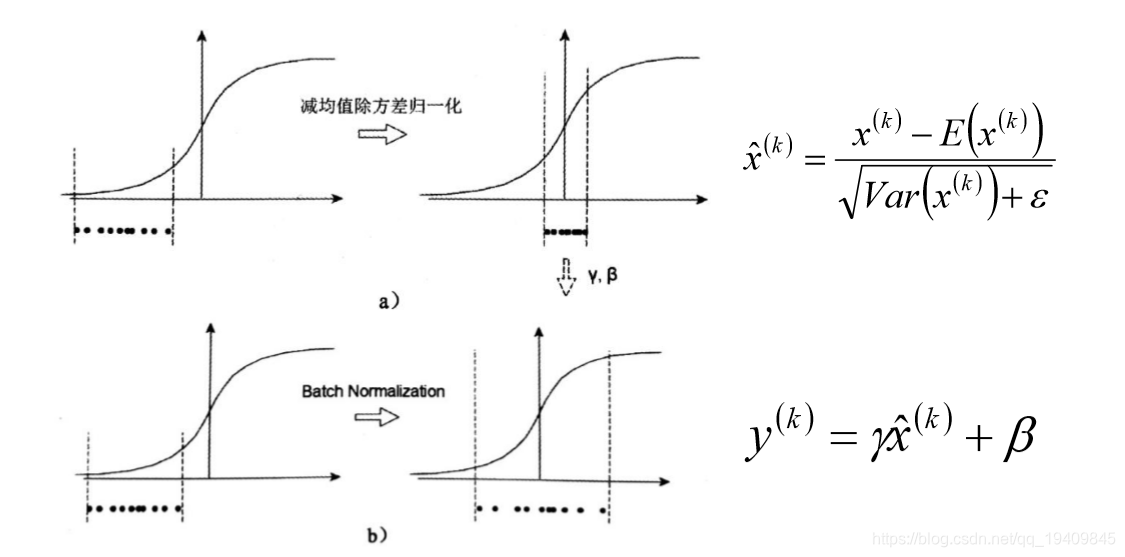
Tanh函数在0附近也近视线性函数。 所以需要转换才能将分布从0移开, 使用缩放因子γ和移位因子β(学习的参数)来执行此操作,如下图:
批归一化BN的原理是平滑了损失函数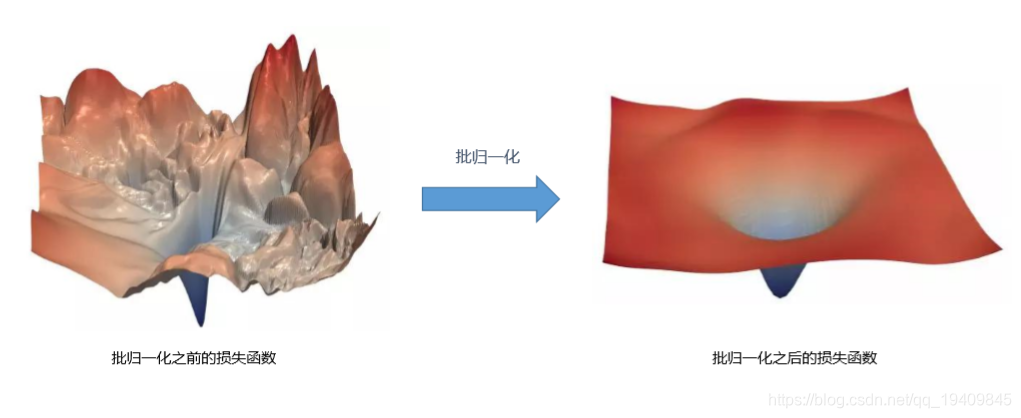
批归一化的作用
- 网络训练更快 – 神经网络每一次迭代都会做大量的计算(正向和反向,以及调整超参数),导致很慢。如果能够更 快的收敛,那么整体训练速度自然要快很多。
- 允许更大的学习率 – 梯度下降算法要求使用非常小的学习率,网络才能收敛。网络越深,反向传播的梯度也会越小, 就需要更多的迭代来学习。批归一化允许我们使用相对来说大一些的学习率,可以加速网络训练。
- 权重初始化更容易 – 权重初始化是很难的,特别是当网络越来越来深。批归一化允许我们不用过分关心权重初始化 的值。 - 使激活函数有更多选择 – 部分激活函数有使用条件限定。Sigmoids不能用于深度网络中,因其丢失梯度过高。 ReLUs经常会梯度消失而导致网络完全停止学习,所以非常小心值域范围(读入激活函数的)。但批归一化对任何进入 激活函数的值都做了规范,所以之前在深度网络中表现不好的非线性函数也可以作为备选项了。
- 创建深度网络更简单 – 基于1-4原因,使用批归一化创建并训练深度网络更简单。当然网络越深,一般而言,效果 越好。
- 提供了一些正则化作用 – 批归一化是在网络中增加了一些噪音。实际起了一定的dropout功能,所以在使用了批归 一化网络中,可以考虑减少dropout的使用。
- 总之,让网络效果更佳 – 有一些测试表明批归一化能够改进网络效果。BN是优化网络速度的手段, 而不是提升网络精度的方法。显然,若你可以训练的更快,意味着你可以尝试更多网络设计方案,迭代 更多次,也可以构建更深的网络(效果更佳)。最终你通过批归一化达到提升网络效果。
优点or缺点
- 优点:
- 梯度传递(计算)更加顺畅,不容易导致神经元饱和(防止梯度消失(梯度弥 散)/梯度爆炸)
- 学习率可以设置的大一点
- 对于初始值的依赖减少
- 缺点:
- 如果网络层次比较深,加BN层的话,可能会导致模型训练速度很慢。
批归一化使用的位置:CNN中在激活函数之前使用,RNN在每层输入之前,最后输出层 都不加。
几种批归一化
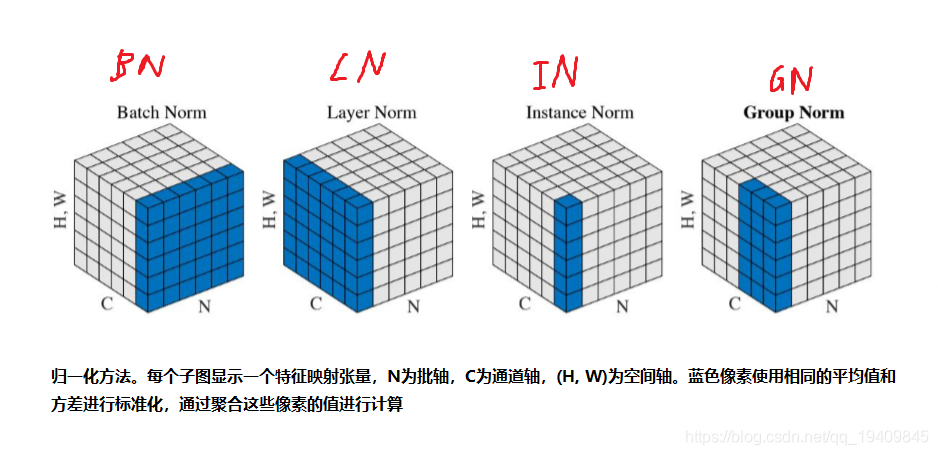
Batch Normalization Layer:
- 在CNN中,由于CNN的特征是对应到一个feature map特征图 上的,所以在CNN中做BN的时候不是以神经元作为单位,而是 以feature map特征图作为单位的。也就是针对一个批次中的一 个channel的所有feature map计算一对参数γ、β。这样可以减 少模型参数的数目
Layer Normalization Layer
- 在Layer Normalization中,是针对不同样本计算当前样本的所有神经元的均 值和方差,也就是说在LN中,同层神经元输入拥有相同的均值和方差,不同的 输入样本具有不同的均值和方差;而在BN中,同层的不同神经元输入的是不同 的均值和方差,而同一个batch中的所有样本拥有相同的方差和均值。
- 主要优点:不受样本批次大小的影响。在RNN上效果比较明显,但是在CNN 上,效果不及BN
Instance Normalization Layer
- 在BN中注重对于每个batch中的数据进行归一化操作,保证数据的一致 性,是因为在判别模型中的结果一般取决于数据整体分布情况。
- 但是在图像风格化中,生成的结果主要依赖于某个图像的实例,所以对 整个batch做归一化不是特别的适合,比较适合对每个feature map特征 图(HW)做归一化操作,能够保证各个图像实例之间的独立。
- 优点:不受样本批次大小影响,保证每个feature map的独立性。
Group Normalization Layer
- 主要针对于BN中对于小batchsize效果差的问题,在GN中将 channel方向分为不同的group,然后每个group中计算归一化 操作,计算(C//G)WH的均值、方差,然后进行归一化操作, 这样计算出来的结果和batchsize没有关系,效果比较不错。
- 优点:对于小batchsize的模型效果也非常不错。
Switchable Normalization Layer
- Switchabel Normalization是针对于BN、LN、IN、GN是完全 人工设计,并且没法通用,每个归一化层的设计需要涉及大量的 实验,工作量比较大,SN的就是为了提出一个自适配归一化方法, 会自动的为神经网络中的每个归一化层确定一个合适的归一化操 作。
- 优点:自适应的归一化层,和业务的耦合性最低。
卷积神经网络优缺点
- 优点
- 共享卷积核(共享参数),对高维数据的处理没有压力
- 无需选择特征属性,只要训练好权重,即可得到特征值
- 深层次的网络抽取图像信息比较丰富,表达效果好
- 不同层次有不同形式与功能。
- 缺点
- 需要调参,需要大量样本,训练迭代次数比较多,最好使用GPU训练
- 黑箱:物理含义不明确,从每层输出中很难看出含义来
参数的初始化?
在卷积神经网络中,可以看到神经元之间的连接是通过权重w以及偏置b实现的。一个好的初始化参数对模型的效果有很大的帮助。
- 权重的初始化
- 一般方式:很小的随机数(对于多层深度神经网络,太小的值会导致回传的梯度非常小),一般随机 数是服从均值为0,方差未知(建议:2/n, n为权重数量,论文地址) 的高斯分布随机数列。
- 错误方式:全部初始化为0,全部设置为0,在反向传播的时候是一样的梯度值,那么这个网络的 权重是没有办法差异化的,也就没有办法学习到东西。
- 偏置项的初始化
- 一般直接设置为0,在存在ReLU激活函数的网络中,也可以考虑设置为一个很小的数字
过拟合问题
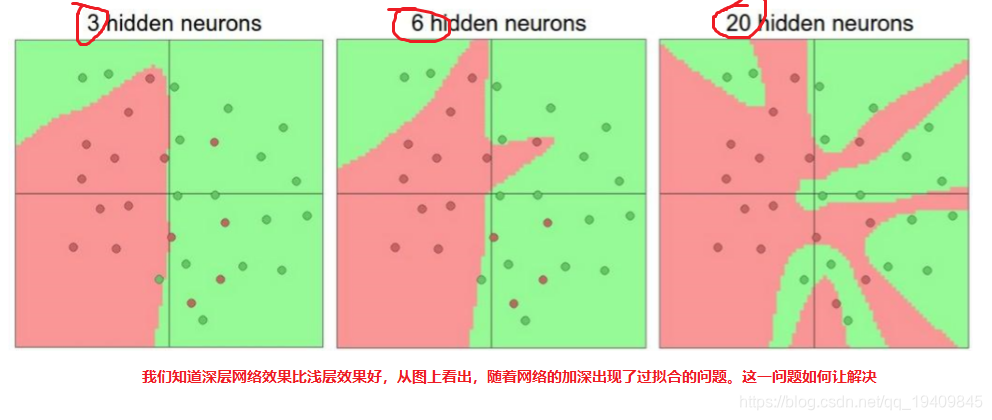
神经网络的学习能力受神经元数目以及神经网络层次的影响,神经元数目越大,神经 网络层次越高,那么神经网络的学习能力越强,那么就有可能出现过拟合的问题;(通 俗来讲:神经网络的空间表达能力变得更紧丰富了)
Regularization:
- 正则化,通过降低模型的复杂度,通过在cost函数上添加一个正 则项的方式来降低overfitting,主要有L1和L2两种方式
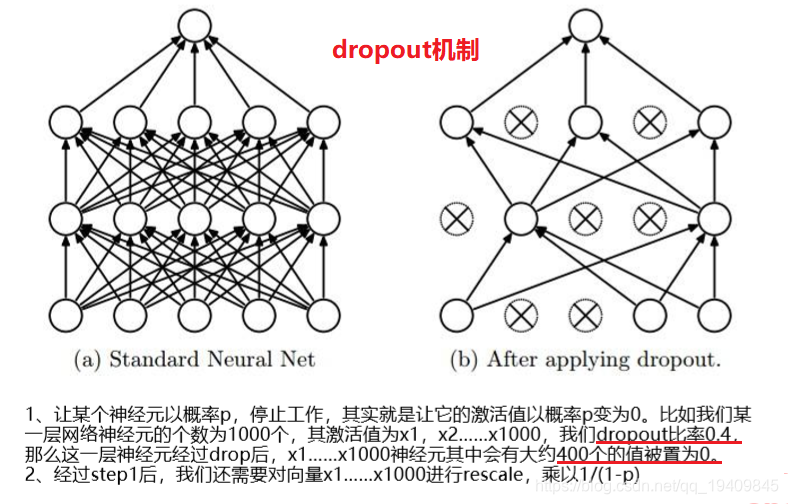
Dropout
- Dropout:通过随机删除神经网络中的神经元来解决overfitting问题,在每次迭代 的时候,只使用部分神经元训练模型获取W和d的值
- 一般情况下,对于同一组训练数据,利用不同的神经网络训练之后,求其输出的 平均值可以减少overfitting。Dropout就是利用这个原理,每次丢掉一半左右的隐 藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依 赖性,即每个神经元不能依赖于某几个其它的神经元(指层与层之间相连接的神经 元),使神经网络更加能学习到与其它神经元之间的更加健壮robust(鲁棒性)的 特征。另外Dropout不仅减少overfitting,还能提高测试集准确率。(训练数据集 有时会降低)
正则化是通过给cost函数添加正则项的方式来解决过拟合,Dropout是通过 直接修改神经网络的结构来解决过拟合
池化的反向传播
传统的神经网络无论是隐层还是激活函数的导数都是可导,可以直接计算出导数函数,然而在CNN网络中存在一些不可导的特殊环节,比如Relu等不可导的激活函数、造成维数变化的池化采样、已经参数共享的卷积环节。NN网络的反向传播本质就是梯度(可能学术中会用残差这个词,本文的梯度可以认为就是残差)传递,所以只要我们搞懂了这些特殊环节的导数计算,那么我们也就理解CNN的反向传播。
Relu函数的导数计算
先从最简单的开始,Relu激活在高等数学上的定义为连续(局部)不可微的函数,它的公式为
其在x=0处是不可微的,但是在深度学习框架的代码中为了解决这个直接将其在x=0处的导数置为1,所以它的导数也就变为了
Pooling池化操作的反向梯度传播
CNN网络中另外一个不可导的环节就是Pooling池化操作,因为Pooling操作使得feature map的尺寸变化,假如做2×2的池化,假设那么第l+1层的feature map有16个梯度,那么第l层就会有64个梯度,这使得梯度无法对位的进行传播下去。其实解决这个问题的思想也很简单,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同的。
平均池化:mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下 :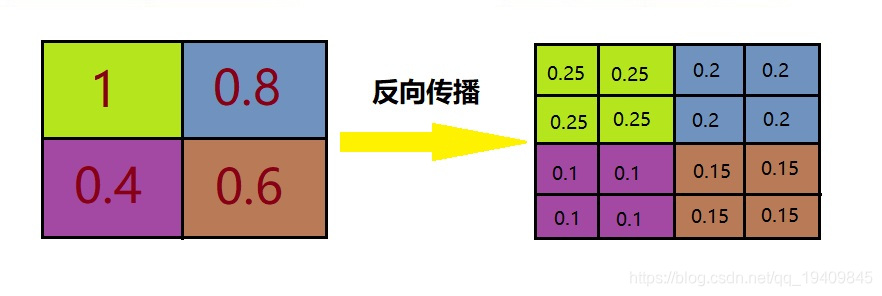
mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
最大池化:max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id。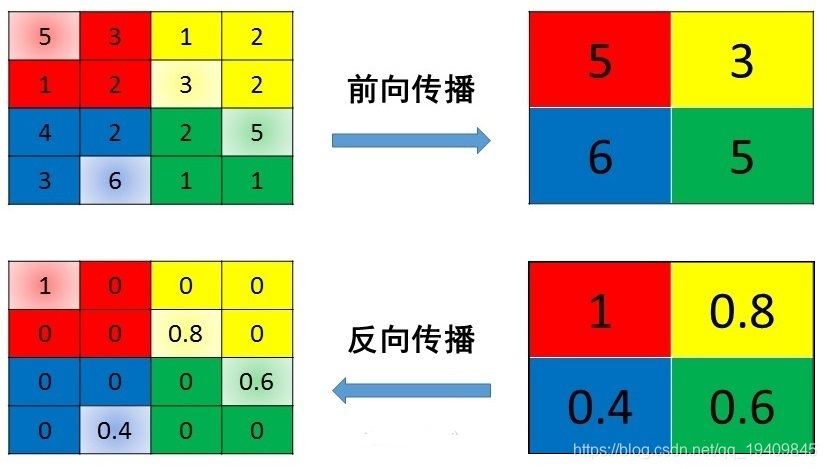
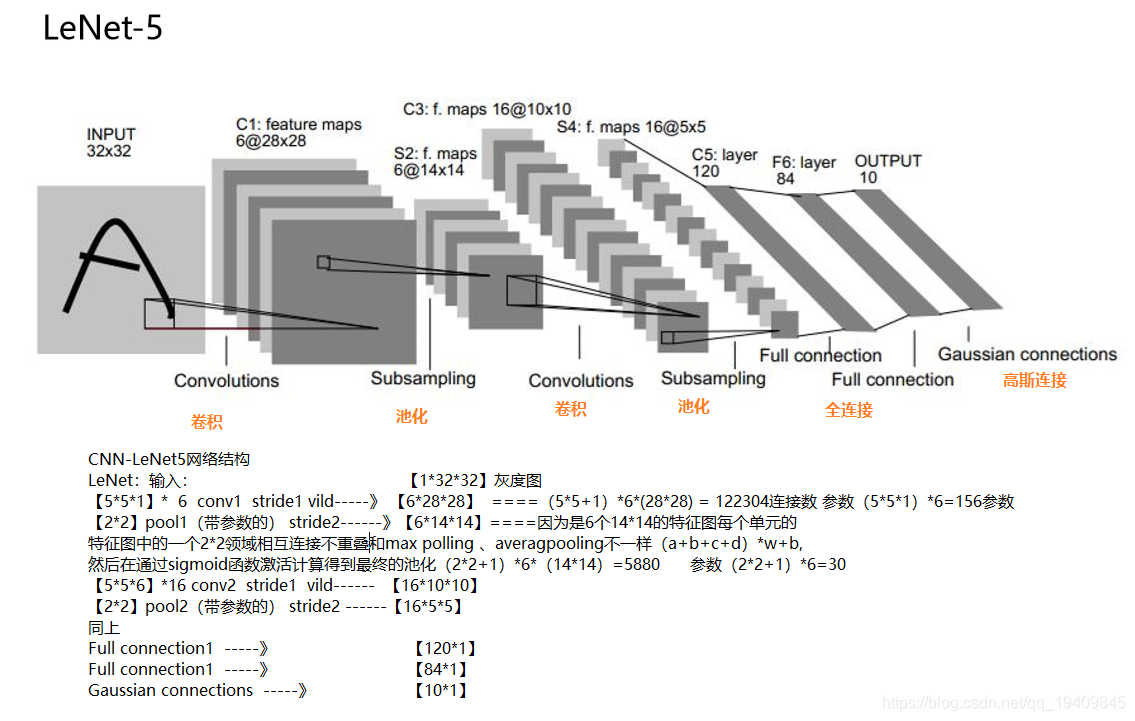
CNN中骨架网络图
LeNet

LeNet-5
AlexNet
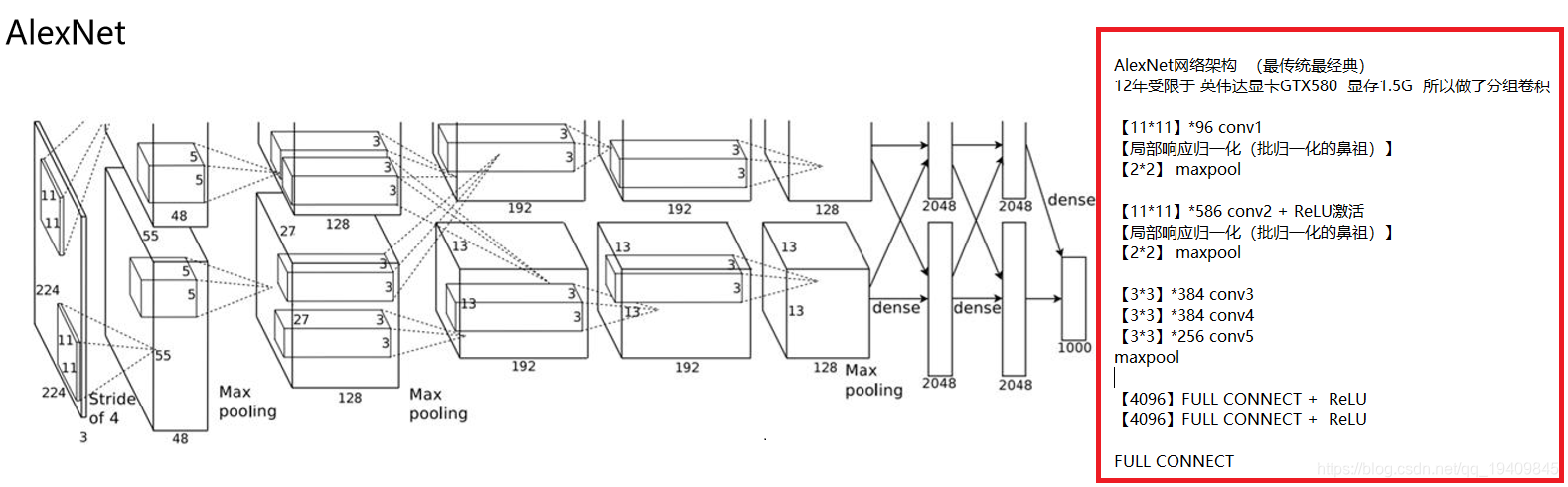
改进:引入了局不响应归一化 (加与不加相差了一个百分点)
结构优化:
修正线性函数ReLU
使用最大池化不带参数 提取丰富的特征
使用Dropout Data augmentation(数据增强)
这是第一个在超大数据集上训练的神经网络
使用了GPU训练,当时受限于GPU 所以做了分组训练
加入了LRN(局不响应归一化)参考了生物学上抑制神经元过于活跃的现象(只做了归一化没有学习参数beta game)
GoogleNet
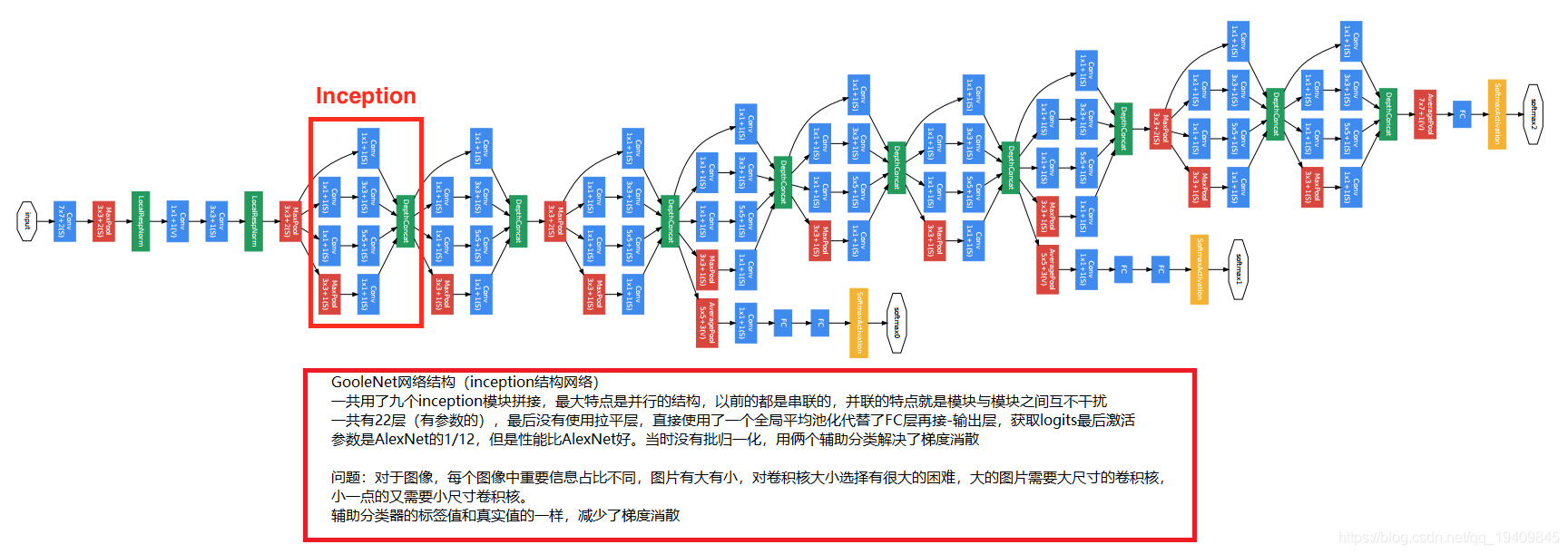
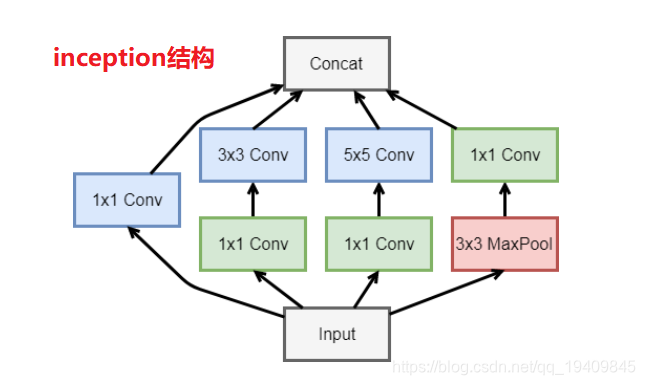
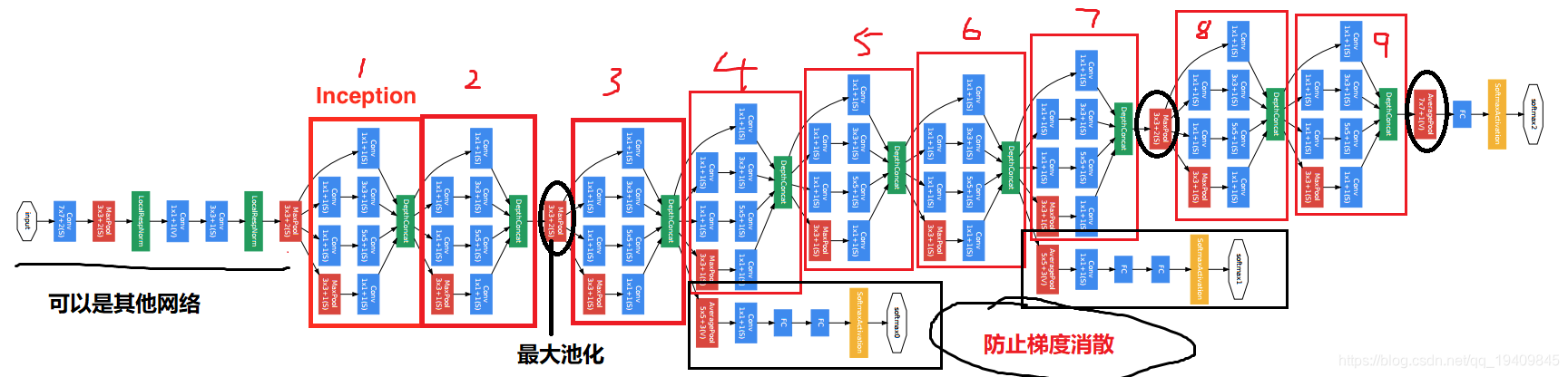
为什么加入辅助分类器(图中黑框):
- 1.因为网络太深,导致在连续链式求导的过程中出现了梯度消散的问题,使模型退化
- 2.因为连续的链式求导,中间有若干个值是小于1的,或在正负1之间,小于1的值在
链式求导的过程中越来越小,最后得到的梯度值趋近于0,导致模型的退化,能力下降
辅助分类器(只在训练的时候使用):
- 1.对模型进行反向传播,帮助模型减少梯度消散
- 2.反向传播时如果给原始标签的话,导致分类器太强,所以认为的加入一些因素,人为的削减,给标签乘上一个0.几的小数(0.3或0.5,由实验结果得到),使反向传播的误差小一点
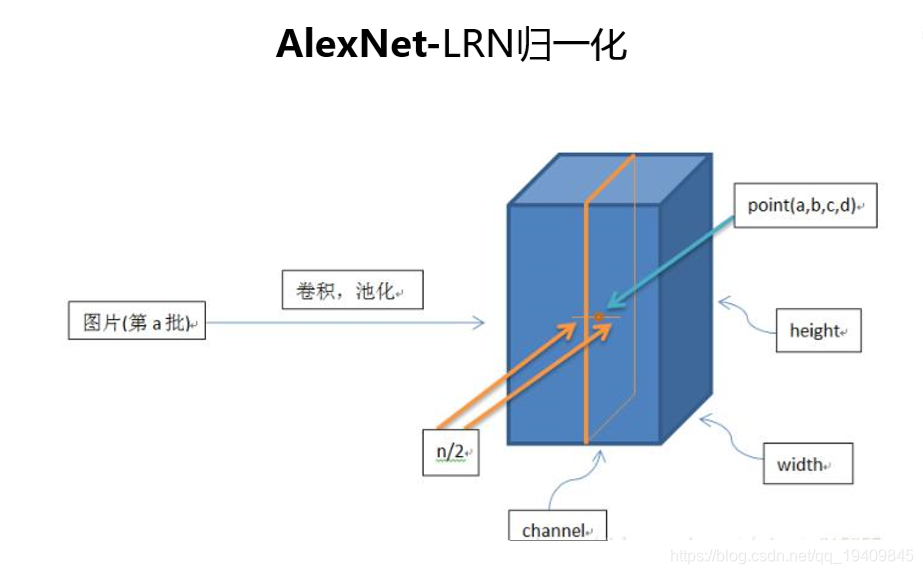
ZF Net
- ZF Net 基于AlexNet进行微调
- 修改窗口大小和步长
- 使用稠密单GPU的网络结构替换AlexNet的稀疏双GPU结构
- Top5错误率11.2%
- 使用ReLU激活函数和交叉熵损失函数
VGG
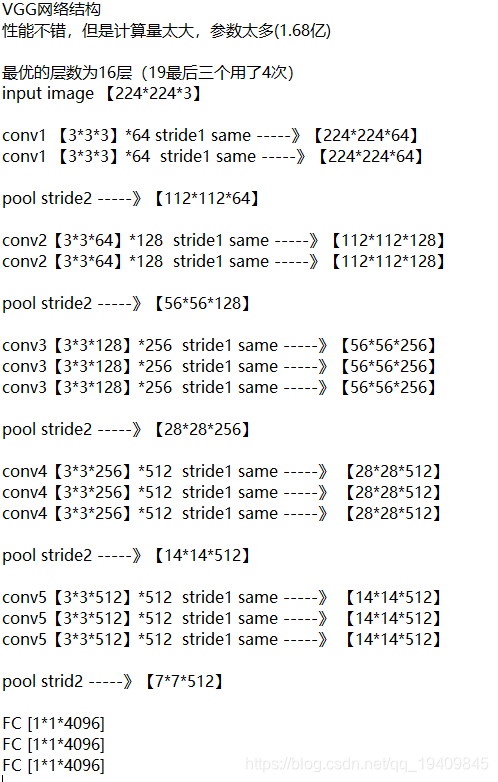
前面参数少 卷积少 随着卷积后面的参数量大 卷积多提取更细致
ResNet