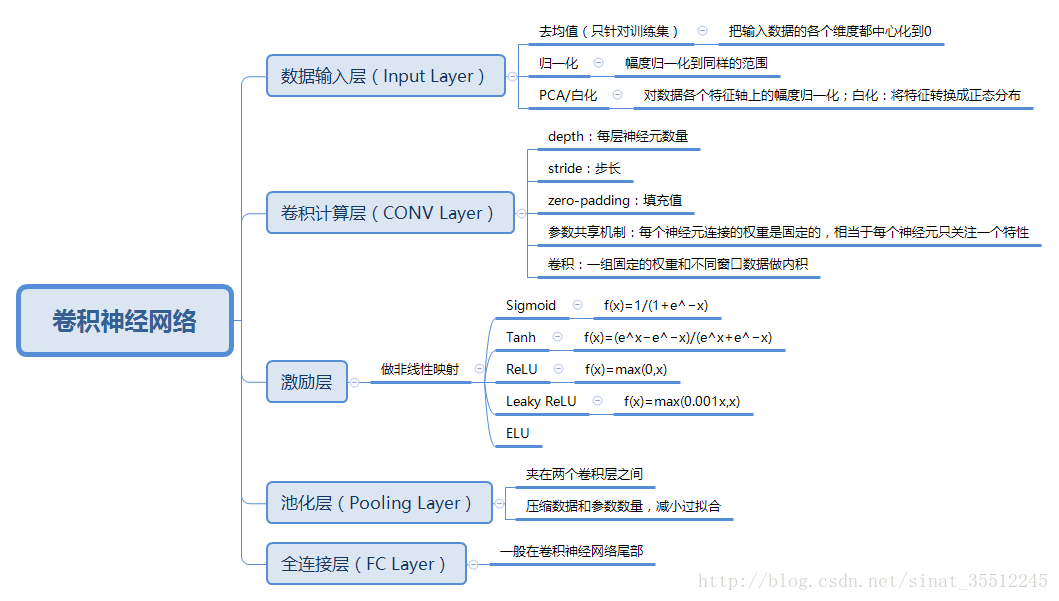
卷积层
CNN中卷积层的作用:
CNN中的卷积层,在很多网络结构中会用conv来表示,也就是convolution的缩写。
卷积层在CNN中扮演着很重要的角色——特征的抽象和提取,这也是CNN区别于传统的ANN或SVM的重要不同。
对于图片而言,图片是一个二维度的数据,我们怎样才能通过学习图片正确的模式来对于一张图片有正确的对于图片分类呢?这个时候,有人就提出了一个观点,我们可以这样,对于所有的像素,全部都连接上一个权值,我们也分很多层,然后最后进行分类,这样也可以,但是对于一张图片来说,像素点太多,参数太多了。然后就有人提出来,我们只看一部分怎么样,就是对于一张图片来说,我们只看一个小窗口就可以了,对于其他的地方,我们也提供类似的小窗口,我们知道,当我们对图片进行卷积的时候,我们可以对图片进行很多操作,比如说图片整体模糊,或者是边缘的提取,卷积操作对于图片来说可以很好的提取到特征,而且通过BP误差的传播,我们可以根据不同任务,得到对于这个任务最好的一个参数,学习出相对于这个任务的最好的卷积核,之所以权值共享的逻辑是:如果说一个卷积核在图片的一小块儿区域可以得到很好的特征,那么在其他的地方,也可以得到很好的特征。
填充(Padding)
valid:也就是不填充。
same:在图像边缘填充,使得输入和输出大小相同。
不采用padding的后果:
- 边缘信息采样小
- 输出图像变小
而paddding通常可以保证卷积过程中输入和输出的维度是一样的。它还可以使图像边缘附近的帧对输出的贡献和图像中心附近的帧一样。
假设输入的图像大小为:n*n,过滤器大小为f*f,填充的大小为p,步长为s;
那么,输出的大小为
①假设步长stride大小为1,并且没有填充,则输出为:
②假设步长stride大小为1,并且填充的大小为p,则输出为:
根据以上公式可以看出,加入我们没有填充的话,输出的大小会小于输入的大小,然而在实际中,我们往往希望,输出的大小能够与输入的大小相同,于是,我们可以得到下面这个等式:
解得:
由以上式子可知,当f为奇数时,填充的大小也随之确定。也许你会问,难道过滤器的大小一定要为奇数吗?理论上,f为偶数也是可以的。但是在实际工程应用中,f一般会取奇数(很多情况下取3),原因如下:
- 若为偶数,则有可能是不对称填充,显然我们不喜欢这样的操作
- 奇数有中心像素点,便于我们定位过滤器的位置
步长(Stride)
③假设步长大小为s,并且填充的大小为p,则输出为:
需要注意的是,当结果不为整数时,我们一般采取下取整操作!
池化(Pooling):卷积层是对图像的一个邻域进行卷积得到图像的邻域特征,池化层就是使用pooling技术将小邻域内的特征点整合得到新的特征。
优点:
- 显著减少参数数量
- 池化单元具有平移不变性
在实际中经常使用的是最大池化。
卷积神经网络减少参数的手段:
1)稀疏连接
一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为稀疏连接。
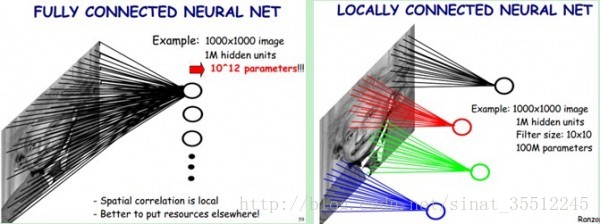
在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
2)参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8×8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8×8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8×8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
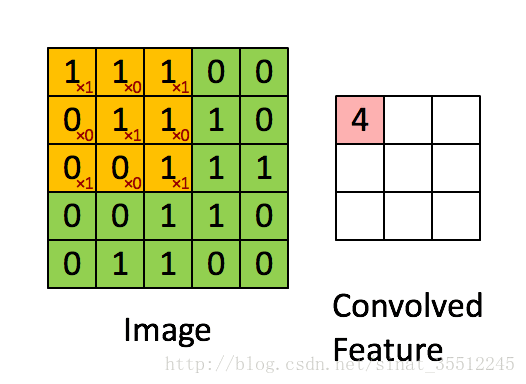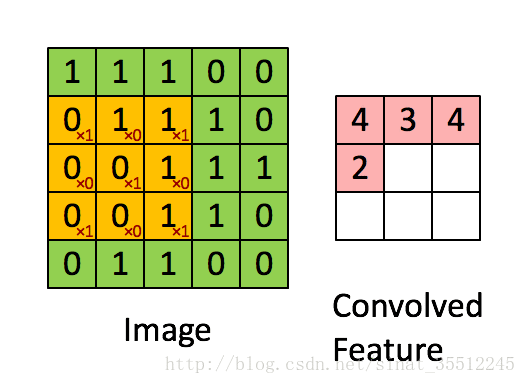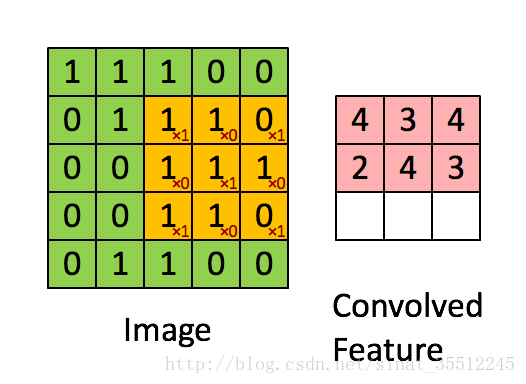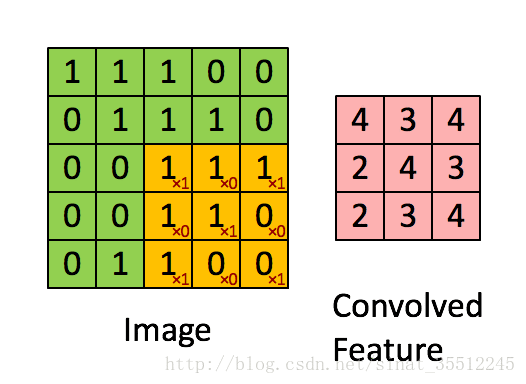
如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
参考文献: