卷积网络简介
卷积神经网络一个时下非常流行的词语,本文参考自己学习Udacity中的个人感悟及各位大佬的paper、slides、blog等等[1-],形成本文。一些基本概念解析可以先参考Udacity深度学习之卷积神经网络概念解析一文。
卷积神经网络我们可以理解成全连接神经网络的变体,有效降低了参数计算的复杂度(具体卷积神经网络时间复杂度如何衡量,想深入了解的朋友可以参考文献[6]卷积神经网络的复杂度分析,这里对模型复杂度暂时不做展开,只对模型的原理及应用展开说明。也欢迎大家留言讨论),具体怎么降低的呢?大家都知道的方法有参数共享、局部视野、池化等方法。然后,为什么降低呢?通俗来说,你要同时解100000个问题累不?CNN的参数共享、局部视野等操作就相当于将求解100000个问题简化为了求解10个问题,开心不?
卷积神经网络
卷积神经网络主要由输入层、卷积层、池化层[卷积层、池化层循环]、全连接层、Softmax层构成。这些构成我们可以拿以下图来示意:

当然这个图片里把激励层(RELU)单独拿出来了。输入了一辆汽车(但是计算机并不知道啊,计算机只认识0/1),这是一张RGB图片,channel=3,3通道的。我们先理解下卷积神经网络中的一些基本概念(概念解释来自于Udacity课程)。
参数共享
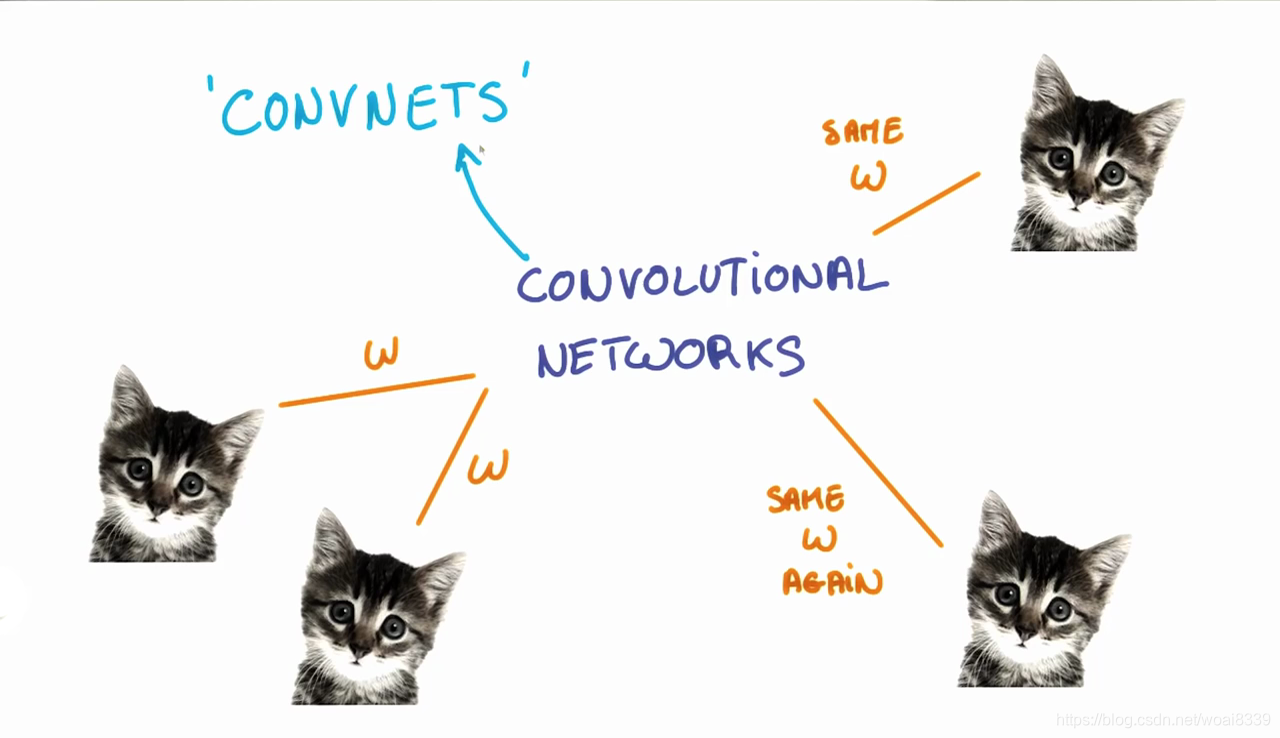
当我们试图识别一个猫的图片的时候,我们并不在意猫出现在哪个位置。无论是左上角,右下角,它在你眼里都是一只猫。我们希望 CNNs 能够无差别的识别,这如何做到呢?
如我们之前所见,一个给定的 patch 的分类,是由 patch 对应的权重和偏置项决定的。
如果我们想让左上角的猫与右下角的猫以同样的方式被识别,他们的权重和偏置项需要一样,这样他们才能以同一种方法识别。
这正是我们在 CNNs 中做的。一个给定输出层学到的权重和偏置项会共享在输入层所有的 patch 里。注意,当我们增大滤波器的深度的时候,我们需要学习的权重和偏置项的数量也会增加,因为权重并没有共享在所有输出的 channel 里。
共享参数还有一个额外的好处。如果我们不在所有的 patch 里用相同的权重,我们必须对每一个 patch 和它对应的隐藏层神经元学习新的参数。这不利于规模化,特别对于高清图片。因此,共享权重不仅帮我们平移不变,还给我们一个更小,可以规模化的模型。
padding
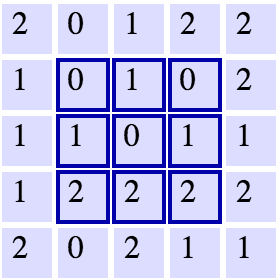
一个 5x5 的网格附带一个 3x3 的滤波器。来源: Andrej Karpathy。
假设现在有一个 5x5 网格 (如上图所示) 和一个尺寸为 3x3 stride值为 1 的滤波器(filter)。 下一层的 width 和 height 是多少呢? 如图中所示,在水平和竖直方向都可以在3个不同的位置放置 patch, 下一层的维度即为 3x3 。下一层宽和高的尺寸就会按此规则缩放。
在理想状态下,我们可以在层间保持相同的宽度和高度,以便继续添加图层,保持网络的一致性,而不用担心维度的缩小。如何实现这一构想?其中一种简单的办法是,在 5x5 原始图片的外层包裹一圈 0 ,如下图所示。

加了 0 padding的相同网格。 来源: Andrej Karpathy。
这将会把原始图片扩展到 7x7。 现在我们知道如何让下一层图片的尺寸维持在 5x5,保持维度的一致性。
维度
综合目前所学的知识,我们应该如何计算 CNN 中每一层神经元的数量呢?
输入层(input layer)维度值为W, 滤波器(filter)的维度值为 F (height * width * depth), stride 的数值为 S, padding 的数值为 P, 下一层的维度值可用如下公式表示: (W−F+2P)/S+1。
可能就有人会说,这个公式好难记住啊,记不住啊,咋办呢?我简单说一下我对(W−F+2P)/S+1这个公式理解,帮助大家记忆。
一开始输入层维度为W,如果我们padding,相当于为了一圈0。等价于在原有维度基础之上的最左边和最右边各加了一列0。如果做了P个padding,相当于在原有数据维度W的基础之上增加了(1+1)*P个维度,也就是数据维度达到了W+2*P的维度。再假设我们做了维度为F的滤波器,相当于我们将F维度的数值经过滤波器映射成为一个数值了,那么这个时候相当于在原有维度上削减了F。此时如果步长是1的话,相当于经过一次映射,W+2*P-F个,步长为S的话,当然要除以S,这样就是(W+2*P-F)/S了。注意一点,后面还要加1,嗯,,这个我还没理解,恳请大佬评论指教。
我们可以通过每一层神经元的维度信息,得知模型的规模,并了解到我们设定的 filter size和 stride 如何影响整个神经网络的尺寸。
Ref:
1、A Beginner’s Guide To Understanding Convolutional Neural Networks
2、Implementing a CNN for Text Classification in TensorFlow
3、卷积神经网络
4、UFLDL教程
5、CS231n的CNN讲义
6、卷积神经网络的复杂度分析
7、购买的udacity课程