英文原文:http://cs231n.github.io/convolutional-networks/
翻译原文:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit
感谢cs231n同时也感谢智能单元的翻译,但感觉还是原汁原味的比较好。
内容列表
- 常规神经网络缺陷
- 卷积神经网络优势
- 卷积神经网络结构
常规神经网络缺陷
传统神经网络的输入是一个向量,然后在一系列的隐层中对它做变换。每个隐层都是由若干的神经元组成,每个神经元都与前一层中的所有神经元连接。但是在一个隐层中,神经元相互独立不进行任何连接。最后的全连接层被称为“输出层”,在分类问题中,它输出的值被看做是不同类别的评分值。
常规神经网络对于大尺寸图像效果不尽人意。在CIFAR-10中,图像的尺寸是32x32x3(宽高均为32像素,3个颜色通道),因此,对应的的常规神经网络的第一个隐层中,每一个单独的全连接神经元就有32x32x3=3072个权重。这个数量看起来还可以接受,但是很显然这个全连接的结构不适用于更大尺寸的图像。举例说来,一个尺寸为200x200x3的图像,会让神经元包含200x200x3=120,000个权重值。而网络中肯定不止一个神经元,那么参数的量就会快速增加!显而易见,这种全连接方式效率低下,大量的参数也很快会导致网络过拟合。
卷积神经网络优势
神经元的三维排列。卷积神经网络针对输入全部是图像的情况,将结构调整得更加合理,获得了不小的优势。与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度(这里的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数)。举个例子,CIFAR-10中的图像是作为卷积神经网络的输入,该数据体的维度是32x32x3(宽度,高度和深度)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。对于用来分类CIFAR-10中的图像的卷积网络,其最后的输出层的维度是1x1x10,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。下面是例子:
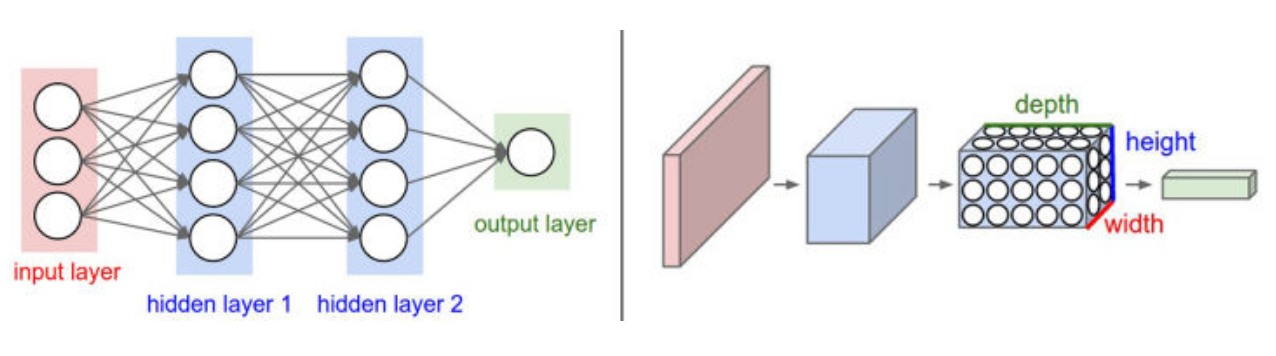
左边是一个3层的神经网络。右边是一个卷积神经网络,图例中网络将它的神经元都排列成3个维度(宽、高和深度)。卷积神经网络的每一层都将3D的输入数据变化为神经元3D的激活数据并输出。在这个例子中,红色的输入层装的是图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了红、绿、蓝3种颜色通道)。
卷积神经网络结构
- 卷积层
- 汇聚(Pooling)层
- 全连接层
卷积层
- 参数共享
- 局部连接
- 空间排列
以大脑做比喻:如果你喜欢用大脑和生物神经元来做比喻,那么输出的3D数据中的每个数据项可以被看做是神经元的一个输出,而该神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个滤波器得到的结果)。现在开始讨论神经元的连接,它们在空间中的排列,以及它们参数共享的模式。
没有参数共享的情况:特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这是非常复杂的,因此卷积神经网络引入“权值”共享原则,即一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
摘抄:https://www.cnblogs.com/believe-in-me/p/6645402.html
参数共享的意义:Gradient-Based Learning Applied to Document Recognition里的原文,简单来说,每种(个)filter学习一种feature,同一种filter权值当然是共享,所以就每个卷积层需要很多种filter,也就是depth来学习很多种不同的特征
cs231n原文:.
Parameter Sharing. Parameter sharing scheme is used in Convolutional Layers to control the number of parameters. Using the real-world example above, we see that there are 55*55*96 = 290,400 neurons in the first Conv Layer, and each has 11*11*3 = 363 weights and 1 bias. Together, this adds up to 290400 * 364 = 105,705,600 parameters on the first layer of the ConvNet alone. Clearly, this number is very high.
It turns out that we can dramatically reduce the number of parameters by making one reasonable assumption: That if one feature is useful to compute at some spatial position (x,y), then it should also be useful to compute at a different position (x2,y2). In other words, denoting a single 2-dimensional slice of depth as a depth slice (e.g. a volume of size [55x55x96] has 96 depth slices, each of size [55x55]), we are going to constrain the neurons in each depth slice to use the same weights and bias. With this parameter sharing scheme, the first Conv Layer in our example would now have only 96 unique set of weights (one for each depth slice), for a total of 96*11*11*3 = 34,848 unique weights, or 34,944 parameters (+96 biases). Alternatively, all 55*55 neurons in each depth slice will now be using the same parameters. In practice during backpropagation, every neuron in the volume will compute the gradient for its weights, but these gradients will be added up across each depth slice and only update a single set of weights per slice.
局部连接:在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
例1:假设输入数据体尺寸为[32x32x3](比如CIFAR-10的RGB图像),如果感受野(或滤波器尺寸)是5x5,那么卷积层中的每个神经元会有输入数据体中[5x5x3]区域的权重,共5x5x3=75个权重(还要加一个偏差参数)。注意这个连接在深度维度上的大小必须为3,和输入数据体的深度一致。
例2:假设输入数据体的尺寸是[16x16x20],感受野尺寸是3x3,那么卷积层中每个神经元和输入数据体就有3x3x20=180个连接。再次提示:在空间上连接是局部的(3x3),但是在深度上是和输入数据体一致的(20)。
空间排列:上文讲解了卷积层中每个神经元与输入数据体之间的连接方式,但是尚未讨论输出数据体中神经元的数量,以及它们的排列方式。3个超参数控制着输出数据体的尺寸:深度(depth),步长(stride)和零填充(zero-padding)。下面是对它们的讨论:
- 首先,输出数据体的深度是一个超参数:它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(depth column),也有人使用纤维(fibre)来称呼它们。
- 其次,在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2(或者不常用的3,或者更多,这些在实际中很少使用),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
- 在下文可以看到,有时候将输入数据体用0在边缘处进行填充是很方便的。这个零填充(zero-padding)的尺寸是一个超参数。零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。