利用逻辑回归进行分类的主要思想是:根据现有的数据对分类的边界建立回归公式,以此进行分类。进行分类的函数应该接受任何输出,任何输入0或1。这就是单位阶跃函数,另一个函数具有相似的性质这就是Sigmoid函数:1/1+e^-z
该函数接受输入后输出一个在0到1之间的数值。为了实现逻辑回归,我们将所有特征值乘上一个回归系数,然后累和输入到Sigmoid函数中,输出结果小于0.5被分入0类,反之分入1类。逻辑回归中最基本的问题就是如何求得最佳的回归系数。
下面利用梯度上升法求得最佳回归系数:
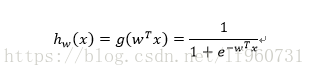
通过Sigmoid函数得到属于每个类的概率,其中w最佳回归系数向量,x为特征值
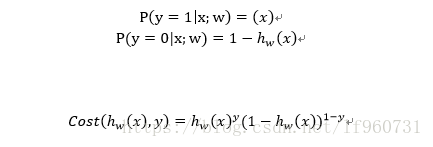
通过cost函数可以求得属于y=1类和y=0类的概率,那么只要给定一个样本i就可以求得其属于每个类的概率大小,这个概率应该越大越好。对于独立的样本集而言求解最佳回归系数就是求解cost函数的最佳似然估计,那么其似然函数为:
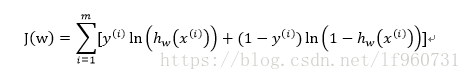
通常可以通过对似然函数求导取得其极值wj,但是实际中求导过于复杂,使用梯度上升法求得极值。我们都知道函数沿着梯度方向上升最快,那么我们每次迭代都沿着该点的梯度方向就可以迭代得到函数的极值即:
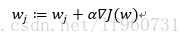
α为每沿梯度移动的步长
对似然函数求梯度可得:
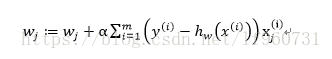
这样我们就可以通过迭代求出最佳回归系数。
其伪代码如下:
每个回归系数初始化为1
迭代R次:
计算整个数据的梯度
使用α乘梯度更新回归系数向量
返回回归系数
python实现的代码如下:
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001 #步长
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error #迭代更新回归系数向量
return weights