1.什么是多项式回归
多项式回归(Polynomial Regression)是研究一个因变量与一个或多个自变量间多项式的回归分析方法。如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。
在一元回归分析中,如果依变量y与自变量x的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。
多项式回归的最大优点就是可以通过增加x的高次项对实测点进行逼近,直至满意为止。
事实 wq上,多项式回归可以处理相当一类非线性问题,它在回归分析中占有重要的地位,因为任一函数都可以分段用多项式来逼近。
之前提到的线性回归实例中,是运用直线来拟合数据输入与输出之间的线性关系。不同于线性回归,多项式回归是使用曲线拟合数据的输入与输出的映射关系。
"""多项式回归"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
"""利用线性回归拟合曲线"""
lin_reg=LinearRegression()
lin_reg.fit(X,y)
y_predict=lin_reg.predict(X)
plt.scatter(x,y)
plt.plot(x,y_predict,color='r')
plt.show()
"""利用多项式回归,添加一个特征,即升维"""
X2=np.hstack([X,X**2])
lin_reg2=LinearRegression()
lin_reg2.fit(X2,y)
y_predict2=lin_reg2.predict(X2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r')
plt.show()"""scikit-learn中的多项式回归和Pipeline"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
poly=PolynomialFeatures(degree=2)
poly.fit(X)
X2=poly.transform(X)
lin_reg=LinearRegression()
lin_reg.fit(X2,y)
y_predict=lin_reg.predict(X2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='r')
plt.show()
"""关于Pipeline"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
def PolynomialRegression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_scaler",StandardScaler()),
("lin_reg",LinearRegression())
])
poly_reg=PolynomialRegression(degree=2)
poly_reg.fit(X,y)
y_predict=poly_reg.predict(X)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='r')
plt.show()
先升维,再归一化,然后利用线性回归进行拟合。所以Pipeline将这三步进行封装。
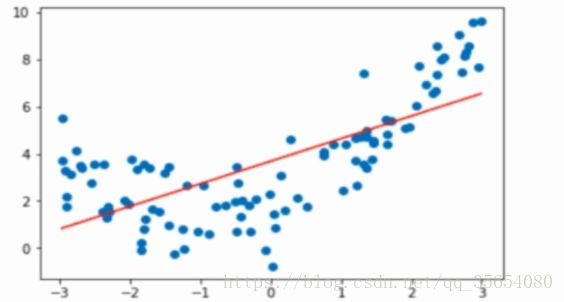
直接使用线性回归拟合曲线称为欠拟合,产生如图所示:
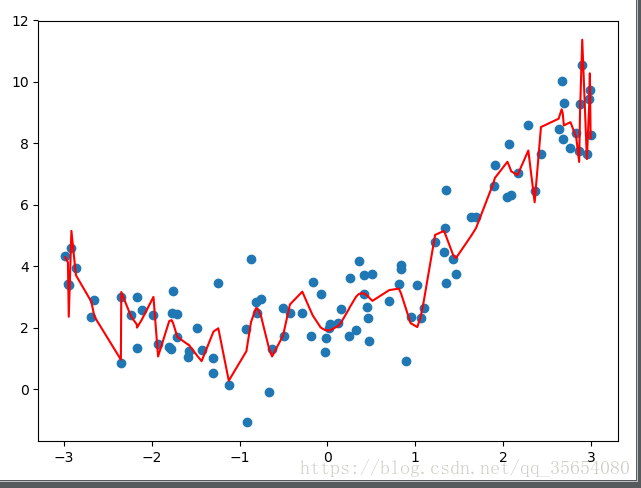
改变 ("poly",PolynomialFeatures(degree=2)),中degree的值 如degree=100,如下图,称为过拟合。
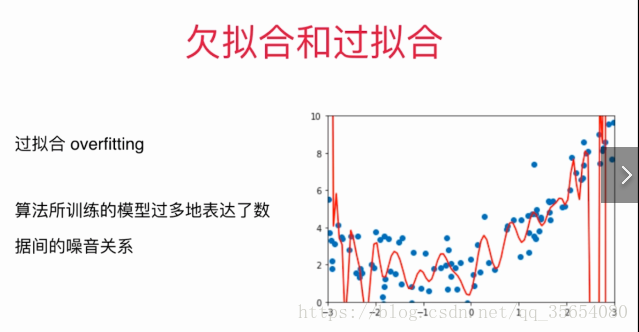
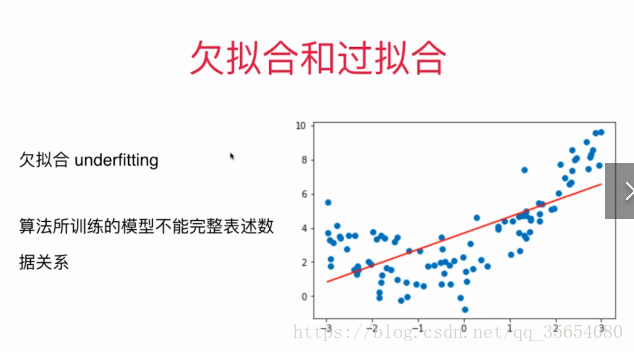
"""学习曲线"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
np.random.seed(666)
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
X_train,X_test,y_train,y_test=train_test_split(X,y)
def plot_learning_curve(algo,X_train,X_test,y_train,y_test,random_state=10):
train_score=[]
test_score=[]
for i in range(1,len(X_train)+1):
algo.fit(X_train[:i],y_train[:i])
y_train_predict=algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i],y_train_predict))
y_test_predict=algo.predict(X_test)
test_score.append(mean_squared_error(y_test_predict,y_test))
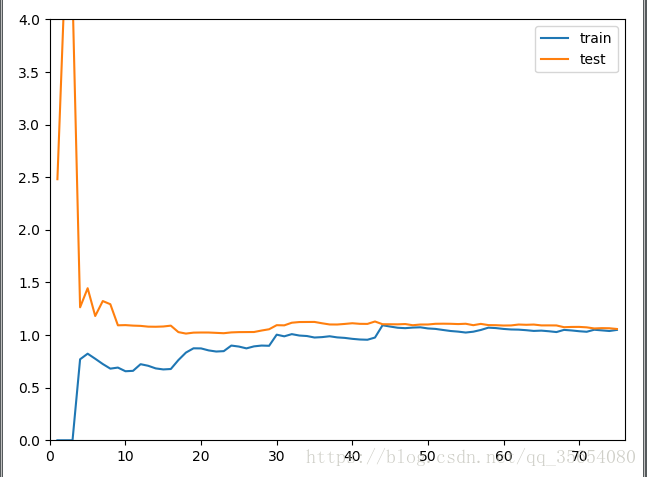
plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(train_score),label='train')
plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(test_score),label='test')
plt.legend()
plt.axis([0,len(X_train)+1,0,4])
plt.show()
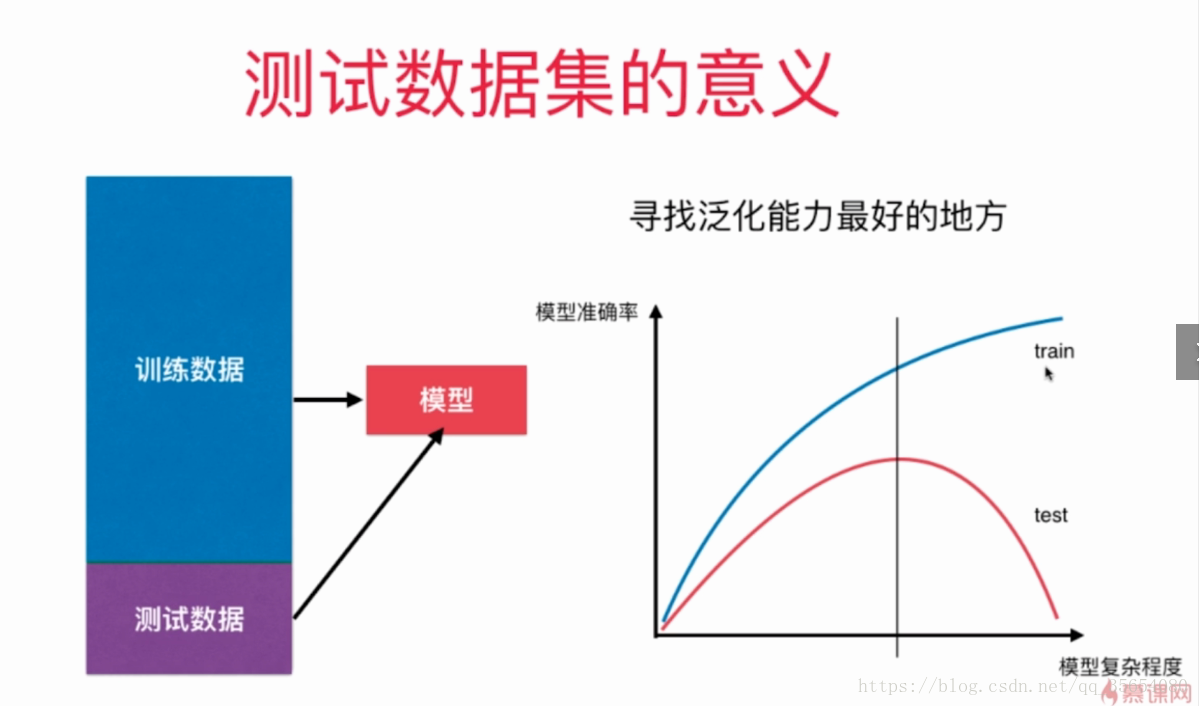
"""线性回归"""
plot_learning_curve(LinearRegression(),X_train,X_test,y_train,y_test)
"""二阶多项式回归"""
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
def PolynomialRegression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_scaler",StandardScaler()),
("lin_reg",LinearRegression())
])
poly_reg=PolynomialRegression(degree=2)
plot_learning_curve(poly_reg,X_train,X_test,y_train,y_test)
线性回归的学习率:

多项式回归的学习率:
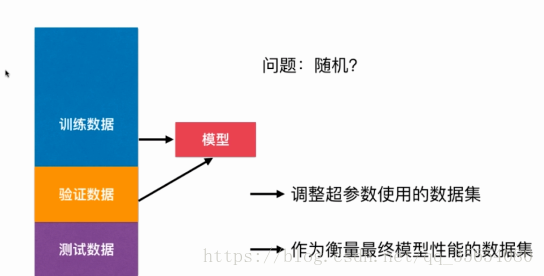
验证数据集和交叉验证:
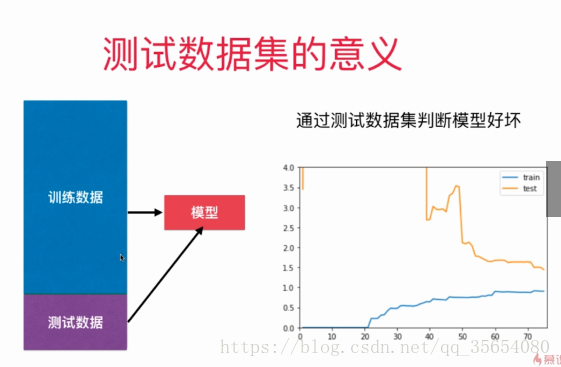
我们可以通过测试数据集来判断模型的好坏,但是可能会出现模型针对测试数据集过拟合的情况。
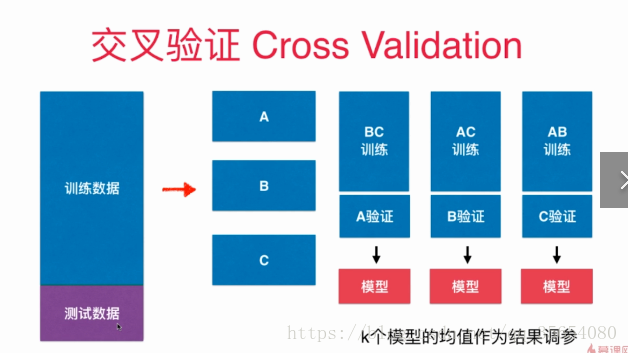
"""交叉验证"""
import numpy as np
from sklearn import datasets
digits=datasets.load_digits()
X=digits.data
y=digits.target
"""测试train_test_split"""
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4,random_state=666)
from sklearn.neighbors import KNeighborsClassifier
best_score,best_p,best_k=0,0,0
for k in range(2,11):
for p in range(1,6):
knn_clf=KNeighborsClassifier(weights='distance',n_neighbors=k,p=p)
knn_clf.fit(X_train,y_train)
score=knn_clf.score(X_test,y_test)
if score>best_score:
best_score,best_k,best_p=score,k,p
print('best k=',best_k)
print('best p=',best_p)
print('best score',best_score)
"""使用交叉验证"""
from sklearn.model_selection import cross_val_score
knn_clf=KNeighborsClassifier()
cross_val_score(knn_clf,X_train,y_train)
best_score,best_p,best_k=0,0,0
for k in range(2,11):
for p in range(1,6):
knn_clf=KNeighborsClassifier(weights='distance',n_neighbors=k,p=p)
scores=cross_val_score(knn_clf,X_train,y_train)
score=np.mean(scores)
if score>best_score:
best_score,best_k,best_p=score,k,p
print('best k=',best_k)
print('best p=',best_p)
print('best score',best_score)
"""回顾网格搜索"""
from sklearn.model_selection import GridSearchCV
param_grid=[
{
'weights':['distance'],
'n_neighbors':[i for i in range(2,11)],
'p':[i for i in range(1,6)]
}
]
grid_search=GridSearchCV(knn_clf,param_grid,verbose=1)
grid_search.fit(X_train,y_train)
print(grid_search.best_score_)
print(grid_search.best_params_)
best_knn=grid_search.best_estimator_
print(best_knn.score(X_test,y_test))
结果:
E:\pythonspace\KNN_function\venv\Scripts\python.exe E:/pythonspace/KNN_function/try.py
best k= 3
best p= 4
best score 0.9860917941585535
best k= 2
best p= 2
best score 0.9823599874006478
Fitting 3 folds for each of 45 candidates, totalling 135 fits
[Parallel(n_jobs=1)]: Done 135 out of 135 | elapsed: 1.8min finished
0.9823747680890538
{'n_neighbors': 2, 'p': 2, 'weights': 'distance'}
0.980528511821975
Process finished with exit code 0

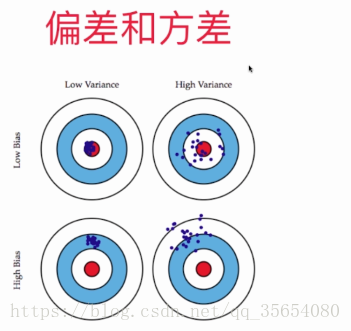



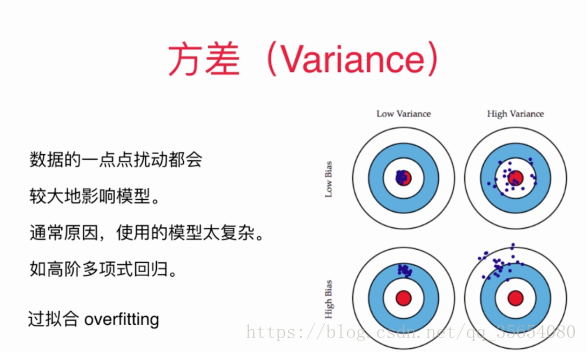



模型正则化:


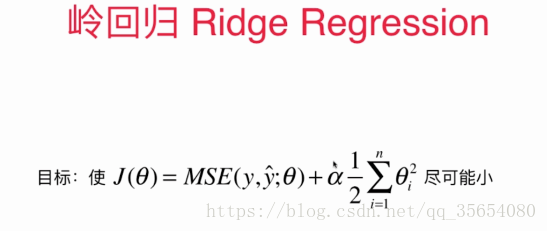
"""岭回归"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
np.random.seed(42)
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
np.random.seed(42)
X_train,X_test,y_train,y_test=train_test_split(X,y)
def plot_model(model):
X_polt=np.linspace(-3,3,100).reshape(100,1)
y_polt=model.predict(X_polt)
plt.scatter(x,y)
plt.plot(X_polt[:,0],y_polt,color='r')
plt.axis([-3,3,0,6])
plt.show()
"""使用岭回归"""
from sklearn.linear_model import Ridge
def RidgeRegression(degree,alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha))
])
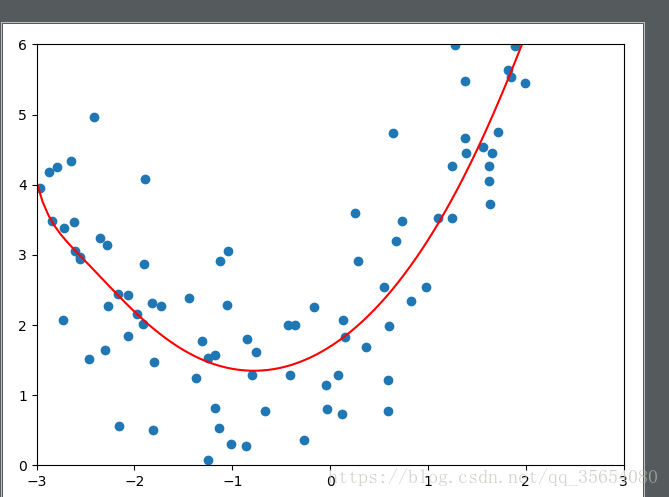
ridge1_reg=RidgeRegression(20,1)#alpha可以改变
ridge1_reg.fit(X_train,y_train)
y1_predict=ridge1_reg.predict(X_test)
plot_model(ridge1_reg)

"""LASSO进行模型正则化"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
np.random.seed(42)
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
np.random.seed(42)
X_train,X_test,y_train,y_test=train_test_split(X,y)
def plot_model(model):
X_polt=np.linspace(-3,3,100).reshape(100,1)
y_polt=model.predict(X_polt)
plt.scatter(x,y)
plt.plot(X_polt[:,0],y_polt,color='r')
plt.axis([-3,3,0,6])
plt.show()
"""使用Lasso"""
from sklearn.linear_model import Lasso
def LassoRegression(degree,alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lasso_reg", Lasso(alpha=alpha))
])
lasso1_reg=LassoRegression(20,1)#alpha可以改变
lasso1_reg.fit(X_train,y_train)
y1_predict=lasso1_reg.predict(X_test)
plot_model(lasso1_reg)

