前言
本节学习多项式回归和模型泛化
- 学习曲线
- 交叉验证
- 正则化
1、多项式回归
- 相比线性回归,为原数据添加新特征
- 新特征是对原数据的多项式组合
- 升维处理,在SVM里会体现
实现如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
"""多项式回归"""
# 数据
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, 100)
plt.scatter(x, y)
plt.show()
# 添加一个特征
X2 = np.hstack([X, X**2])
print(X2.shape)
# 对新数据集线性回归
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r') #平滑曲线需要对x排序
plt.show()
print(lin_reg2.coef_)
print(lin_reg2.intercept_)使用scikit库实现如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
"""用scikit实现多项式回归"""
# 数据
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, 100)
# 使用scikit增加特征
poly = PolynomialFeatures(degree=2) #初始化,两个维度
poly.fit(X)
X2 = poly.transform(X)
print(X2.shape)
print(X2[:5,:]) #可以看到第一列是1,第二列是X,第三列是X^2
# 线性回归
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()
print(lin_reg2.coef_)
print(lin_reg2.intercept_)
# 可以用pipeline一次性完成
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
poly_reg = Pipeline([
("poly", PolynomialFeatures(degree=2)), #添加维度
("std_scaler", StandardScaler()), #归一化
("lin_reg", LinearRegression()) #线性回归
])
poly_reg.fit(X, y)
y_predict = poly_reg.predict(X)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()最终效果如下
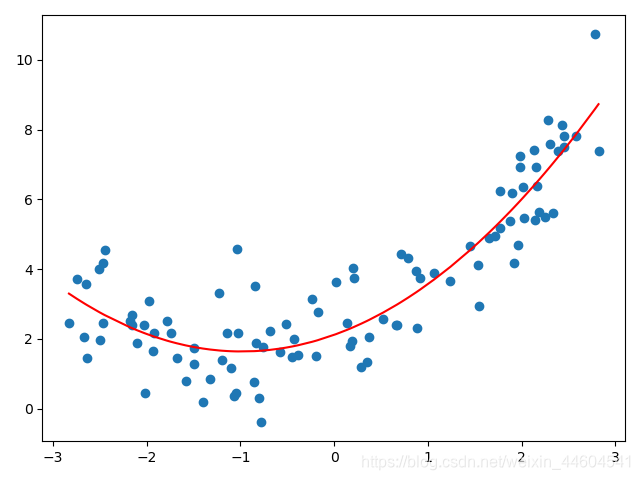
2、学习曲线
主要是一个模型泛化问题
也就是过拟合和欠拟合的问题
看图很好理解
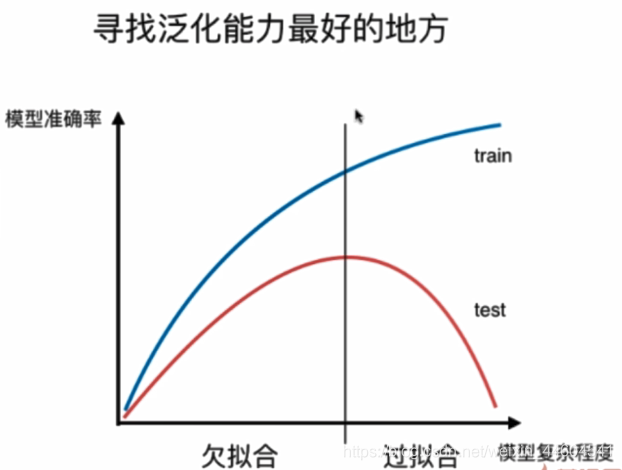
学习曲线
随着样本增多,算法训练出的模型的表现能力
实现如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
""" 学习曲线 """
# 数据
np.random.seed(666)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)
plt.scatter(x, y)
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=10)
print(X_train.shape)
# 学习曲线
train_score = []
test_score = []
for i in range(1, 76):
lin_reg = LinearRegression()
lin_reg.fit(X_train[:i], y_train[:i])
y_train_predict = lin_reg.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
y_test_predict = lin_reg.predict(X_test)
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(1, 76)], np.sqrt(train_score), label="train")
plt.plot([i for i in range(1, 76)], np.sqrt(test_score), label="test")
plt.legend()
plt.show()
"""封装成函数"""
def plot_learning_curve(algo, X_train, X_test, y_train, y_test):
train_score = []
test_score = []
for i in range(1, len(X_train) + 1):
algo.fit(X_train[:i], y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
y_test_predict = algo.predict(X_test)
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(1, len(X_train) + 1)],
np.sqrt(train_score), label="train")
plt.plot([i for i in range(1, len(X_train) + 1)],
np.sqrt(test_score), label="test")
plt.legend()
plt.axis([0, len(X_train) + 1, 0, 4]) #坐标轴范围作了限定
plt.show()
plot_learning_curve(LinearRegression(), X_train, X_test, y_train, y_test)
"""在多项式回归中的学习曲线"""
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
def PolynomialRegression(degree):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])
poly2_reg = PolynomialRegression(degree=2)
plot_learning_curve(poly2_reg, X_train, X_test, y_train, y_test)
poly20_reg = PolynomialRegression(degree=20)
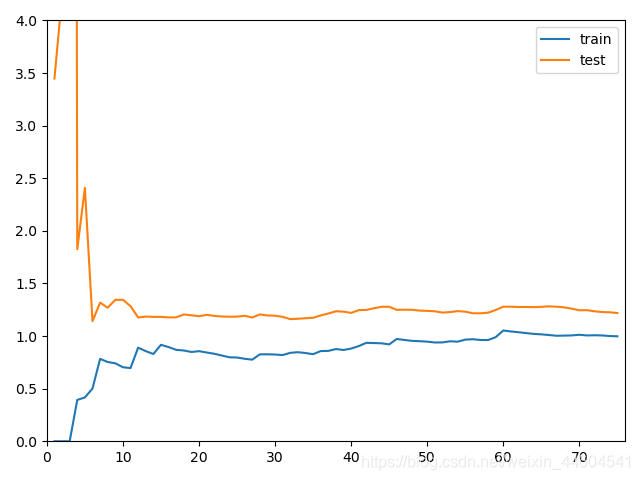
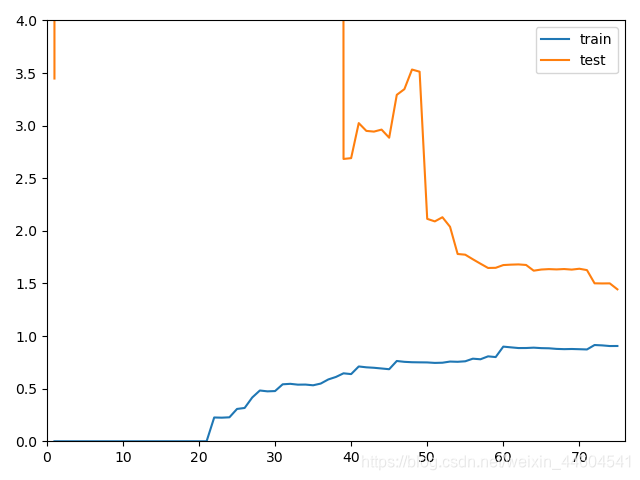
plot_learning_curve(poly20_reg, X_train, X_test, y_train, y_test)通过学习曲线可以判断欠拟合还是过拟合
欠拟合、最佳、过拟合的效果如下
- 欠拟合:比起最佳的,稳定值会高
- 过拟合:train的差别不大,test的误差大,且离得远
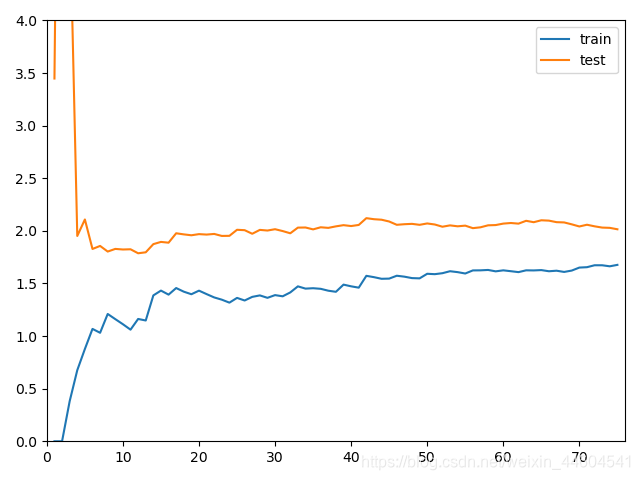
3、交叉验证
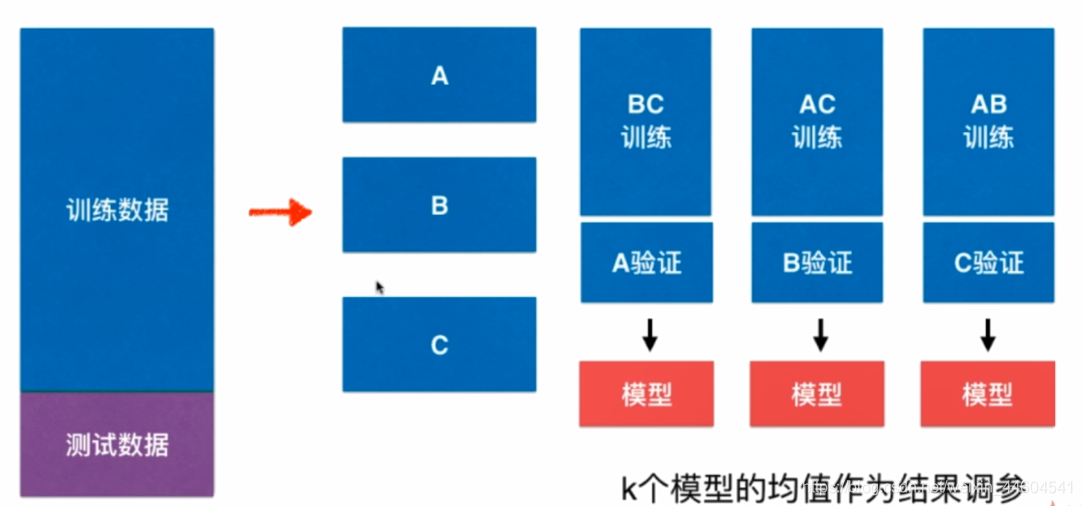
之前划分train-test数据集的做法,可能使得模型针对test数据集过拟合
解决办法就是交叉验证
- 增加验证数据集
- train数据集分为k份,每次训练k-1份留1份验证
- k个模型结果平均作为评判
实现如下
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
"""交叉验证"""
# 数据
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666)
# kNN下原先的train-test方式调参
best_k, best_p, best_score = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k, best_p, best_score = k, p, score
print("Best K =", best_k)
print("Best P =", best_p)
print("Best Score =", best_score)
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=best_k, p=best_p)
best_knn_clf.fit(X_train, y_train)
print(best_knn_clf.score(X_test, y_test))
# kNN下交叉验证方式调参
from sklearn.model_selection import cross_val_score
knn_clf = KNeighborsClassifier()
print(cross_val_score(knn_clf, X_train, y_train))
best_k, best_p, best_score = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
scores = cross_val_score(knn_clf, X_train, y_train, cv=3) #使用交叉验证来调参
score = np.mean(scores)
if score > best_score:
best_k, best_p, best_score = k, p, score
print("Best K =", best_k)
print("Best P =", best_p)
print("Best Score =", best_score)
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=best_k, p=best_p)
best_knn_clf.fit(X_train, y_train)
print(best_knn_clf.score(X_test, y_test))
# 前面学习的网格搜索已经用了交叉验证4、正则化
主要是以下几项内容
- 岭回归:L2正则项
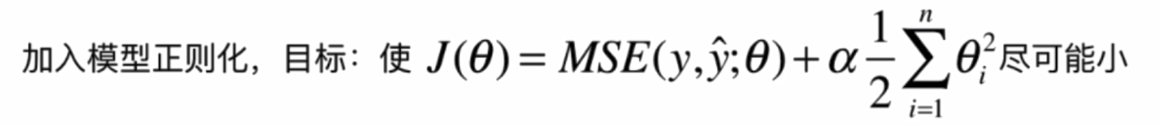
- lasso回归:L1正则项
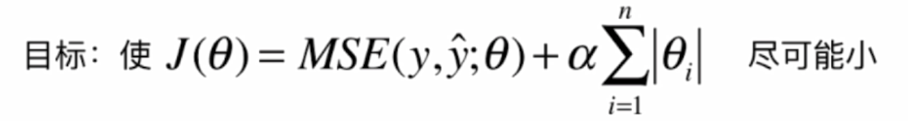
- 弹性网:用r表示L1正则项和L2正则项的比例
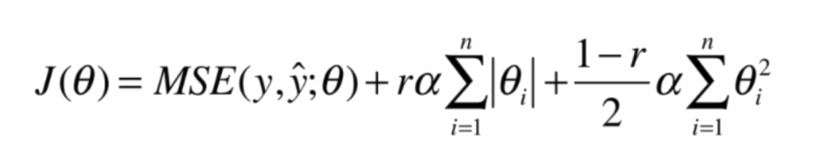
实现如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
"""模型正则化"""
# 数据
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3 + np.random.normal(0, 1, size=100)
plt.scatter(x, y)
plt.show()
# 多项式回归
def PolynomialRegression(degree):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])
# 绘图
def plot_model(model):
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(X_plot)
plt.scatter(x, y)
plt.plot(X_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
# 原实现
np.random.seed(666)
X_train, X_test, y_train, y_test = train_test_split(X, y)
poly_reg = PolynomialRegression(degree=20)
poly_reg.fit(X_train, y_train)
y_poly_predict = poly_reg.predict(X_test)
print(mean_squared_error(y_test, y_poly_predict))
plot_model(poly_reg)
# 正则化
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
# 岭回归
def RidgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha))
])
# α= 0.0001
ridge1_reg = RidgeRegression(20, 0.0001)
ridge1_reg.fit(X_train, y_train)
y1_predict = ridge1_reg.predict(X_test)
print(mean_squared_error(y_test, y1_predict))
plot_model(ridge1_reg)
# α= 1
ridge2_reg = RidgeRegression(20, 1)
ridge2_reg.fit(X_train, y_train)
y2_predict = ridge2_reg.predict(X_test)
print(mean_squared_error(y_test, y2_predict))
plot_model(ridge2_reg)
# α= 100
ridge3_reg = RidgeRegression(20, 100)
ridge3_reg.fit(X_train, y_train)
y3_predict = ridge3_reg.predict(X_test)
print(mean_squared_error(y_test, y3_predict))
plot_model(ridge3_reg)
# lasso回归
def LassoRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lasso_reg", Lasso(alpha=alpha))
])
# α= 0.01
lasso1_reg = LassoRegression(20, 0.01)
lasso1_reg.fit(X_train, y_train)
y1_predict = lasso1_reg.predict(X_test)
print(mean_squared_error(y_test, y1_predict))
plot_model(lasso1_reg)
# α= 0.1
lasso2_reg = LassoRegression(20, 0.1)
lasso2_reg.fit(X_train, y_train)
y2_predict = lasso2_reg.predict(X_test)
print(mean_squared_error(y_test, y2_predict))
plot_model(lasso2_reg)
# α= 1
lasso3_reg = LassoRegression(20, 1)
lasso3_reg.fit(X_train, y_train)
y3_predict = lasso3_reg.predict(X_test)
print(mean_squared_error(y_test, y3_predict))
plot_model(lasso3_reg)岭回归较好效果
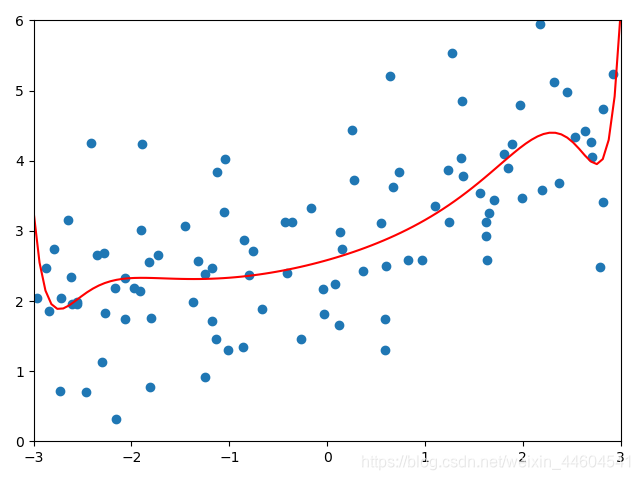
lasso回归较好效果
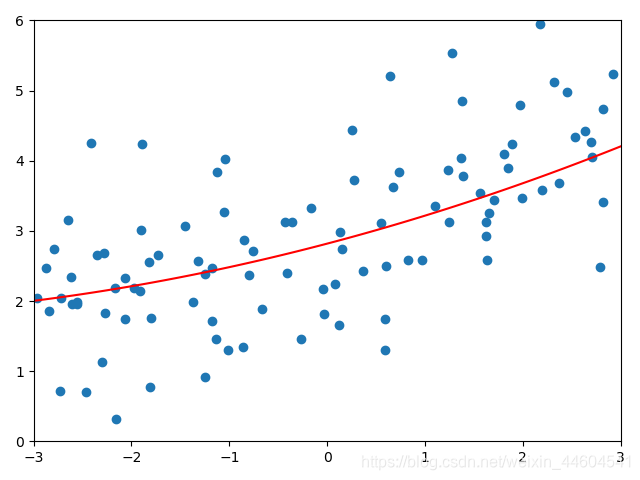
结语
本节学习了多项式回归
以及各种模型泛化的的考虑