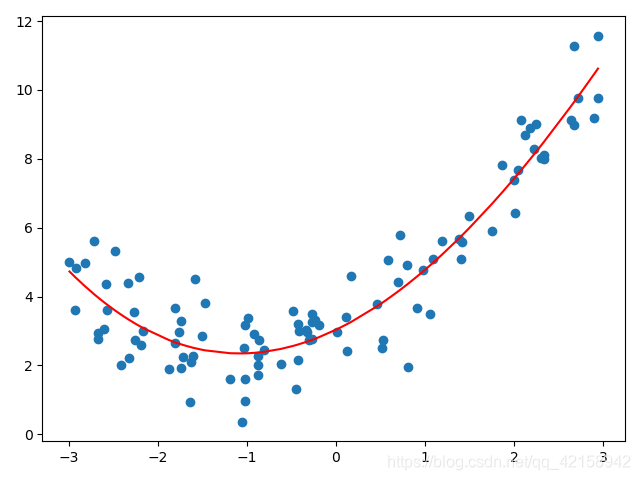
多项式回归,回归函数是回归变量多项式的回归。多项式回归模型是线性回归模型的一种,此时回归函数关于回归系数是线性的。由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。
y=ax2+bx+c
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3, 3, size=100)
y = 0.5 * x ** 2 + x + 3 + np.random.normal(0, 1, size=100)
x1 = x.reshape(-1, 1)
from sklearn.preprocessing import PolynomialFeatures
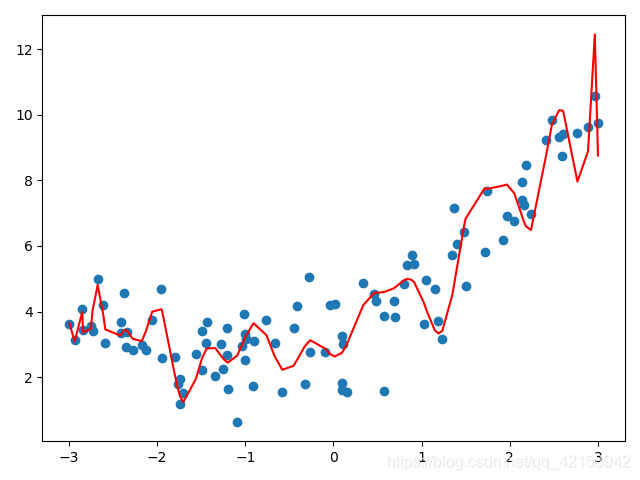
plf = PolynomialFeatures(degree=3)
# Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
poly = Pipeline([
('poly', PolynomialFeatures(degree=3)),
('stds', StandardScaler()),
('lre', LinearRegression())
])
poly.fit(x1, y)
p_x1 = poly.predict(x1)
plt.scatter(x, y)
plt.plot(np.sort(x), p_x1[np.argsort(x)], color='r')
plt.show()
过拟合
过拟合是指为了得到一致假设而使假设变得过度严格。
解决方法
(1)在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
欠拟合
欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
解决方法
过拟合和欠拟合是所有机器学习算法都要考虑的问题,其中欠拟合的情况比较容易克服, 常见解决方法有:
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
- 使用非线性模型,比如核SVM 、决策树、深度学习等模型;
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
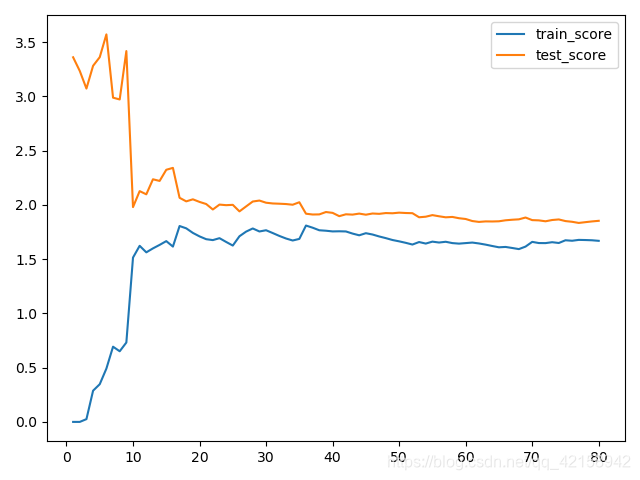
学习曲线
定义:随着训练样本的逐渐增多,算法训练出的模型的表现能力
通过学习曲线可以看出过拟合与欠拟合的情况
from sklearn.metrics import mean_squared_error
train_score=[]
test_score=[]
for i in range(1,len(train_data)+1):
lre=LinearRegression()
# 训练集评测
lre.fit(train_data[:i],train_label[:i])
p_tn=lre.predict(train_data[:i])
train_score.append(mean_squared_error(train_label[:i],p_tn))
# 测试集评测
p_test = lre.predict(test_data)
test_score.append(mean_squared_error(test_lable, p_test))
plt.plot([i for i in range(1,len(train_data)+1)],np.sqrt(train_score),label='train_score')
plt.plot([i for i in range(1,len(train_data)+1)],np.sqrt(test_score),label='test_score')
plt.legend()
plt.show()
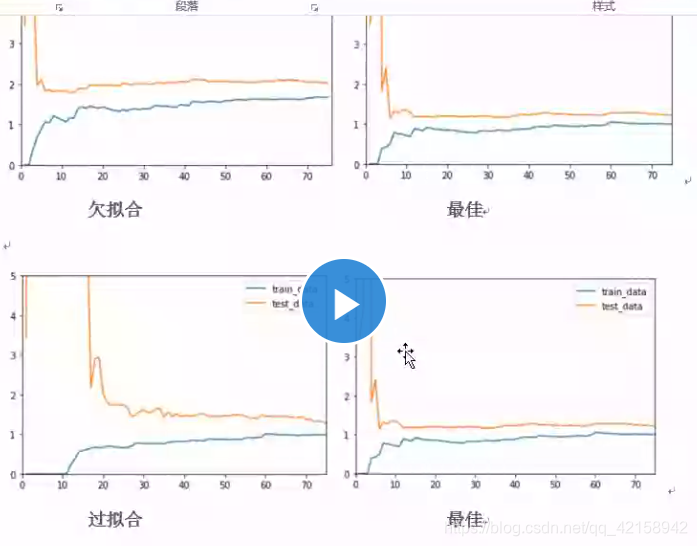
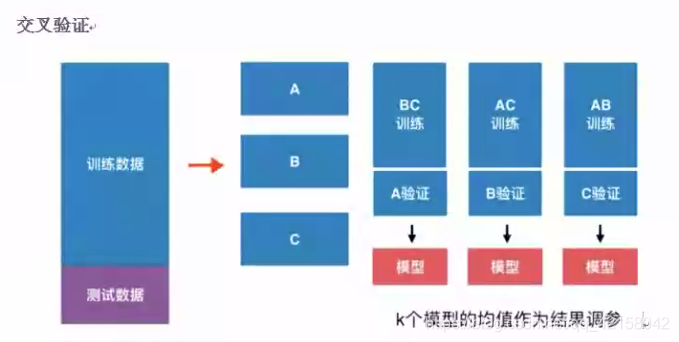
验证数据集与交叉验证
普通情况:训练集+测试集 --> 模型 问题:可能过拟合
K-折交叉验证(k表示训练集拆成k份)
缺点:每次训练k个模型,相当于整体性能满了k倍
from sklearn import datasets
import numpy as np
#加载手写字数据集
digit=datasets.load_digits()
x=digit.data
y=digit.target
# 数据集分割
from sklearn.model_selection import train_test_split
train_data, test_data, train_label, test_lable = train_test_split(x, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
best_k=0
best_p=0
best_score=0.0
for k in range(1,9):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights='distance', p=p)
knn_clf.fit(train_data, train_label)
# score=knn_clf.score(test_data,test_lable)
score=np.mean(cross_val_score(knn_clf,train_data,train_label))
if score>best_score:
best_score=score
best_k=k
best_p=p
print(best_k,best_p,best_score)
#交叉验证
# k_clf=KNeighborsClassifier()
# from sklearn.model_selection import cross_val_score
# np.mean(cross_val_score(k_clf,train_data,train_label))
留一法
留一法就是每次留下一个样本做测试集,其他样本做训练集,如果有k个样本,则需要训练k次,测试k次。
优点:完全不受随机影响,最接近模型真实性能指标。
缺点:计算量巨大