版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lihaogn/article/details/81838828
1 多项式回归
1.1 介绍
多项式回归,用来对非线性数据集进行处理,例如二次函数。
1.2 代码
1)多项式回归和线性回归比较
import numpy as np
import matplotlib.pyplot as plt
# 准备数据
x=np.random.uniform(-3,3,size=100)
xx=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)
plt.scatter(x,y)
plt.show()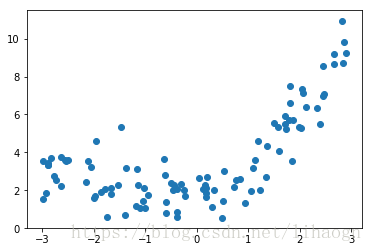
# 线性回归
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(xx,y)
y_predict=lin_reg.predict(xx)
plt.scatter(x,y)
plt.plot(x,y_predict,color='r')
plt.show()
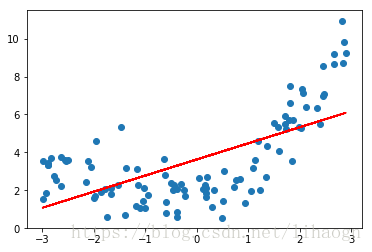
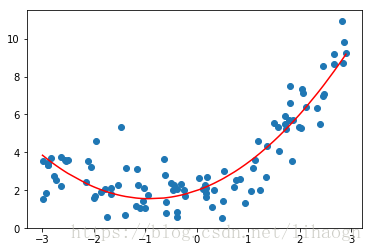
# 多项式回归,添加一个特征
xx2=np.hstack([xx,xx**2])
lin_reg2=LinearRegression()
lin_reg2.fit(xx2,y)
y_predict2=lin_reg2.predict(xx2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r')
plt.show()
lin_reg2.coef_ # array([0.95895082, 0.52687416])
2 模型泛化相关
2.1 模型复杂度曲线
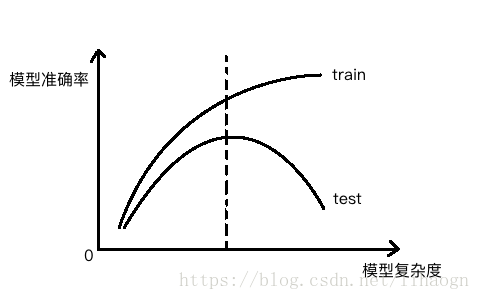
测试数据集的意义:寻找泛化能力最好的地方。
2.2 学习曲线
含义:随着训练样本的逐渐增多,算法训练出的模型的表现能力。
问题:特定的测试数据集出现过拟合的情况。
解决方案:将样本数据集分为:训练、验证、测试数据集。
- 训练数据集 -> 用来产生模型
- 验证数据集 -> 调整超参数使用的数据集
- 测试数据集 -> 衡量最终模型性能的数据集
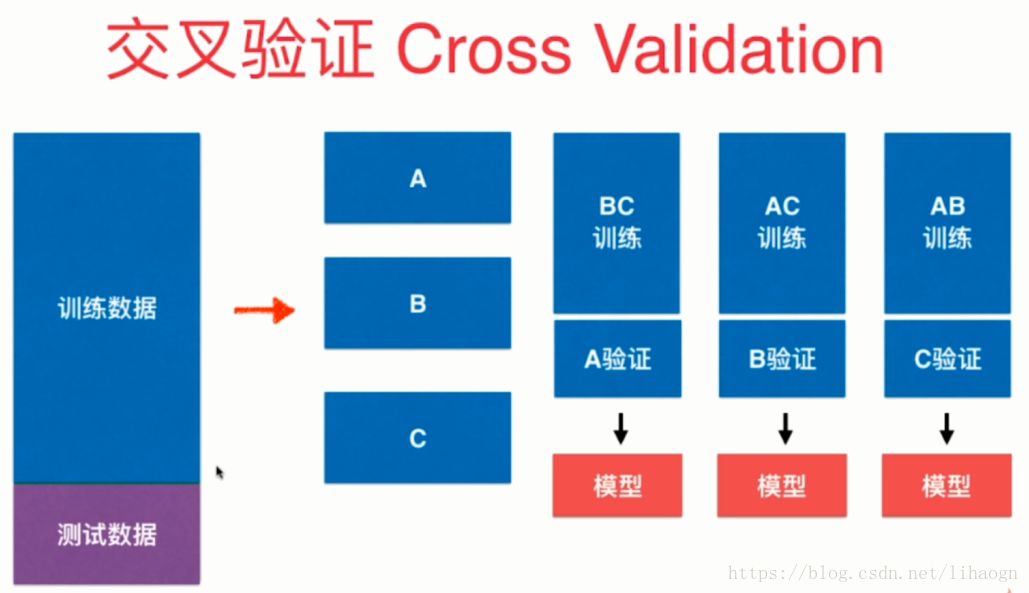
2.3 交叉验证
将下图中n个模型的均值作为结果调参。
2.4 偏差与方差
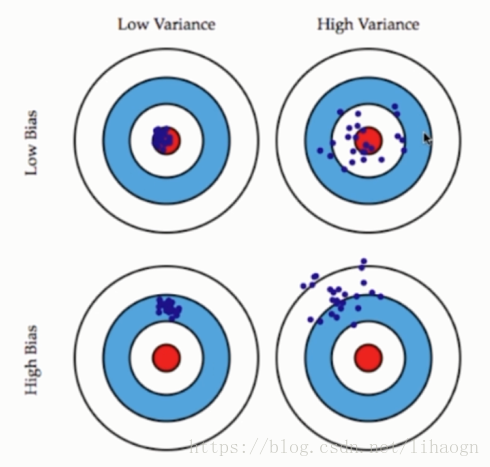
模型误差=偏差+方差+不可避免误差
导致偏差的主要原因;
- 对问题本身的假设不正确,如:非线性数据使用线性回归。
与方差相关:
- 数据的一点点扰动都会较大地影响模型。
- 通常原因,使用的模型太过复杂,如:高阶多项式回归。
注意:
- 有一些算法天生是高方差的算法,如kNN。非参数学习通常都是高方差算法,因为不对数据进行任何假设。
- 有一些算法天生是高偏差算法,如线性回归。参数学习通常都是高偏差算法,因为堆数据具有极强的假设。
- 偏差和方差通常是矛盾的。降低偏差,会提高方差;降低方差,会提高偏差。
- 机器学习的主要挑战来自于方差。
解决高方差的通常手段:
- 降低模型复杂度
- 减少数据维度;降噪
- 增加样本数
- 使用验证集
- 模型正则化
2.5 模型正则化
目标:使 尽肯能小
即,使 尽肯能小
1)岭回归(Ridge Regression)
目标,使 尽肯能小
2)LASSO Regression
目标,使 尽肯能小
3)弹性网(Elastic Net)