本人和机器学习已经久违了,暑假难得有时间,来学一学并和大家分享,希望小伙伴们不吝赐教!
一. 过拟合与欠拟合
我们实际希望的,是在新样本上能表现得很好的学习器。为了达到这个目的,应该从训练样本中尽可能选出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别.然而,当学习器把训练样本学得“太好”了的时候,很可能巳经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象在机器学习中称为“过拟合” 。 与"过拟合"相对的是“欠拟合” ,这是指对训练样本的一般性质尚未拟合学习好。
废话不多说,上才艺:
在之前我们用多项式回归来代替线性回归的时候,传入一个参数 用来表示我们需要拟合多项式的最高次幂,像这样:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
x = np.random.uniform(-3,3,size = 100)
X = x.reshape(-1,1)
y = 0.5* x **2+ x + 2 + np.random.normal(0,1,100)
def PolynomialRegression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=3)),
("std_scaler",StandardScaler()),
("iin_reg",LinearRegression())
])
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color = 'r')
plt.show()

这里我们还是从头实现一下源码!注意,这时我们传入的degree = 2,此时我们希望能够更好的拟合这些离散点,提高degree 的值看看:
poly10_reg = PolynomialRegression(degree=10)
poly10_reg.fit(X,y)
y10_predict = poly10_reg.predict(X)
plt.scatter(x,y)
plt.plot(np.sort(x),y10_predict[np.argsort(x)],color = 'r')
plt.show()

显然,这似乎更能贴切的拟合这些离散的点!是不是我们增加degree 的值就可以能够更好地拟合模型呢? 索性加到100!
在这里要注意,如果你直接将degree的值改到100的话,得到的图并不是我们需要的拟合曲线,而是根据这些离散点绘制的:

我们还学要进一步处理才能得到真的degree为100的那个拟合曲线!
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = poly100_reg.predict(X_plot)
plt.scatter(x,y)
plt.plot(X_plot[:,0],y_plot,color = 'r')
plt.axis([-3,3,-1,10])
plt.show()

浮夸归浮夸,结果还是它!如果您不介意,可以继续提高degree 的值,最后有可能所有的离散点都在一条曲线上,同时,均方误差MSE可能无限 的趋近 0,但是这并没有啥子用!因为它已经完全不能代表和预测我们样本点的走势了,只是单纯的为我们降低MSE!这也就是我们耳熟能详的 “过拟合”,那么欠拟合就更简单了,也就是degree 的值太小,拟合不了这些点的趋势!
这话又说回来了,既然这个degree 调高了不行,调少了也不行,那么我们如何能够找到适合模型的degree 呢!这就是玄学了,不过目前我们所需要知道的,就是将原始数据集分成trian 和 test 数据集!根据初始化degree先拟合一下,将test带入其中并计算准确率,在回过头来调degree !所以,数据集分开的重要意义就是调参数提升拟合效果!

二. train_test_spilt 的意义
这里我们重新建立一个文件,以防混淆!
import numpy as np #导包
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
np.random.seed(666)
x = np.random.uniform(-3,3,size = 100)
X = x.reshape(-1,1)
y = 0.5* x **2 + x + 2 + np.random.normal(0,1,100)
完成的导包和建立随机数据之后,我们将其分开!
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 666)
我们先来测试一下 对于线性回归的模型拟合效果怎么样!
lin_reg = LinearRegression() #先试用线性回归 MSE看一下误差!
lin_reg.fit(X_train,y_train) #先用X_train数据训练模型 再用X_test 预测,将预测值与 真正的y_predict求MSE
y_predict = lin_reg.predict(X_test)
mean_squared_error (y_test,y_predict)
得到的值为:2.2199965269396573
注意后面预测的时候我用的是X_test ,求MSE是用的是 真实的y_test 与以 X_train,y_trian 建立模型预测得到的y_predict 进行对比计算,千万不要弄混!
同样的方式,我们采用多项式回归来看看会好多少!
def PolynomialRegression (degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_scaler",StandardScaler()),
("iin_reg",LinearRegression())
])
poly_reg = PolynomialRegression(degree = 2)
poly_reg.fit(X_train,y_train)
y2_predict = poly_reg.predict(X_test)
mean_squared_error(y_test,y2_predict) #此处的泛化能力更强!

显然,这里模型的泛化能力更强!如果我们提高degree的值会怎么样呢!
poly10_reg = PolynomialRegression(degree = 10)
poly10_reg.fit(X_train,y_train)
y10_predict = poly10_reg.predict(X_test)
mean_squared_error(y_test,y10_predict)
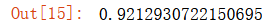
这里的MSE 已经变大了,说明模型的拟合效果开始变得不好了,因为过拟合了!
综合上面的解释,我们可以画一张图直观的展示这些关系!

算法工程师的一个重要工作就是调参,已达到我们上图中test曲线的最高值!
三. 学习曲线
定义: 随着训练样本的逐渐增多,算法训练出的模型的表现能力!
这里和前面说的 有点不一样了,最大区别在于它是需要我们逐渐向其中增加样本数量,逐渐拟合,前面的模型拟合都是一蹴而就的,容易出差错!
直接上算法源码,这里还是用起上面我们刚使用过的随机数据!
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 6)
def plot_learning_curve(algo,X_train,X_test,y_train,y_test):
train_score = []
test_scroe = []
for i in range(1,len(X_train)+1):
algo.fit(X_train[:i],y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i],y_train_predict))
y_test_predict = algo.predict(X_test)
test_scroe.append(mean_squared_error(y_test,y_test_predict))
plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(train_score),label="train")
plt.plot([i for i in range(1,len(X_train)+1)],np.sqrt(test_scroe),label="test")
plt.legend()
plt.axis([0,len(X_train)+1,0,4])
plt.show()
我们选好拟合模型之后,每传入一次数据,就进行一次拟合,直到将我们之前分好的数据集全部代入计算完成,大概的思路就是这样,代码也非常的简单!就不多解释了!
我们使用这个算法:
plot_learning_curve(LinearRegression(),X_train,X_test,y_train,y_test) #线性回归的学习率

算法先用train 数据集去套拟合模型,所以刚开始样本数据非常少的时候,test数据预测的误差会非常大,这和上图中橘黄色的曲线是吻合的,可以不用管它,随着数据逐渐加入,最后二者的MSE 会 平和的汇聚在一起!
如果你过拟合了,degree太高了 ,就会出现这样:
ploy20_reg = PolynomialRegression(degree=20)
plot_learning_curve(ploy20_reg,X_train,X_test,y_train,y_test)#高阶多项式数据拟合学习曲线

大家都可以看到这样的话,就不太友好,间距太大,test数据集的误差太大了!
所以,综上可以看出 学习曲线也是帮助我们 调参,防止过拟合或者是欠拟合的一个较为稳定的好方法!
本期就到这里了,祝大家生活愉快!