多项式回归与模型泛化
一入计科深似海,从此头发是路人!
先赞再看,养成好习惯!
这个多项式回归是建立在已经熟练掌握机器学习中的线性回归基础之上的进一步关于回归曲线方法的学习,需要有有一定的sklearn基础,不过本人也会为大家做好详细的注释,希望大家能够喜欢!
一 . 一个简单的小例子
我们都知道线性回归法是存在很大的局限性的,它要求我们被拟合的数据必须存在线性关系,但是现实的世界中,这样特征鲜明的数据是很少的,大部分我们待预测的数据本身都是非线性的关系,比如像二次抛物线,或者高次幂函数,下面我们在sklearn中的 LinearRegression算法基础上拓展一种更适用的拟合方法。
本博客偏代码的运行与解释,当然,数学原理也会适当的插入一部分,最终的目的还是让大家能理解并运用算法!
我们先举一个简单的例子来帮助大家我们接下来要做什么:
(1)创建随机数据
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3,3,size=100) #在区间[-3,3]上随机取100个数
X = x.reshape(-1,1)# 将生成的100个数据搞成一列 不管多少行~~
这里的uniform是从[-3,3]上均匀分布里面随机取100个数据,reshape函数就这100个数据搞成100行 1列,开头对导包我就不说了。。。。。
(2)接下来啊,我们随便写一个二次多项式函数,构成我们因变量y的数据,后面再跟一个满足正态分布的小噪音!
y = 0.7* x **2 + x + 5 + np.random.normal(0,1,size = 100)
(3)x , y数据现在我们都有了,我们来画个图看看它长啥样呗!
plt.scatter(x,y)
plt.show()

憨憨都能看出来这个是个二次函数的模型!O(∩_∩)O哈哈~
(4)这个时候,我们目前也不知道怎么根据数据拟合曲线啊,只学过线性回归,就用这个试一试又何妨,又不要钱!
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
y_predict = lin_reg.predict(X)
这里是我们调用LinearRegression算法,通过算法中的计算求残差和截距等步骤,这一步lin_reg.fit(X,y) 传入我们需要拟合的数据X与y之后,返回的是已经求好的直线。最后一步,由于直线已经求好了,但直线上的点 是与X对应预测值,我们将这些预测值传给y_predict 这一个变量名中!
(因为我们要画图啊,没有X,y的值我们画不了图啊,得到的直线产生的预测值我们必须将它保存到另一个变量中,不然画图的时候y的值从哪里来,算法没有给你传好预测值哦!)
(5)这里还是画图,我们用红色的线画出拟合成的直线,散点和直线在一起会更直观!
plt.scatter(x,y)
plt.plot(X,y_predict,color='r')
plt.show()
 我们只能说这个直线真的尽力了,但还是没卵用!
我们只能说这个直线真的尽力了,但还是没卵用!
那么我们如何将这条直线绕着这些点,变弯呢? 其实问题还是出现在我们这个X的原始数据集上,里面只有100行1列的 数字,算法在拟合的时候只能找到X,前面的 它找死也没找到!我们改下这个X数据集!
(6)再添加一列,为第一列数据的平方!
X_2 = np.hstack([X,X**2]) #我们造一个100行2列的数据,,第二列是X的平方
(7)这次,我们再来实现上面的算法和画图!
lin_reg_2 = LinearRegression() #用sklearn中实例化 这次用 x与 x的平方去拟合成二次曲线
lin_reg_2.fit(X_2,y)
y_predict_2 = lin_reg_2.predict(X_2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict_2[np.argsort(x)],color='r')
plt.show()
注意,既然X中有2列,分别对应,我们在画图的时候就要将X与
对应起来,用到了 sort(x)和 np.argsort(x),结果就是:

这样,就舒服多了!
二. scikit-learn中的多项式回归与pipeline
1. sklearn中的多项式回归
上面我们用一个简单的例子帮助大家更加直观的理解了多项式回归,但是我们不可能每次导入数据集都手动给原始数据进行平方 或者是 高次方操作,我们可以直接用sklearn中的方法实现,这一需求!
(1)开始我们还是和前面一样,在这里我再传入代码:
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3,3,size = 100)
X = x.reshape(-1,1)
y = 0.5* x **2 + x + 2 + np.random.normal(0,1,100)
(2)重整原始数据集(详解)
from sklearn.preprocessing import PolynomialFeatures #我们采用 sklearn 中的这个类拟合多项式
这个类(PolynomialFeatures)可以帮助我们,使用它会非常的简单!
poly = PolynomialFeatures(degree = 2)#这里的 degree 为我们需要拟合函数的最高次幂
poly.fit(X)
X_2 = poly.transform (X)#这两步是训练和拟合
这里的degree就是 y函数中多项式的最高次幂,比如像
的degree就是 3,这个自己选择!后面两步poly.fit(X) 与 X_2 = poly.transform (X) 其实就是训练和重整这个数据集!我们把这个新得到的X_2前面几行展示出来看一下:
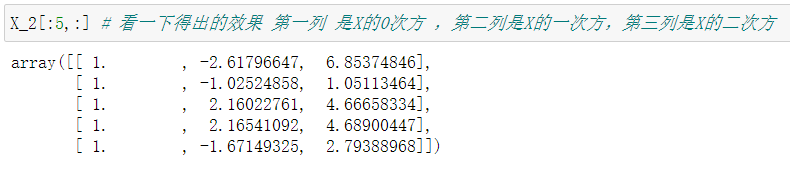
我相信大家一看注释就明白了,这个PolynomialFeatures类的功能是相当强大的!它直接从0
到最高次幂的所用数据情况都给你整合到一个矩阵里面,非常的方便!那么如果是多元函数方程呢?又怎么重整数据,别急,我们先把这个当前的任务完成。。
(3)后面拟合曲线与画图的方式都和前main讲的一模一样:
from sklearn.linear_model import LinearRegression #再引用 这个实现预测
lin_reg_2 = LinearRegression()
lin_reg_2.fit(X_2,y)
y_predict_2 = lin_reg_2.predict(X_2)
plt.scatter(x,y) #画图
plt.plot(np.sort(x),y_predict_2[np.argsort(x)],color = 'r')
plt.show()

完美!
2. 关于PolynomialFeatures
以上都是一元函数的拟合与预测,多元呢?
(1)我们新建一个多列的矩阵:
X = np.arange(1,11).reshape(-1,2)
X的多元数组就是这样的,第一列代表
,第二列代表
:

(2)使用 PolynomialFeatures数据重整:
poly = PolynomialFeatures(degree = 2)#这里的 degree 为我们需要拟合函数的最高次幂
poly.fit(X)
X2 = poly.transform (X)
我们猜一猜会得到几行几列的新矩阵勒?
 第一行还是X的0次方,第二,第三行显然是我们的原始数据列,第四和第五行我们很容易想到是
和
第五行是怎么来的!灵机一动,你会发现第五行就是
.
第一行还是X的0次方,第二,第三行显然是我们的原始数据列,第四和第五行我们很容易想到是
和
第五行是怎么来的!灵机一动,你会发现第五行就是
.
以此类推,如果有两个特征值,而degree=3,那么这个时候,整合后的数据有多少列呢?10项

所以, PolynomialFeatures的强大性就在于能包含所有可能的的情况!
3. pipeline了解一下~~
我们在进行多项式得数据拟合训练的时候,会先确定最高次幂(degree) 再进行数据重整,但是如果我们的degree太大,会导致比如像 1 和 之间的差距是非常大的,之后PolynomialFeatures类算法会在degree=100时产生的巨多的项中寻找我们需要的多项式的一部分,这个过程会自动的调用梯度下降法,但是数据相差过大的1与 会严重拖慢搜索进程,因此,我们还需需要在这中间插入数据归一化的过程,然后才能进行拟合,得到我们需要的曲线!这个过程是比较麻烦的,我们这里可以用这个pipeline法直接三合一,nice!
在这里说明一下:这里可能会需要机器学习中数据归一化的知识,在这里就不再说了,有不了解的小伙伴可以在CSDN上学习
(1)万年不变的数据。。。
x = np.random.uniform(-3,3,size = 100)
X = x.reshape(-1,1)
y = 0.5* x **3 + x + 2 + np.random.normal(0,1,100)
(2)接下来 调用Pipeline算法:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
poly_reg = Pipeline([
("poly",PolynomialFeatures(degree=3)),
("std_scaler",StandardScaler()),
("iin_reg",LinearRegression())
])
导入sklearn中的Pipeline类之后,注意,这里使用方法有点不一样,因为是将算法三合一,我们设置成这样:绿色的部分是我们随便写一个调用算法的命名,三个算法都需要添加到 pipeline 中.大家需要记住这个表达形式!
(3)之后就大同小异了(这里我改了函数):
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color = 'r')
plt.show()
得到的曲线图为:

好!本次的博客学习就结束了哦,下篇博客我们继续会深入学习多项式回归与模型泛化,觉得博主讲的还算比较详细负责的话,点点赞,谢谢大家!