Random Forest
随机森林实际上是一种特殊的bagging方法,它将决策树用作bagging中的模型。
随机森林就是对决策树的集成,但有两点不同:
(1)采样的差异性:从含m个样本的数据集中有放回的采样,得到含m个样本的采样集,用于训练。这样能保证每个决策树的训练样本不完全一样。
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。
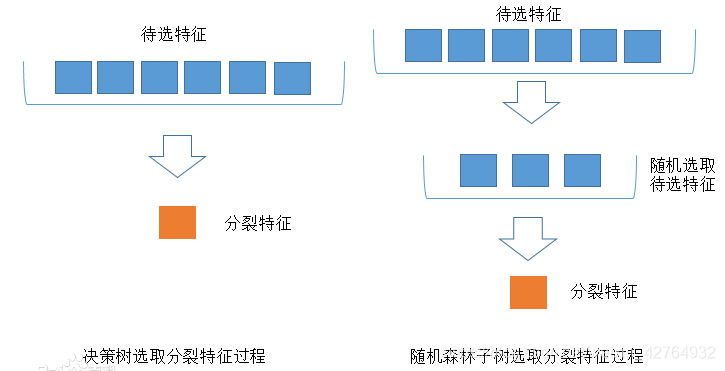
(2)特征选取的差异性:每个决策树的n个分类特征是在所有特征中随机选择的(n是一个需要我们自己调整的参数)
随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
rfc = RandomForestClassifier(n_estimators=20,max_depth=None,random_state=0)
# n_estimator树的个数,
rfc = rfc.fit(Xtrain,Ytrain)
score_r = rfc.score(Xtest,Ytest)
rfc.predict(Xtest) # 预测类别
rfc.predict_proba(Xtest) # 各类预测概率
print("Random Forest:{}".format(score_r))
每一个样本被抽到某个子集中的概率为(1减n次都没抽中的概率):
1 − ( 1 − 1 n ) n 1-(1-\frac{1}{n})^n 1−(1−n1)n
lim n → ∞ ( 1 − ( 1 − 1 n ) n ) = ( 1 − 1 e ) = 0.632 \displaystyle\lim_{n\to\infty}(1-(1-\frac{1}{n})^n)=(1-\frac{1}{e})=0.632 n→∞lim(1−(1−n1)n)=(1−e1)=0.632
所以一个自助集大约平均会包含63%的原始数据。会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。除了我们最开始就划分好的测试集之外,这些数据也可以被用来作为集成算法的测试集。也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据来测试我们的模型即可。
rfc = RandomForestClassifier(n_estimators=25,oob_score=True) #默认为False
rfc = rfc.fit(wine.data,wine.target)
#重要属性 oob_score_ 使用袋外数据的模型评分
rfc.oob_score_
# 当n和n_estimators都不够大的时候,很可能就没有数据掉落在袋外,自然也就无法使用oob数据来测试模型了
优点:
-
很多的数据集上表现良好,两个随机性的引入使随机森林不容易陷入过拟合;
-
能处理高维度数据,并且不用做特征选择;
-
对数据集适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
-
训练完后,能够给出那些feature比较重要;
-
训练速度快,容易并行化计算。
-
两个随机性的引入使得随机森林具有很好的抗噪声能力
-
隐含地创造了多个联合特征,并能够解决非线性问题
-
自带out-of-bag (oob)错误评估功能
缺点;
-
在噪音较大的分类或回归问题上会出现过拟合现象;
-
对于不同级别属性的数据,级别划分较多的属性会对随机森林有较大影响,则RF在这种数据上产出的数值是不可信的。
-
不适合小样本,只适合大样本
-
精度较低
-
适合决策边界是矩形的,不适合对角线型的
条件
- 随机森林的基分类器是相互独立的,互不相同的
RF和GBDT对比
相同点:
- 都是由多棵树组成;
- 最终的结果都是由多棵树一起决定;
不同点:
-
基于bagging思想,而gbdt是boosting思想,即采样方式不同
-
RF可以并行生成,而GBDT只能是串行;
-
输出结果,RF采用多数投票,GBDT将所有结果累加起来;
-
RF对异常值不敏感,GBDT敏感
-
GBDT和RF哪个容易过拟合?答:RF,因为随机森林的决策树尝试拟合数据集,有潜在的过拟合风险,而boosting的GBDT的决策树则是拟合数据集的残差,然后更新残差,由新的决策树再去拟合新的残差,虽然慢,但是难以过拟合。
-
组成RF的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
-
RF对训练集一视同仁,GBDT是基于权值的弱分类器的集成
-
RF是通过减少模型方差(variance)提高性能,GBDT是通过减少模型偏差(bias)提高性能
ET或Extra-Trees(Extremely randomized trees,极端随机树)
ET算法与随机森林算法十分相似,都是由许多决策树构成。
极限树与随机森林的主要区别:
-
randomForest应用的是Bagging模型,extraTree使用的所有的样本,只是特征是随机选取的,因为分裂是随机的,所以在某种程度上比随机森林得到的结果更加好
-
随机森林是在一个随机子集内得到最佳分叉属性,而ET是完全随机的得到分叉值,从而实现对决策树进行分叉的。
对于第2点的不同:
仅以二叉树为例,当特征属性是类别的形式时,随机选择具有某些类别的样本为左分支,而把具有其他类别的样本作为右分支;当特征属性是数值的形式时,随机选择一个处于该特征属性的最大值和最小值之间的任意数,当样本的该特征属性值大于该值时,作为左分支,当小于该值时,作为右分支。
这样就实现了在该特征属性下把样本随机分配到两个分支上的目的。然后计算此时的分叉值(如果特征属性是类别的形式,可以应用基尼指数;如果特征属性是数值的形式,可以应用均方误差)。遍历节点内的所有特征属性,按上述方法得到所有特征属性的分叉值,我们选择分叉值最大的那种形式实现对该节点的分叉。从上面的介绍可以看出,这种方法比随机森林的随机性更强。
对于某棵决策树,由于它的最佳分叉属性是随机选择的,因此用它的预测结果往往是不准确的,但多棵决策树组合在一起,就可以达到很好的预测效果。
当ET构建好了以后,我们也可以应用全部的训练样本来得到该ET的预测误差。这是因为尽管构建决策树和预测应用的是同一个训练样本集,但由于最佳分叉属性是随机选择的,所以我们仍然会得到完全不同的预测结果,用该预测结果就可以与样本的真实响应值比较,从而得到预测误差。如果与随机森林相类比的话,在ET中,全部训练样本都是OOB样本,所以计算ET的预测误差,也就是计算这个OOB误差。