今天一天都在弄Scrapy,虽然爬虫起来真的很快,很有效率,但是......捣鼓了一天
豆瓣电影 Top 250:https://movie.douban.com/top250
安装好的scrapy
在你想要的文件夹的目录下输入命令:
scrapy startproject douban_moive
在spiders目录下:
scrapy genspider myspider "https://movie.douban.com/top250"
和刚刚的有点不一样哦!下面来创建一个爬虫文件,最后一定要跟上一个参数,是爬虫所允许的域的范围
在该目录下对这两个进行了修改

#items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanMoiveItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
moiveinfo = scrapy.Field()
star = scrapy.Field()
quote = scrapy.Field()
douban.csv是最后生成的文件
#myspider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.contrib.spiders import CrawlSpider
from scrapy.http import Request
from scrapy.selector import Selector
from douban_moive.items import DoubanMoiveItem
from scrapy.spiders import Spider
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
#allowed_domains = ['https://movie.douban.com/top250']
#这个是可选的,不是必选的,如果后来请求的url超出这个域,则不会发送请求,我一开始就是只能请求第一页,把这个注释到以后就可以继续进行了
start_urls = ['https://movie.douban.com/top250']
url = "https://movie.douban.com/top250"
def parse(self, response):
item = DoubanMoiveItem()
selector = Selector(response)
Moives = selector.xpath("//div[@class='info']")
for each_moive in Moives:
title = each_moive.xpath('div[@class="hd"]/a/span/text()').extract()
full_title = ""
for each in title:
full_title += each
moiveinfo = each_moive.xpath(".//p/text()").extract()
star = each_moive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = each_moive.xpath('div[@class="bd"]/p/span/text()').extract()
quote = quote[0] if quote else None
item["title"] = full_title
item["moiveinfo"] = ";".join(moiveinfo).replace(' ', '').replace('\n', '')
item["star"] = star
item["quote"] = quote
yield item
nextPage = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextPage:
nextPage = nextPage[0]
print(self.url + str(nextPage))
yield Request(self.url + str(nextPage), callback=self.parse)执行如下命令:就可以在当前目录下得到一个douban.csv的文件 ,用excel打开


处理方法是:在打开前先用记事本打开,以utf-8的形式另存为,覆盖掉原来的文件

再次打开excel,就可以正常显示了
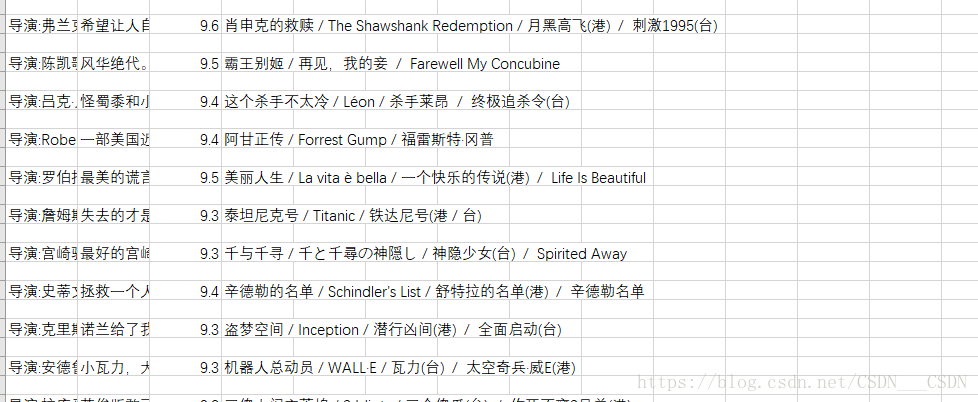
再以star列进行降序的排序,可以得到250部电影按得分由高到低的排序
