直接上代码,主要2个函数,一个是获取每个电影的详情页URL的函数,一个是处理电影详情页数据的函数。
import requests
from bs4 import BeautifulSoup
import time
start_url = 'https://movie.douban.com/top250'
movie_url = []
#连接太多会被拒绝,限制在5个
requests.adapters.DEFAULT_RETRIES = 5
def get_url(url):
global movie_url, start_url
resp = requests.get(url)
soup = BeautifulSoup(resp.text,'lxml')
info_list = soup.find_all(class_='info')
for info in info_list:
movie_url.append(info.find('a').get("href"))
try:
next_link = soup.find(attrs={'rel':'next'}).get("href")
url = start_url+next_link
except:
url = None
print(url)
return url
def get_movie_info(url):
try:
resp = requests.get(url)
except:
time.sleep(5)
resp = requests.get(url)
soup = BeautifulSoup(resp.text,'lxml')
score = soup.find(attrs={'property':"v:average"}).string
rating_people = soup.find(attrs={'property':"v:votes"}).string
No = soup.find(class_='top250-no').string
title = soup.find(attrs={'property':"v:itemreviewed"}).string
movie_info = soup.find(id='info')
info_list = movie_info.text.split('\n')
for info in info_list:
if '导演:' in info:
director = info[4:]
if '编剧:' in info:
screenwriter = info[4:]
if '主演:' in info:
starring = info[4:]
if '类型:' in info:
types = info[4:].replace(' / ','/')
if '制片国家/地区:' in info:
country = info[9:].replace(' / ','/')
if '语言:' in info:
language = info[4:].replace(' / ','/')
if '上映日期:' in info:
date = info[6:].replace(' / ','/')
if '片长:' in info:
length = info[4:]
if '又名:' in info:
nickname = info[4:]
if 'IMDb链接:' in info:
IMDb = info[8:]
time.sleep(1)
try:
nickname = nickname.replace(' / ','/')
except:
nickname = ''
try:
screenwriter = screenwriter.replace(' / ','/')
except:
screenwriter = ''
try:
starring = starring.replace(' / ','/')
except:
starring = ''
try:
IMDb = IMDb.replace(' / ','/')
except:
IMDb = ''
try:
date = starring.replace(' / ','/')
except:
date = ''
try:
summary = soup.find(attrs={'class':"all hidden"}).text.strip()
summary = summary.replace('\s','').replace('\n','').replace('\u3000','')
except:
summary = soup.find(attrs={'property':"v:summary"}).text.strip()
summary = summary.replace('\s','').replace('\n','').replace('\u3000','')
movie_info_list = [No, title, score, rating_people, director,
screenwriter, starring, types, country,
language, date, length, nickname, IMDb, summary]
return movie_info_list
def main():
global movie_url
print('开始获取url')
url = get_url(start_url)
while url:
url = get_url(url)
print('url获取成功')
with open('F:/豆瓣Top250_url.txt','w',encoding='utf8') as f:
f.write('\n'.join(movie_url))
# with open('F:/豆瓣Top250_url.txt','r',encoding='utf8') as f:
# movie_url = f.read().split()
with open('F:/豆瓣Top250.txt','w',encoding='utf8') as f:
string = '排名\t电影名称\t评分\t评分人数\t导演\t编剧\
\t主演\t类型\t制片国家/地区\t语言\t上映日期\t片长\t又名\
\tIMDb链接\t剧情简介'
f.write(string)
print('开始获取电影信息:')
for i in range(len(movie_url)):
movie_info_list = get_movie_info(movie_url[i])
with open('F:/豆瓣Top250.txt','a',encoding='utf8') as f:
f.write('\n')
f.write('\t'.join(movie_info_list))
# 打印当前进度
print('\r{0}/{1}'.format(i+1,len(movie_url)), end = '')
print()
print('获取成功!')
if __name__ == '__main__':
main()
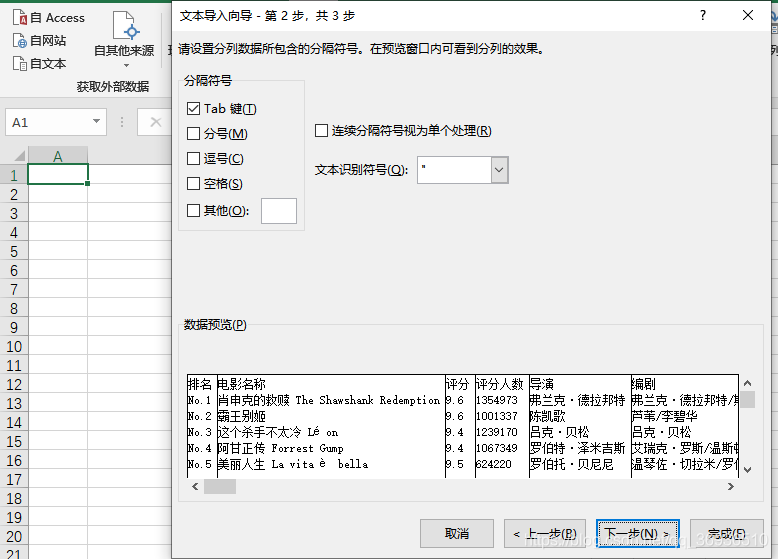
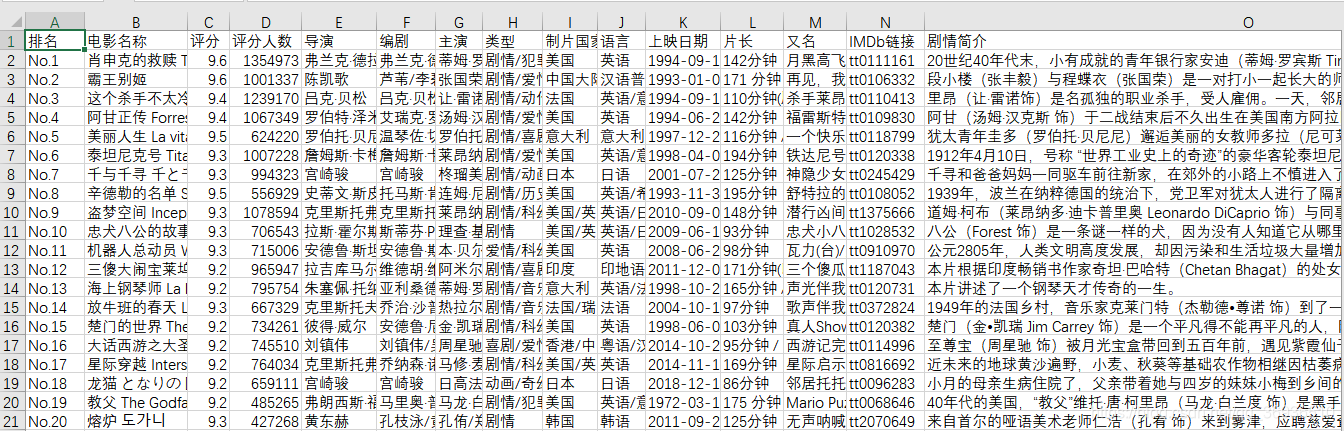
最后的文件是个txt文件,看着不是很爽,可以导入到excel中,新建一个excel选择数据自文本导入就ok了。当然也可以在代码中直接把文件保存为excel格式,这里需要用到相关的xlrd和xlwt读写excel,大家自行尝试吧。
附图:
txt版、

xlsx版、