一.storm概述
1.什么叫实时计算?流式计算?
实时计算系统的特点:源源不断,
自来水处理的流程:水源(节点)-->水泵-->沉淀-->过滤-->消毒-->输出自来水管道
上面的这些都可以看作从节点。还有一个主节点(中控室)
主从结构都会有单点故障的问题,这种时候惯用的手段是使用zookper进行协调。
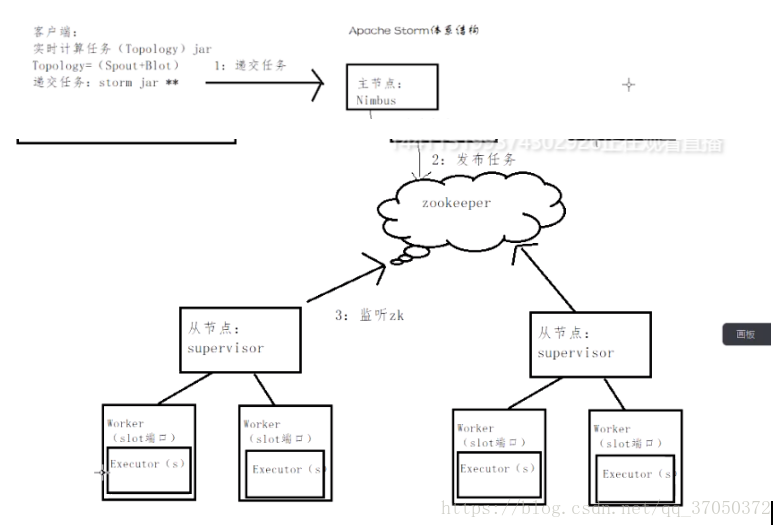
2.storm描述

3.对比离线计算和流式计算:
离线计算:mapreduce,spark core
特点:需要预先存在这些数据
强调数据的批量处理
sqoop-->hdfs-->MR(spark core) -->hdfs
实时计算:storm,jstorm(阿里基于storm开发的),spark streaming
特点:执行任务时数据可以是不存在的
强调数据的实时性
flume-->kafka-->storm(spark streaming)-->Redis(hbase)
二:Storm特点
1.编程简单:开发人员只需要关注应用逻辑
2.高性能,低延时
3.分布式
4.可扩展
5.容错:会管理工作进程和节点的故障。
6.容易在storm开发应用程序。
7.消息不丢失
三:常见的流式计算系统
1.Storm(使用clojue,java开发)目前市场占有率最高。
2.Puma:Facebook,未开源。
3.JStrom:阿里的产品(使用java开发,相当于重构了storm,比storm好很多)
4.HStreaming:基于hadoop的实时计算,未开源,有商业版和免费版
5。BaseStreaming:IBM产品,功能storm强大,多用于金融行业。
6.S4雅虎的产品,比storm性能差,多用于互联网。
7.spark streaming:建立在spark之上(不是严格的实时框架)
8.Flink第三代大数据处理引擎。
四:Storm和spark streaming对比
1.时间延迟比spark streaming低,sparkstreaming实际上是批处理
2.storm通过messageid全局跟踪记录没一条数据,storm可以多次处理同一条数据,sparkstreaming只能处理一次
五:storm的使用场景
1.实时分析:日志分析,大数据实时分析,管道传输
求TopN:求过去某个时间段内访问网站频率最高的ip
2.在线机器学习:通过我们的算法训练出来模型以后,我们的数据远远不断来了以后,可以通过我们训练出来的模型,不断的实时提供一些决策。
3.分布式RPC:(rpc就是远程过程调用)Streaming+sqout+Blot+Topology实现的计算模式。可以将storm打包出来作为独立的库
4.ETL:数清清洗,对符合条件的数据进行实施过滤,将符合条件的数据保存下来非常常见 。
六:storm的集群架构
1.storm是主从结构的,必然存在单点故障--->采用zookeeper实现HA(高可用)