1.线性回归介绍
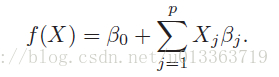
X指训练数据的feature,beta指待估计得参数。
详细见http://zh.wikipedia.org/wiki/%E4%B8%80%E8%88%AC%E7%BA%BF%E6%80%A7%E6%A8%A1%E5%9E%8B
使用最小二乘法拟合的普通线性回归是数据建模的基本方法。
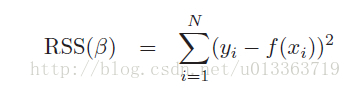
令最小二乘项的偏导为0(为0时RSS项最小),求Beta估计值,得到最小二乘的向量形式。
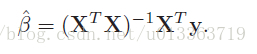
最小二乘其实就是找出一组参数beta使得训练数据到拟合出的数据的欧式距离最小。如下图所示,使所有红点(训练数据)到平面的距离之和最小。
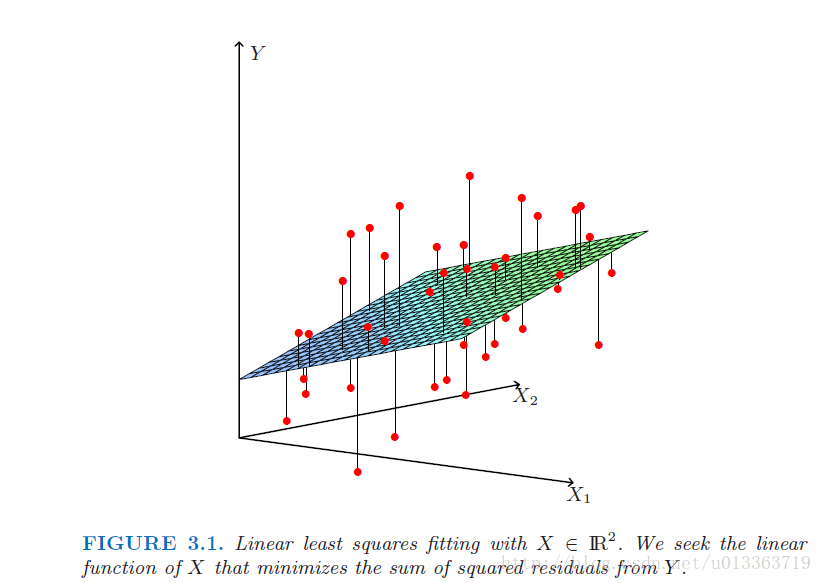
图来源(ESL p45)
最小二乘的几何解释:找到一个投影矩阵,使得y到feature矩阵的线性子空间距离最短。如下图所示

在线性模型中,存在过拟合问题(下图右一):

所以针对过拟合问题,通常会考虑两种途径来解决:
a) 减少特征的数量:
-人工的选择保留哪些特征;
-模型选择
b) 正则化
-保留所有的特征,但是降低参数的量/值;
3. 在这里我们介绍正则化方法
主要是岭回归(ridge regression)和lasso回归。通过对最小二乘估计加入惩罚约束,使某些系数的估计非常小或为0。
岭回归在最小化RSS的计算里加入了一个收缩惩罚项(正则化的l2范数)

对误差项进行求偏导,令偏导为零得:
Lasso回归

lasso是在RSS最小化的计算中加入一个l1范数作为罚约束:
-

为什么加了惩罚因子就会使得参数变低或零呢?根据拉格朗日乘法算子,这个问题可以转换成一个带约束的求极小值问题。

其收敛示意图如下所示,左是Ridge回归,右是lasso回归。黑点表示最小二乘的收敛中心,蓝色区域是加了乘法项的约束,其交点就是用相应regularization得到的系数在系数空间的表示。
