参考:https://www.cnblogs.com/jianxinzhou/p/4083921.html
线性回归中的三种形式:
注:我们讨论的线性或者非线性针对的是自变量的系数,而非自变量本身,所以这样的话不管自变量如何变化,自变量的系数如果符合线性我们就说这是线性的。所以这里我们也就可以描述一下多项式线性回归。
如:
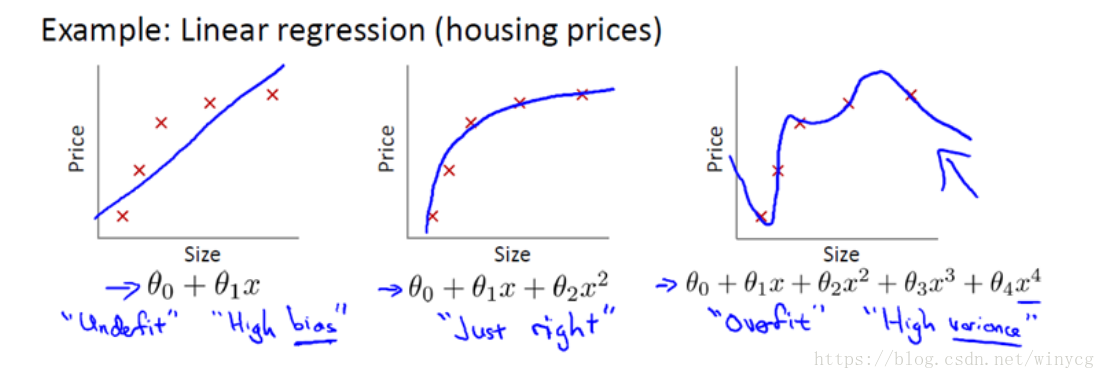
第一个模型是一个线性模型, 欠拟合,也称为 高偏差,不能很好地适应我们的训练集;第三个模型是一个四次方的模型, 过于强调拟合原始数据,而丢失了算法的本质:若给出一个新的值使之预测,它将表现的很差,是 过拟合,也称为 高方差,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类也存在如下问题:
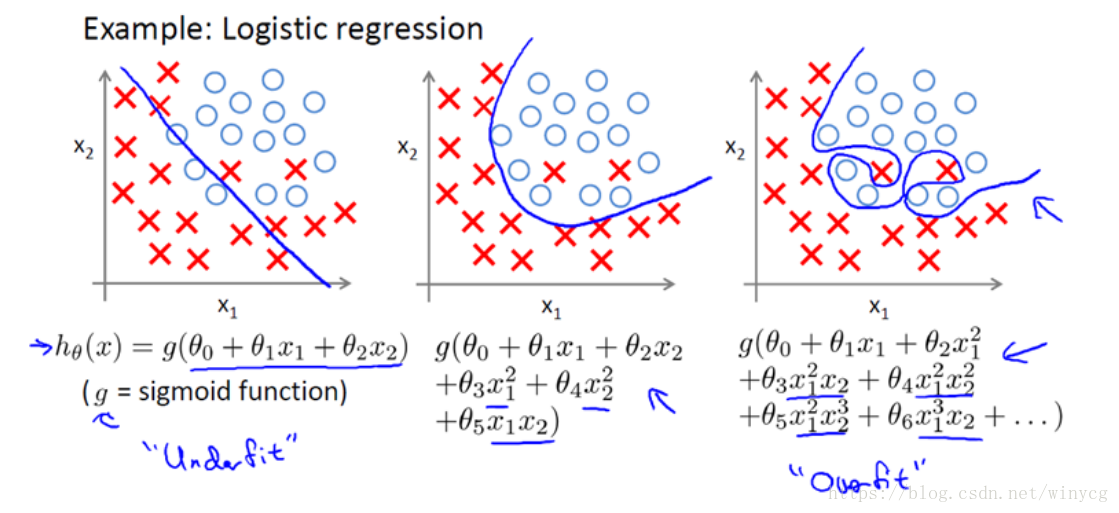
以多项式理解, x 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
L2正则化
通过对大权重增加惩罚项以降低模型复杂度的一种方法,权重向量
的
范数如下:
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。通常来说,我们不知道要惩罚哪些参数,于是在代价函数中减少所有的参数。例如在线性回归的代价函数中,加入正则化项,形式如下:
按照惯例,不会去惩罚 ,是否惩罚差异很小,但是按照惯例只会从 进行正则化。 是正则化系数,负责控制正则化的强度。
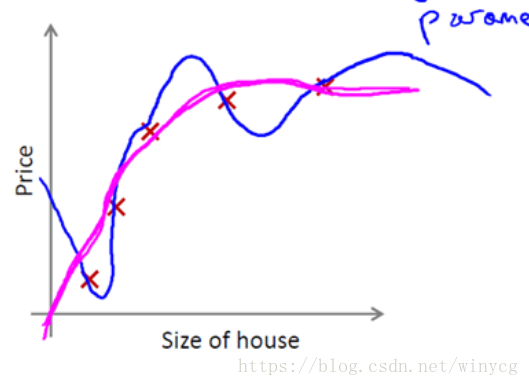
如上图,蓝线为正则化之前的效果,红线为正则化之后的效果。当 非常小时,则几乎没有发挥作用。当 较大时,会非常大的惩罚参数 ,导致函数拟合为 ,类似于拟合了一条水平的直线,相当于对数据的欠拟合。
L1正则化
将权重的平方和用权重的绝对值的和来代替,就是L1正则化:
L1正则化可生成稀疏的特征向量,且大多数的权值为0。当高维数据集中包含许多不相关的特征,尤其是不相关的特征向量大于样本数量时,权重的稀疏化处理相当于一种特征选择技术。
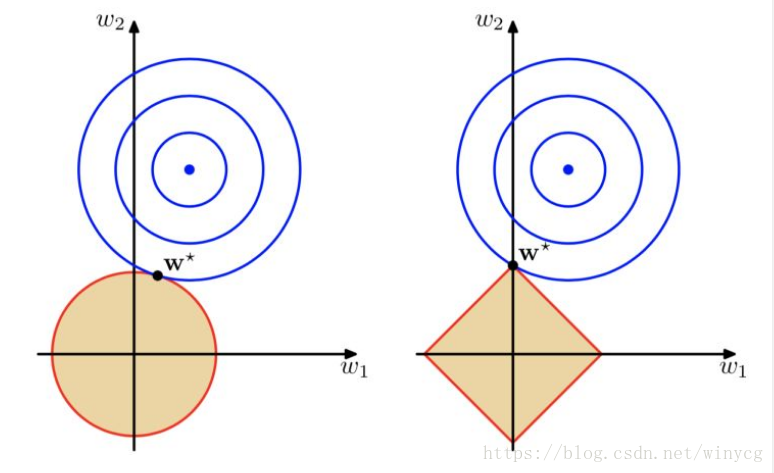
上图左侧阴影的球面表示L2正则化,在惩罚项的约束下,最好的选择就是切点
,使得代价函数和罚项之和最小。右图表示代价函数等高线与L1菱形区域在
处相交。由于L1的边界不是圆滑的,这个交点更有可能是最优的-也就是说,椭圆形的代价函数边界与L1的菱形边界的交点位于坐标轴上,使得模型更加稀疏。
针对iris数据集,使用带有L1正则化的Logistic Regression
可以看出权重向量是稀疏的,意味着只有少数几个非零项。
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
iris = datasets.load_iris()
X = iris.data[:, [2, 3]] # 维度:(150,2)
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
sc = StandardScaler()
sc.fit(X_train) # 计算训练数据的均值和标准差
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
LR = LogisticRegression(penalty='l1', C=0.1)
LR.fit(X_train_std, y_train)
print('Training accuracy:', LR.score(X_train_std, y_train))
print('Test accuracy:', LR.score(X_test_std, y_test))
print(LR.intercept_)
# 输出截距:
# [-0.44864439 -0.40546215 -0.24906672]
print(LR.coef_)
'''
输出权重数组
[[-1.84458718 0. ]
[ 0. 0. ]
[ 0. 1.50479021]]
'''