卷积
全连接层:将卷积层所有的像素展开,例如得到一个3072维的向量,然后在向量上进行操作。
卷积层:可以保全空间结构,不是展开成一个长的向量。
卷积操作:将卷积核从图像(或者上一层的feature map)的左上方的边角处开始,遍历卷积核覆盖的所有像素点。在每一个位置,我们都进行点积运算,每一次运算都会在我们输出的激活映射中产生一个值。之后根据stride值,继续滑动卷积核。例如stride为1时,一个像素一个像素地滑动。其本质也是f(x) = f(wx+b)。
卷积层意义:
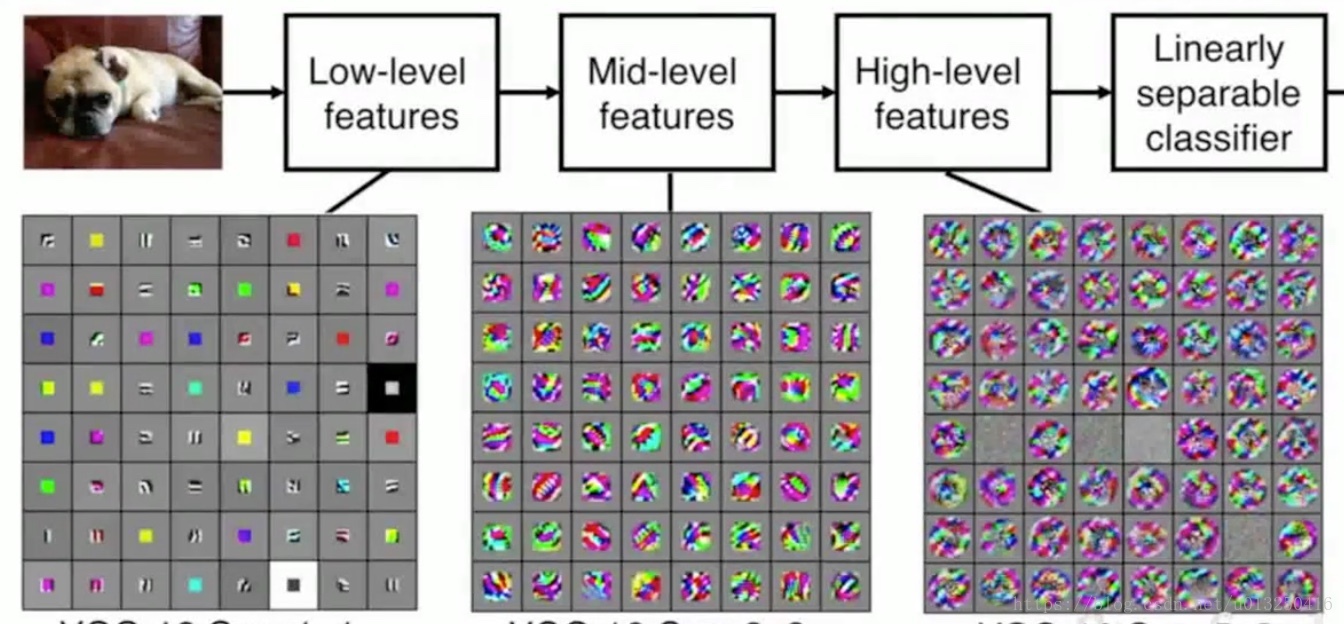
Low-level features:低层特征一般代表了一些低阶的图像特征,比如一些边缘特征;
Mid-level features:中间层可以得到一些更加复杂的图像特征,比如边角或者斑点;
High-level features:对于高阶的特征,可以获得比斑点更加丰富的内容。
这些特征是一些从简单到复杂的特征序列。
Q:零填充是否在角落上增加了一些额外的特征?
A:在边缘处是有些人为成分,但是在实际应用中这是合理的。零填充可以避免图像特征层的尺寸迅速减小,损失特征信息。
Q:对于长方形图片,是否需要使用横纵不同的步幅?
A:可以这样做。但是在实际中,我们通常操作方形区域,因此一般在长宽方向上使用同样的步幅。
Q:如何选择,保证得到想要的输出:
A:可以考虑的因素包括:卷积核的大小、卷积核的数量、步长的大小、零填充;通常选择的卷积核的大小为3*3,5*5,7*7。
Q:Input volume: 32*32*3
10 5*5 filters with stride 1, pad 2
Output size? Number of parameters in this layer?
A:Output size : (32+2*2-5)/1+1=32, 32 * 32 * 10
Parameters: 每一个卷积核的参数:5*5*3+1=76(包含偏差项)
10个卷积核的参数:76*10=760
公式:对于W1*H1*D1的输入,卷积核的数量为K,卷积核的大小为F,stride为S, padding 为 P。
那么输出W2*H2*D2满足:
W2 = (W1 + 2*P – F) / S + 1;
H2= (H2 + 2*P – F) / S +1;
D2 = K
Q:如何凭着直观感觉来确定所使用的步长呢?
A:参数数量、模型尺寸、过拟合之间的平衡。
池化
池化层:池化和普通的卷积操作一样,也是一种降采样的方式,可以让所生成的表示更小更容易控制。不会做深度方向上的池化处理,只做平面上的的池化,所以池化操作输入的深度和输出的深度是一样的。
常见的池化方式:最大池化、平均池化。对于池化,通常设定步长,使它们没有任何重叠。一般不在池化层填零,只做降采样处理。
常见的分类卷积神经网络
https://blog.csdn.net/u013250416/article/details/79591263
1.LeNet
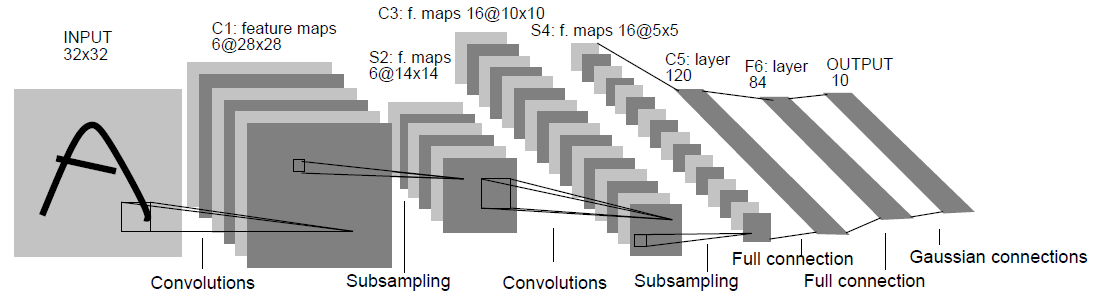
input:32*32,卷积层使用的卷积核大小均为5*5,stride=1。
应用:数字识别领域。
2.AlexNet
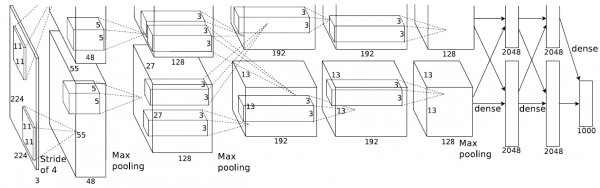
Input: 227*227*3
第一层:96个11*11,stride=4的卷积核
第一层的输出:特征层大小为(227-11)/4+1=55,输出为55*55*96
第一层的参数数目:96*(11*11*3+1)
每一个卷积核都要处理一个11*11*3的数据块,也就是分别对每一个通道的数据进行处理,然后将不同通道处理后的数据进行相加。
第二层:3*3, stride = 2
池化层没有参数
3.ZFNet
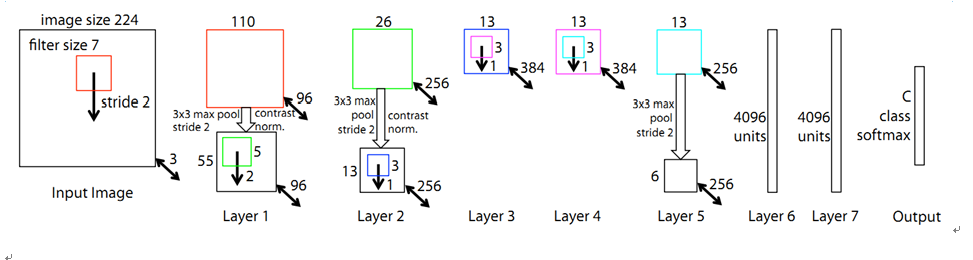
对比AlexNet在卷积核大小、卷积核数量、步长上改进
4.GooLeNet
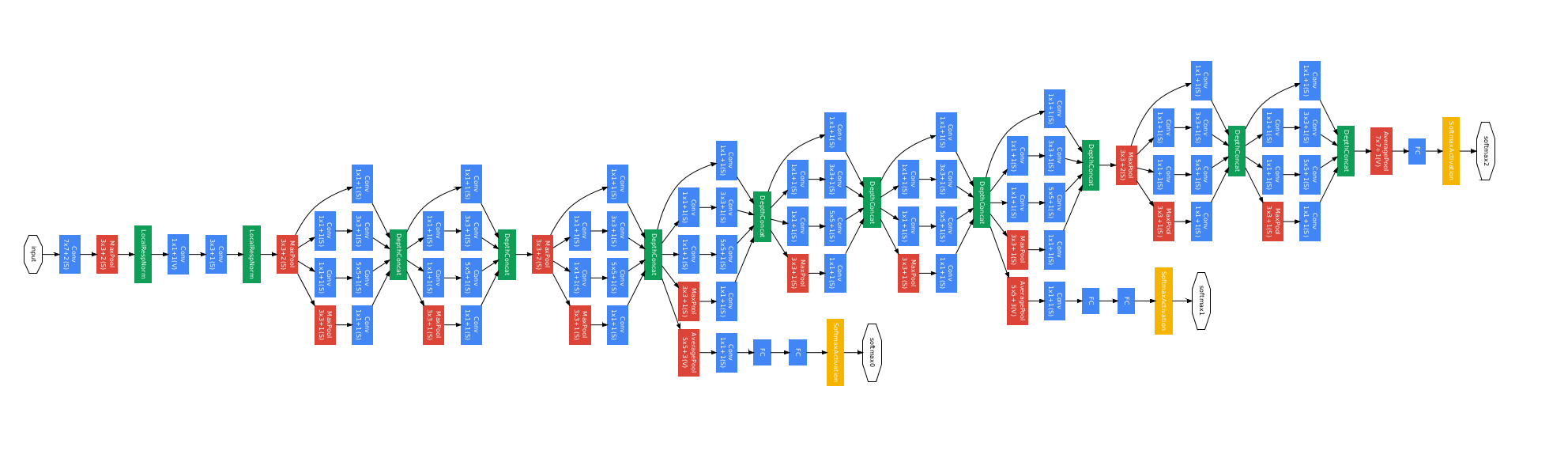
一共22层。
设计思想:Inception模块。
使用inception模块,然后每个inception模块的顶部进行输出合并。
dinception模块:对进入相同层的相同输入,并行应用不同类别的滤波操作。也就是,对输入进行不同的卷积操作,如1*1卷积,3*3卷积,5*5卷积,也有池化操作,这样就可以利用相同的输入,得到不同的输出。在inception模块的顶部,将所有的滤波器输出在深度层面上串联在一起,得到一个张量输出。这个张量将进入下一层。
简单描述,就是用不同的操作得到不同的输出,然后将这些输出串联在一起。

解决深度带来的计算资源消耗问题:
由于在inception模块中,我们通过保留相同的尺寸来扩充深度。因此,经过每一个inception模块,特征层的深度只能叠加。深度过大,会带来巨大的计算资源消耗问题。
那么,如何解决这个问题呢?
通过增加一层瓶颈层并且尝试在卷积运算之前降低特征图的维度。
例如:在卷积运算之前,使用1*1*32卷积核,将输入深度投影到一个更低的维度,相当于对特征图进行了一次线性组合。
可以使用其他的方法进行降维,为什么还要使用1*1卷积核呢?
因为1*1卷积层是和其他层一样的卷积网络,仅仅需要训练这些核心网络,再通过反向传播这个网络,即可得到训练。
5.VGGNet
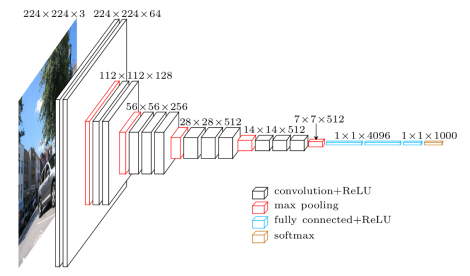
卷积层:3*3 conv stride 1, pad 1
池化层:2*2 max pool stride 2
更深的网络以及更小的卷积核
网络只关注相邻的像素
为什么使用小的卷积核?
当使用小的卷积核,可以保持较小的参数量,从而使用更深的网络和更多的卷积核。例如3个3*3的卷积核效果好于1个7*7卷积核。
6.ResNet
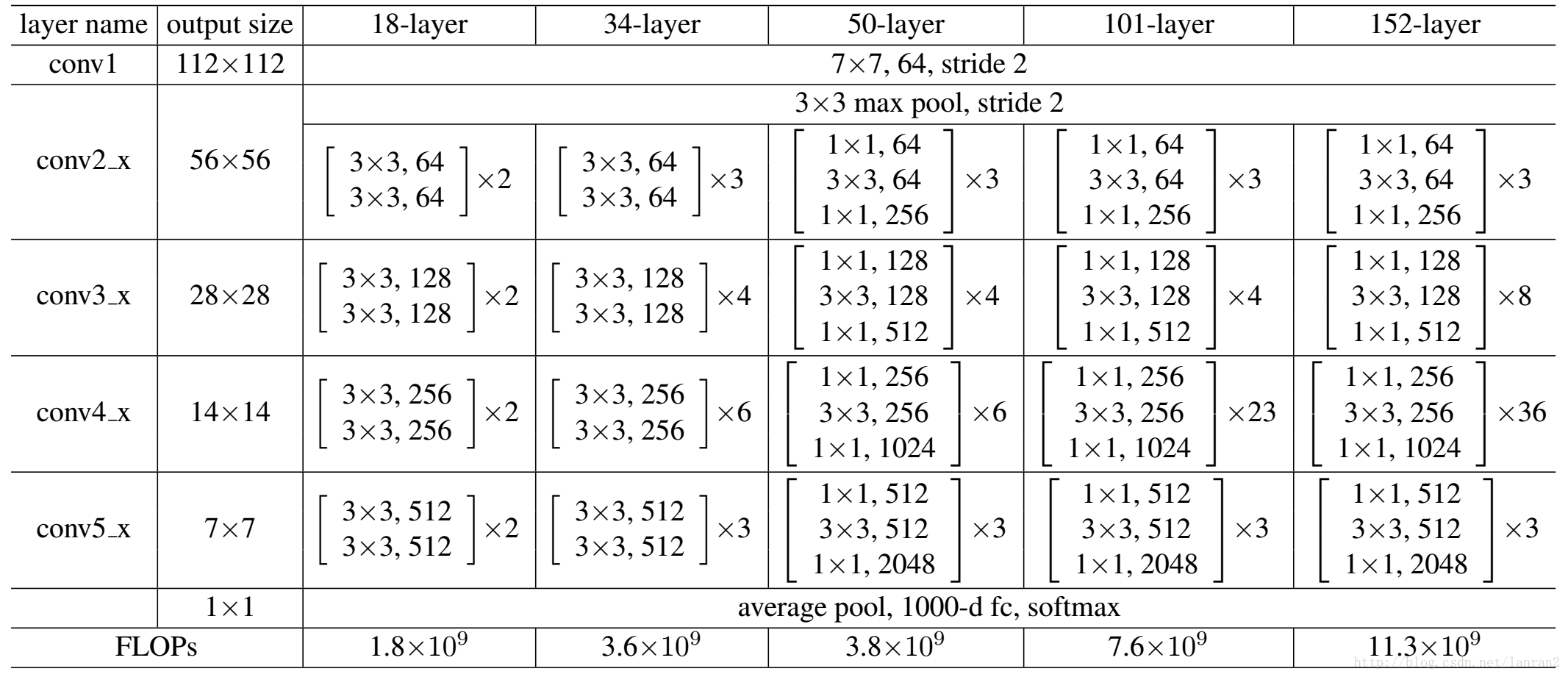
Q:当我们在普通卷积神经网络上堆叠越来越多的层时,到底会发生什么?
A:对于普通的卷积网络而言,56层的网络效果不如20层的网络。ResNet的创造者假设这是一个优化问题。相比于浅层网络,深层网络更难优化。理由是,一个深层的网络至少能和一个更浅的模型表现得一样好。
可以构造一个解决方案,一个更浅的网络,通过恒等映射,把这些拷贝到剩下的深层中。通过这个解决方案,可以使深层的网络表现的和浅层的网络一样好。
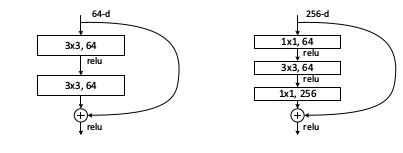
残差网络思想:
输入x,输出F(x) = H(x) - x。(原输出:H(x),也就是经过深度神经网络得到的x的非线性变换)
我们不是直接学习输出H(x),而是学习残差F(x) = H(x)-x。不是直接学习H(x),而是学习当我们移动到下一层时,需要在输入上加上或者减去什么。可以认为这是一种输入的修正。F(x)就是我们所说的残差。通过学习F(x),使得每一层的输出更接近x,它更像是修正x,而不是完全学习它应该是怎么样的。
作者假设学习残差比直接学习映射更容易。如果真的这个恒等映射是最好的,则我们只是将F(x)压缩变形为0,这个似乎更容易学习。
每个残差块都是两个3*3的卷积层。
类似GoogleNet,resnet也使用类似的瓶颈来提高效率。
7.ResNeXt
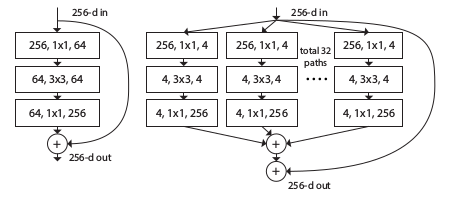
增加ResNet的宽度,不是通过增加卷积核来增加残差模块的宽度,而是在每个残差模块内建立多分支。这些分支的总和被称为基数。