深度学习总结:常见卷积神经网络(3)
之前两篇文章,主要回顾了主流的卷积神经网络,其中Alexnet,VGG,Resnet,Inception中的思想在后来很多网络结构中都有用到,个人认为他们是卷积神经网络发展的基础,后面很多复杂的神经网络都是在其基础上推陈出新的,这篇文章打算介绍Xception,SeNet,ResXext和wide Residual Networks,其他比较新的网络如Nasnet,DenseNet,Mobilenet模型较大,训练起来比较慢,不常用到,就不做详细的介绍了(其实是论文没有细看,找时间把论文看了再补充吧)。
Xception
Google 于2017年提出的Inception的终极版模型。作者在Inception的基础上,结合depthwise separable convolution,提出了Xception。卷积是在三个channel上进行学习,既要考虑空间相关性,又要考虑channel之间的相关性,但是空间相关性和channel相关性是解耦的。所以作者考虑把二者分开处理。独立的处理spatial-correlation和cross-channel-correlation,网络处理起来简单有效。由此得到如下图所示。
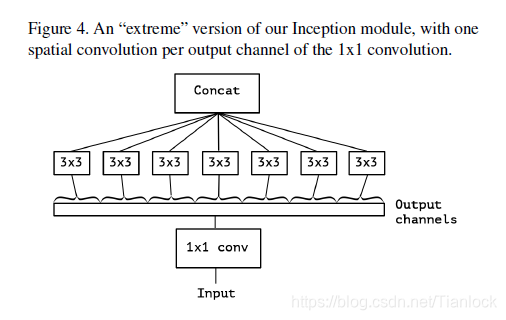
其具体操作为,首先通过1×1的卷积进行channel的解耦处理,然后在每一个channel上分别进行3×3的卷积操作,最后将结果concat。
Xception与depth separable convolution的区别
- 顺序上:depth wise separable convolutions:先进行channel-wise 空间卷积,然后1x1卷积进行融合,Xception:先进行1x1卷积,然后进行channel-wise空间卷积。
- 激活函数:depthwise separable convolution:两个操作之间没有激励函数;Xception:两个操作之间,添加了ReLU非线性激励。
上述两点,第一点不是很重要,原因是整个网络结构都是模型的堆叠,改变一下结构的顺序,两者基本上等价,第二点就比较重要了。
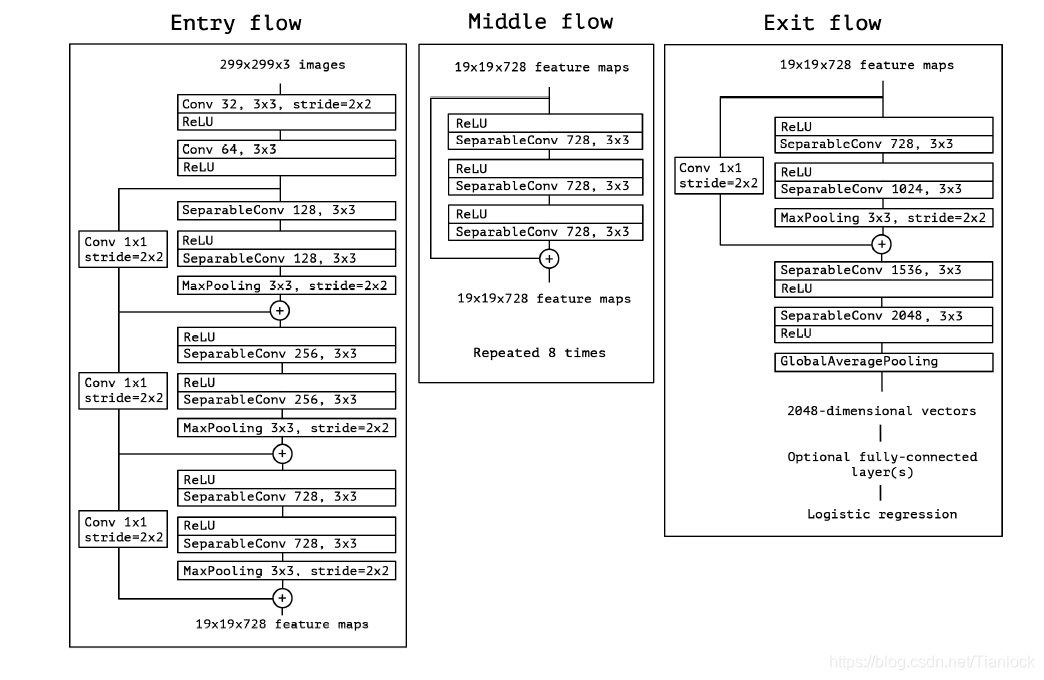
整个网络的结构如下,可以看出Xception借鉴了Resnet的思想。
SeNet
SeNet发表于2017年,该论文专注于通道(channel),提出了一个新的架构–“Sequeeze-and Excitation”。
SE机制
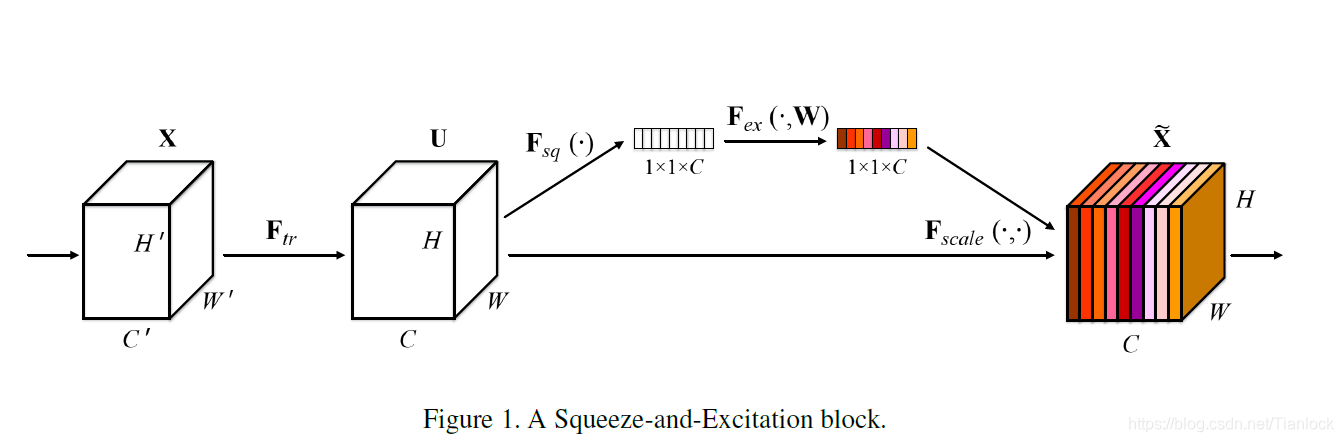
如上图所示(主要看右边,左边的Ftr其实就是卷积操作,为正常的操作,作者这么画有很大的迷惑性,我看了好久才反应过来),为SE机制。
- Squeeze:卷积其实是在卷积核的感受野范围内进行的空间相关性的学习,在特征层较大的层,受制于感受野的大小,卷积无法感知感受野之外的上下文的信息,也就是说无法具有全局的感受野。为了解决这个问题,提出了squeeze机制,其主要操作其实就是在每个channel上做了全局的池化处理,别看操作简单,其在某种程度上具有全局的感受野,表征着该通道全局的分布,使得靠近输入层的浅层也具有全局的感受野。
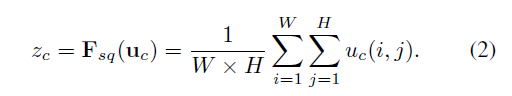
- Excitation:为了充分利用squeeze中的信息,我们通过excitation来全面获取通道间的想关性。
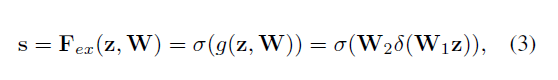
如上面的公式所述,我们对squeeze的到的全局池化的结果进行了重新的校正,其中W1和W2为全连接层, W1为降维,W2为升维。中间还有激活函数层。这样做是为了限制模型的复杂度和辅助泛化,通过在非线性的激活函数周围的全连接的瓶颈操作达到了参数化门机制。最终得到的S即为Z的reweight。
最后将重新学习到的权重S与特征U相乘,即得到了SE机制的输出。如下公式
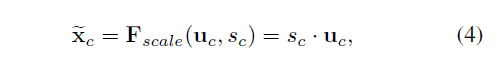
Excitation中的reweight机制,其实可以看做是特征选择(就是两个全连接层的选择)。然后将输出的权重通过乘法加权到之前的特征层中,这个权重可以看做是对应特征层的重要性,这样就完成了通道维度上的原始特征的重新标定。
另外,在较低层上,不同类别的权重几乎相同,随着网络深度的增加,变得更具有类别特定性。因为不同类别的特征在通道上有不同的偏好。
SE模块可以直接加入到现有网络中
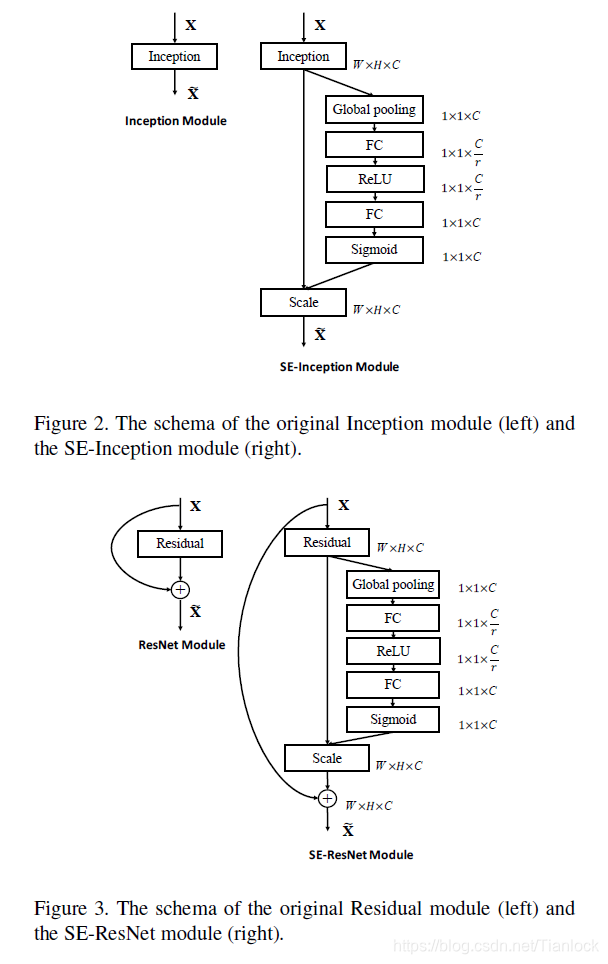
如上图所示,SE模块加入Resnet和Inception中,可以证明的是,加入SE之后,新的网络的复杂度并未增加太多(我认为是因为W1的降维机制)。
结论,SE模块可以重新校准通道间的特征,提高网络的表示能力
ResNext
ResNext依然采用的是堆叠构建快的方式进行构建,其构建快内部采用分支结构,分支的数目称为基数,作者认为,增加分支的数量比增加深度,宽度更有效。
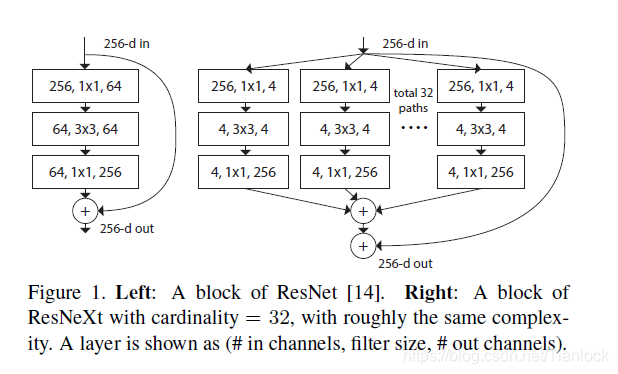
如上如所示,左面为普通的Resnet,右面为Resnext,可以看出,其32路分支的结构完全相同,最后通过权重w加权求和,得到输出。
网络结构:主要遵循特征大小不变,标准堆叠;特征大小减少,通道翻倍的策略
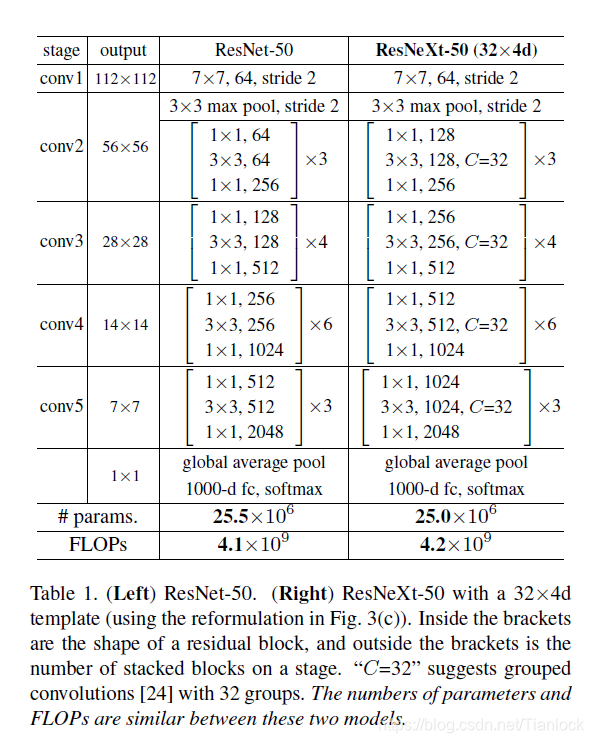
等价形式
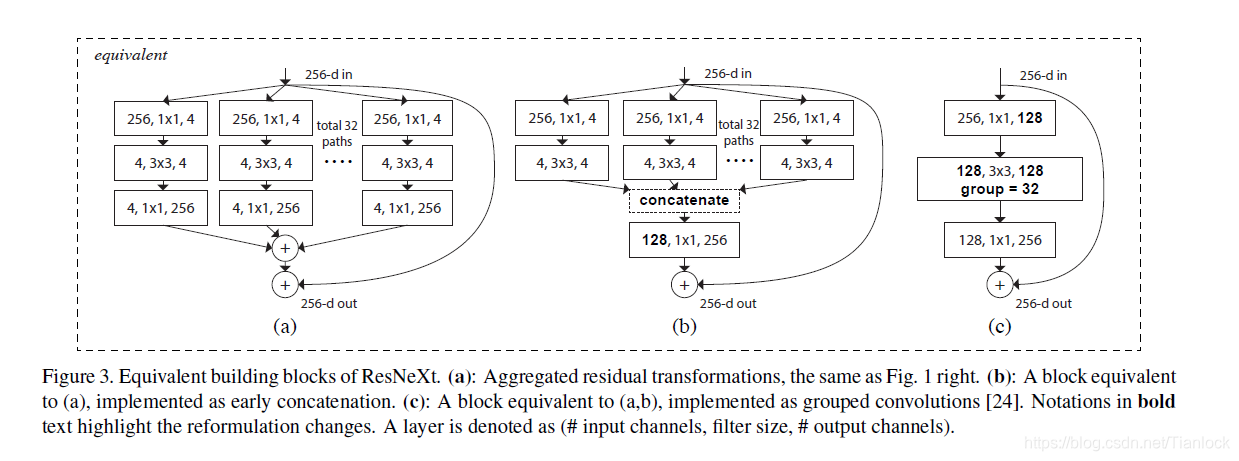
上图中等价形式,b,采用提前进行加法的操作,c提出了group convolution,将128个channel分为32个组,分别对每个组进行卷积操作。文中证明了在等价的情况下,(c)的结构简介,速度最快。
结论——贡献点:采用 aggregrated transformations(其实就是通道的聚合,也就是第一张图右边的形式。通过权重相乘求和得到聚合),实际上改变了网络的结构,用一种平行堆叠的相同拓扑结构的blocks代替原来的Resnet三层卷积的block,在不明显增加数量级的情况下提升了模型的精度,同时由于拓扑结构相同,超参数是减少的。然后通过上述三个等价的结构,利用(c)中grouped的convolution代替(a)中的拓扑聚合,实现了参数的减少,加快了速度,同时保证了模型的精度。
Wide Residual Networks
WRNs是Resnet的改良版本,论文的动机为:作者认为,随着模型深度的加深,梯度反向传播时,并不能保证能够流经每一个残差模块(residual block)的weights,以至于它很难学到东西,因此在整个训练过程中,只有很少的几个残差模块能够学到有用的表达,而绝大多数的残差模块起到的作用并不大。因此作者希望使用一种较浅的,但是宽度更宽的模型,来更加有效的提升模型的性能
结构
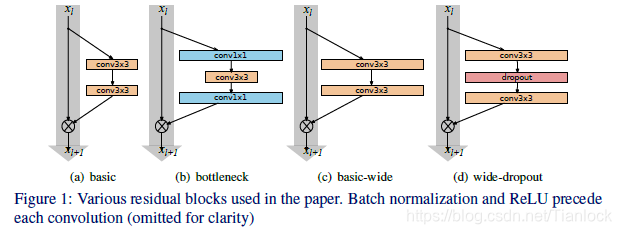
上图(c)(d)为作者提出的wide结构,除了在卷积之间加了Dropout,对比于(a)(b)的传统的Resnet看不出什么区别。
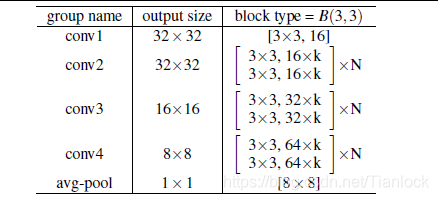
上面的表格为WRNs的的模型结构图,把表格中的k取1,其实就是Resnet中用Cifar10做实验的结构。当k取其他整数时,就得到了WRNs网络,也就是说WRNs其实就是每一层的输出channel成倍增加的Resnet。这样堆叠的N依然可以保持一个很小的值就可以使网络达到很好的效果。作者的实验表明,对比Resnet,成倍的增加channel,可以是网络的效果提升。
Dropout作者在Residual unit 中加入了dropout,也带来了性能的提升。
另外,实验表明,在模型大小即参数量相同的情况下,宽的网络比深的网络训练速度更快。这篇文章其实比较简单,就是增加了Resnet的channel数量,但也带来了模型性能的提升。
结论:实验结果也确实证明了,增加模型的宽度是对模型的性能是有提升的。不过也不能完全的就认为宽度比深度更好,两者只有相互搭配,达到合适的值,才能取得更好的效果。
本文详细介绍了四种网络,主要是介绍了创新点,具体的训练细节等以后有时间再补充。