卷积神经网络——输入层、卷积层、激活函数、池化层、全连接层
https://blog.csdn.net/yjl9122/article/details/70198357?utm_source=blogxgwz3
一、卷积层
特征提取

输入图像是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野),这里注意:感受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图;
我们通常会使用多层卷积层来得到更深层次的特征图。如下:

关于卷积的过程图解如下:
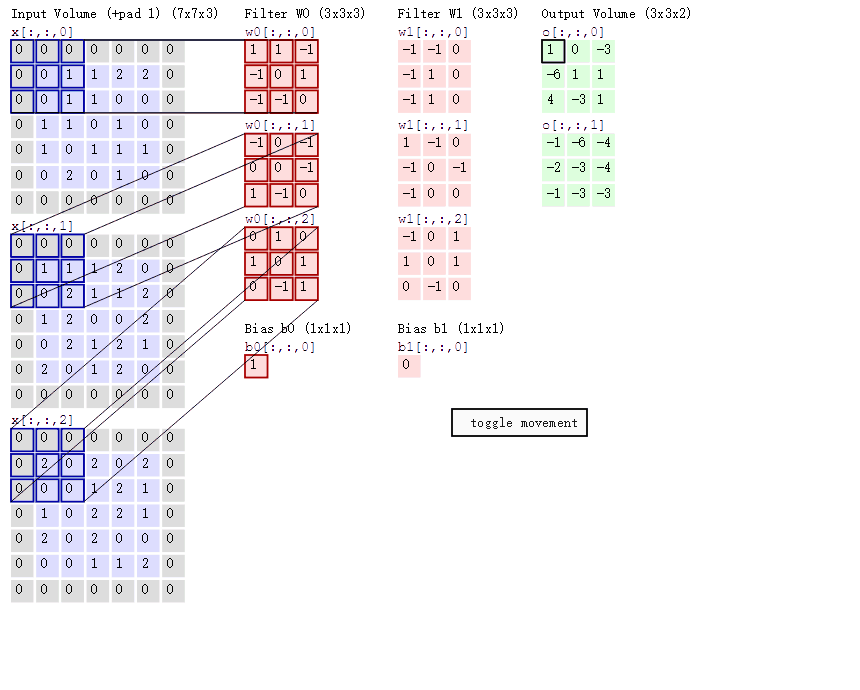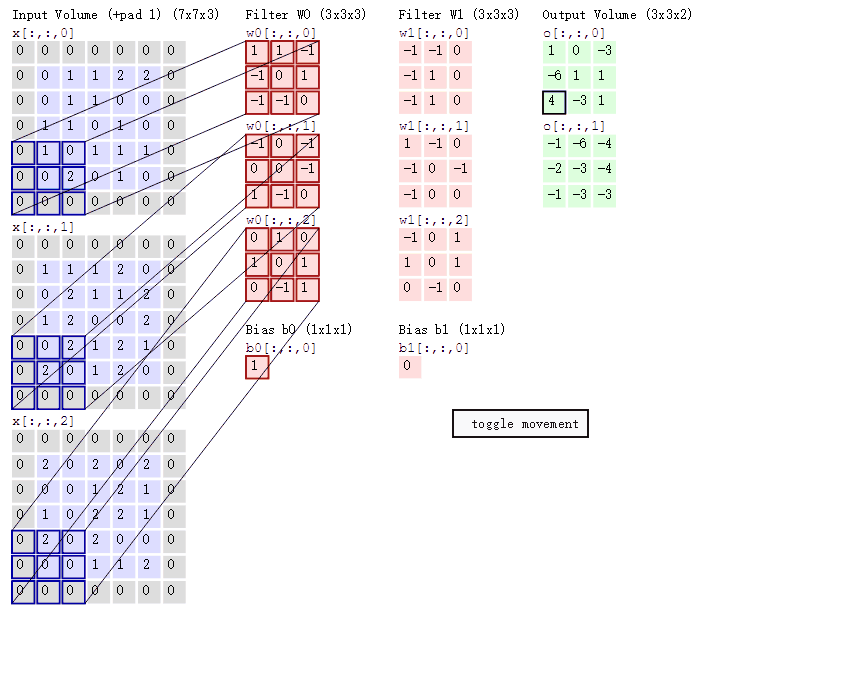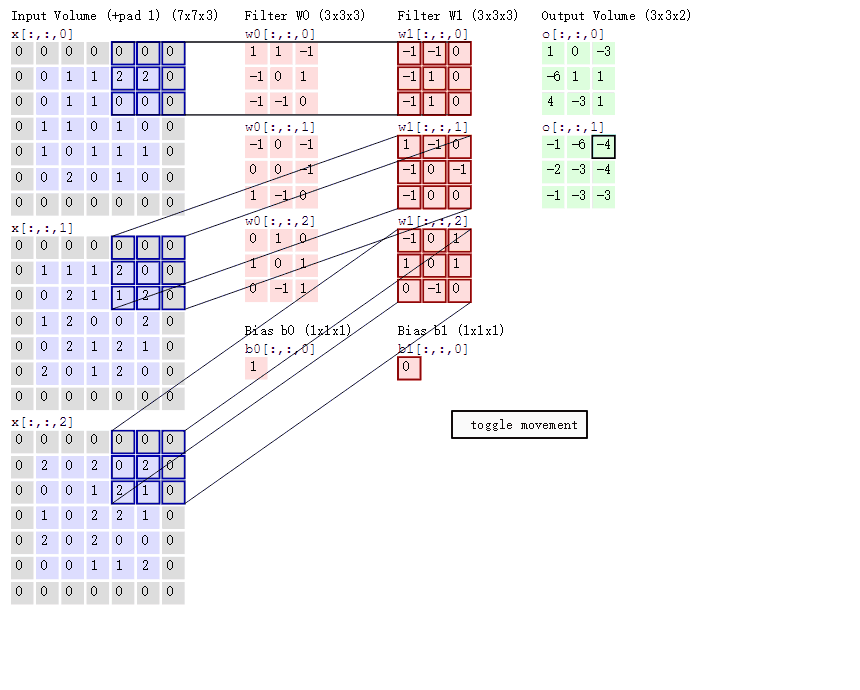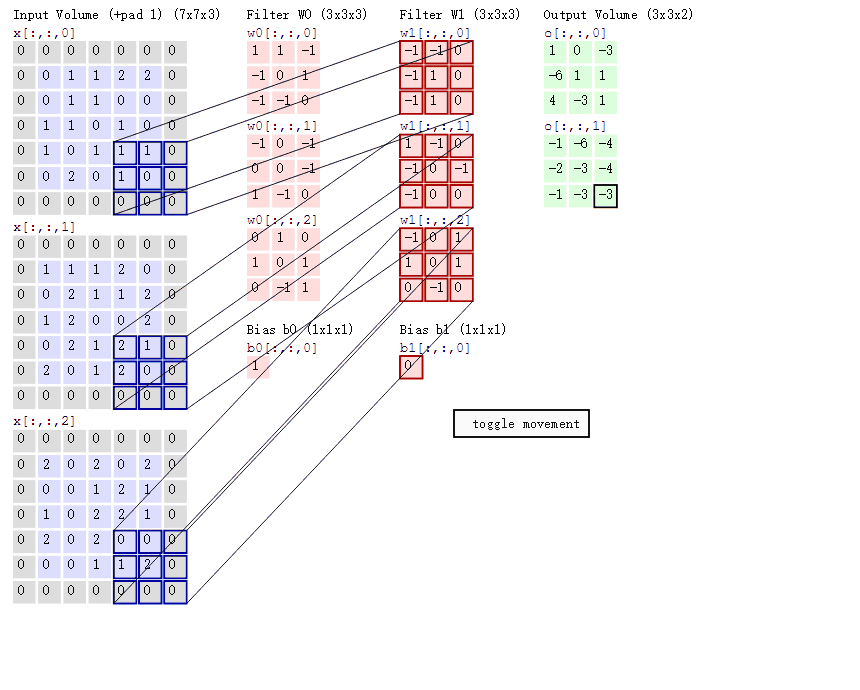
两个神经元,即depth=2,意味着有两个滤波器。
数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
zero-padding=1。
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。
左边是输入(7*7*3中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
中间部分是两个不同的滤波器Filter w0、Filter w1
最右边则是两个不同的输出
输入图像和filter的对应位置元素相乘再求和,最后再加上b,得到特征图。如图中所示,filter w0的第一层深度和输入图像的蓝色方框中对应元素相乘再求和得到1,其他两个深度得到-1,0,则有1-1+0+1=1即图中右边特征图的第一个元素1.,卷积过后输入图像的蓝色方框再滑动,stride(步长)=2,如下:
如上图,完成卷积,得到一个3*3*1的特征图;在这里还要注意一点,即zero pad项,即为图像加上一个边界,边界元素均为0.(对原输入无影响)一般有
F=3 => zero pad with 1
F=5 => zero pad with 2
F=7=> zero pad with 3,边界宽度是一个经验值,加上zero pad这一项是为了使输入图像和卷积后的特征图具有相同的维度,如:
输入为5*5*3,filter为3*3*3,在zero pad 为1,则加上zero pad后的输入图像为7*7*3,则卷积后的特征图大小为5*5*1((7-3)/1+1),与输入图像一样;
如上图,参数个数就是卷积核的大小 K *filter为3*3*3 也有 filter 是3*3*1 的卷积核
而关于特征图的大小计算方法具体如下:

卷积层还有一个特性就是“权值共享”原则。如下图:

所谓的权值共享就是说,给一张输入图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置就是被同样的filter扫的,所以权重是一样的,也就是共享。尽量减少参数个数。
二、激活函数
如果输入变化很小,导致输出结构发生截然不同的结果,这种情况是我们不希望看到的,为了模拟更细微的变化,输入和输出数值不只是0到1,可以是0和1之间的任何数,
激活函数是用来加入非线性因素的,因为线性模型的表达力不够
这句话字面的意思很容易理解,但是在具体处理图像的时候是什么情况呢?我们知道在神经网络中,对于图像,我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
这里插一句,来比较一下上面的那些激活函数,因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,运算特征是不断进行循环计算,所以在每代循环过程中,每个神经元的值也是在不断变化的。
这就导致了tanh特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果显示出来,但有是,在特征相差比较复杂或是相差不是特别大时,需要更细微的分类判断的时候,sigmoid效果就好了。
还有一个东西要注意,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,否则激活后的值都会进入平坦区,使隐层的输出全部趋同,但是 ReLU 并不需要输入归一化来防止它们达到饱和。
构建稀疏矩阵,也就是稀疏性,这个特性可以去除数据中的冗余,最大可能保留数据的特征,也就是大多数为0的稀疏矩阵来表示。其实这个特性主要是对于Relu,它就是取的max(0,x),因为神经网络是不断反复计算,实际上变成了它在尝试不断试探如何用一个大多数为0的矩阵来尝试表达数据特征,结果因为稀疏特性的存在,反而这种方法变得运算得又快效果又好了。所以我们可以看到目前大部分的卷积神经网络中,基本上都是采用了ReLU 函数。
常用的激活函数
激活函数应该具有的性质:
(1)非线性。线性激活层对于深层神经网络没有作用,因为其作用以后仍然是输入的各种线性变换。。
(2)连续可微。梯度下降法的要求。
(3)范围最好不饱和,当有饱和的区间段时,若系统优化进入到该段,梯度近似为0,网络的学习就会停止。
(4)单调性,当激活函数是单调时,单层神经网络的误差函数是凸的,好优化。
(5)在原点处近似线性,这样当权值初始化为接近0的随机值时,网络可以学习的较快,不用可以调节网络的初始值。
目前常用的激活函数都只拥有上述性质的部分,没有一个拥有全部的
1、Sigmoid函数
目前已被淘汰
缺点:
∙ 饱和时梯度值非常小。由于BP算法反向传播的时候后层的梯度是以乘性方式传递到前层,因此当层数比较多的时候,传到前层的梯度就会非常小,网络权值得不到有效的更新,即梯度耗散。如果该层的权值初始化使得f(x) 处于饱和状态时,网络基本上权值无法更新。
∙ 输出值不是以0为中心值。

2、Tanh函数
其中σ(x) 为sigmoid函数,仍然具有饱和的问题。

3、relu激活层 max(0,x)
激活函数sigmoid,但实际梯度下降中,sigmoid容易饱和、造成终止梯度传递,且没有0中心化。咋办呢,可以尝试另外一个激活函数:ReLU,其图形表示如下.ReLU的优点是收敛快,求梯度简单。

优点:
∙ x>0 时,梯度恒为1,无梯度耗散问题,收敛快;
∙ 增大了网络的稀疏性。当x<0 时,该层的输出为0,训练完成后为0的神经元越多,稀疏性越大,提取出来的特征就约具有代表性,泛化能力越强。即得到同样的效果,真正起作用的神经元越少,网络的泛化性能越好
∙ 运算量很小;
缺点:
如果后层的某一个梯度特别大,导致W更新以后变得特别大,导致该层的输入<0,输出为0,这时该层就会‘die’,没有更新。当学习率比较大时可能会有40%的神经元都会在训练开始就‘die’,因此需要对学习率进行一个好的设置。
由优缺点可知max(0,x) 函数为一个双刃剑,既可以形成网络的稀疏性,也可能造成有很多永远处于‘die’的神经元,需要tradeoff
真实使用的时候最常用的还是ReLU函数,注意学习率的设置以及死亡节点所占的比例即可
4、Leaky ReLU函数
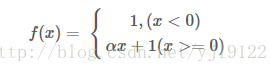
改善了ReLU的死亡特性,但是也同时损失了一部分稀疏性,且增加了一个超参数,目前来说其好处不太明确
5、Maxout函数
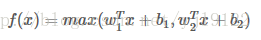
泛化了ReLU和Leaky ReLU,改善了死亡特性,但是同样损失了部分稀疏性,每个非线性函数增加了两倍的参数
三、池化层
pooling 对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征
从每层的特征,不改变层数,只改变当前层的大小
在卷积神经网络中,我们经常会碰到池化操作,而池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)。
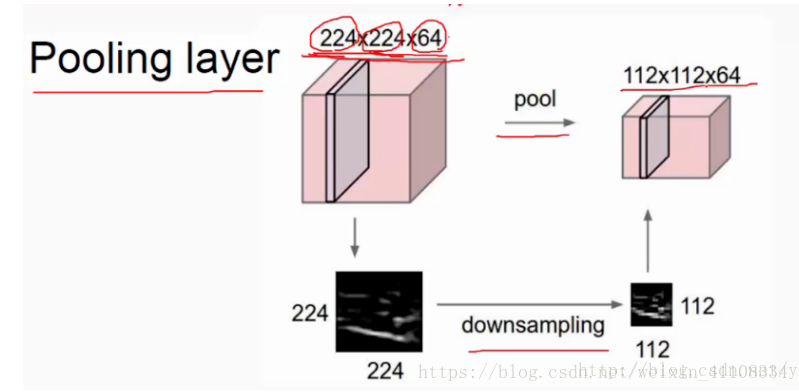
池化pooling : avy平均、 max最大
降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)
最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。

卷积层本身是个特征抽取,可以指定超参数F来制定设立多少个特征抽取器。
Poolig层对Filter层的特征进行降维操作,形成最终的特征。
一般在Pooling层后连接全连接层神经网络,形成最后的分类结果。
pooling 好处有以下几点
-
保证特征的位置与旋转不变性。对于图像处理这种特性是很好的,但是对于NLP来说特征出现的位置是很重要的。比如主语一般出现在句子头等等
-
减少模型参数数量,减少过拟合问题。2D或1D的数组转化为单一数值,对于后续的convolution层或者全连接隐层来说,减少了单个Filter参数或隐层神经元个数
-
可以把变长的输入x整理成固定长度的输入。CNN往往最后连接全连接层,神经元个数需要固定好,但是cnn输入x长度不确定,通过pooling操作,每个filter固定取一个值。有多少个Filter,Pooling就有多少个神经元,这样就可以把全连接层神经元固定住

max pooling 缺点如下
特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;另外一个明显的缺点是:有时候有些强特征会出现多次,比如我们常见的TF.IDF公式,TF就是指某个特征出现的次数,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,所以即使某个特征出现多次,现在也只能看到一次,就是说同一特征的强度信息丢失了。
空金字塔池化(Spatial Pyramid Pooling)
空间金字塔池化可以把任何尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。
一般的CNN都需要输入图像的大小是固定的,这是因为全连接层的输入需要固定输入维度,但在卷积操作是没有对图像尺度有限制,所有作者提出了空间金字塔池化,先让图像进行卷积操作,然后转化成维度相同的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像

空间金字塔池化的思想来自于Spatial Pyramid Model,它一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于卷积特征,我们可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个过滤器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征。
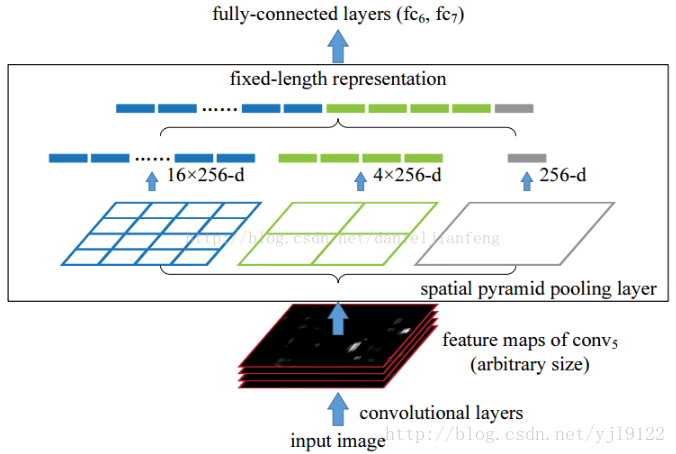
对于不同的图像要得到相同大小的pooling结果,就需要根据图像的大小动态的计算池化窗口的大小和步长。假设conv5输出的大小为a*a,需要得到n*n大小的池化结果,可以让窗口大小sizeX为,步长为 。下图以conv5输出的大小为13*13为例。
四、全连接层
连接所有的特征,将输出值送给分类器(如softmax分类器)。