学习机器学习和深度学习已经一年多了,之前一直都是用笔做记录,最近面临即将到来的春招和秋招,回过头复习之前的东西,发现很多在本子上记得不是很清晰,为了以后复习起来方便,同时全面的整理之前的东西,打算开始在博客上记录。
常见模型
Alexnet
Alexnet提出与2012年,是现代卷积网络的奠基之作,使卷积神经网络重新走入了人们的视野,Alexnet的主要创新点有:
- 首先用ReLU取代了sigmoid作为激活函数,ReLU在网络加深时的效果远远好于sigmoid函数,解决了sigmoid在网络加深时出现的梯度消失和爆炸的问题。
- 训练时加入了dropout策略,随机忽略一些神经元,以避免过拟合,起到了正则化的效果,Alexnet在网络的全连接层用到了dropout策略。
- 在CNN中开始用最大池化代替平均池化,避免了平均池化的模糊问题
- 提出了LRN层,局部响应归一化,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 加入CUDA训练,极大的提升了训练速度
- 开始加入数据增强,增加了泛化能力、
LRN详解
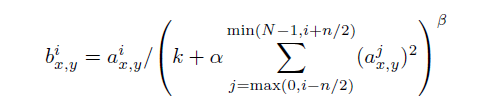
通过公式可以看出,LRN本质上是一个对数据做归一化,将响应较大的值变得相对更得,抑制较小的神经元。累加的方式是通道方向,也就是不同的通道之间相互抑制。公式中的β,n,α,k是可以设置的参数
VGG
VGG网络提出于2014年,其主要贡献点在于证明了加深网络深度有利于图像分类的准确度。其主要贡献点有:
- 反复堆叠33的卷积核加深网络的深度,33的卷积核反复堆叠的好处有三点:1扩大了感受野,两个33的卷积核堆叠相当于一个55的卷积核,3个33的卷积核相当于一个77的卷积核.2在扩大感受野的同时,尽管网络的层数增加了,但减少了网络的参数。3卷积核之间的堆叠,由于激活函数的增加,使得网络的非线性得到增强。
- 在网络中增加了11的卷积层,11的卷积层实际为线性的,但是由于激活函数的存在,实际上增加了网络的非线性。

另外VGG在训练的时候有几个trick:
- 1 单尺度训练测试 ,256*256的size大小训练测试
- 2 多尺度训练测试 ,train_size = [sizemin : sizemax], test_size = {sizemin,0.5*(sizemin + sizemax), sizemax}。
- 3裁剪训练测试 从256size中随机裁剪224大小的图片进行训练
- 4不同模型之间的融合 多种VGG之间的融合,不同尺度,不同策略,不同网络结构的融合。
Resnet
Resnet有Kaiming He提出,在VGG证明网络的加深有利于提升分类精度之后,发现了网络的深度不能一直加深,当加深到一定程度的时候,网络的训练精度和测试精度会同时下降(退化degradation问题),可以确定这不是过拟合的问题,因为过拟合在训练集的精度不会下降。为了解决这个问题,作者提出了Residual Unit.
Residual unit 详解

如上图所示,Residual unit 包含 residual mapping 和 identity mapping。最后的输出为 y = F(x) + x. 其中identity mapping是其本身,也就是x,而F(x)是y-x,也就是残差,所以残差指的是F(x)部分。
Residual unit的好处在于当网络达到最优的时候,residual mapping将为0,只剩下identity mapping,使得网络性能不回下降,而当网络没有达到最优的时候,residual mapping将会起作用,通过residual的学习提升网络性能。从另一个角度理解,卷积网络在信息传递的时候,或多或少会存在信息丢失和信息损耗的问题,resnet在某种程度上可以解决这个问题,通过直接将输入信息传到输出,保护信息的完整性,整个网络则只需要学习输入输出差别那一部分,简化了学习目标和难度。
算法细节:
- 网络结构,整个网络结构主要是基于VGG改进的。如下图所示,不同的是VGG通过池化减少featuremap,Resnet通过stride为2的卷积进行下采样。

- residual block细节:对于下图中的维度匹配问题,当x与F(x)维度相同时,y=x+F(x),当维度不同时,如虚线所示,主要有两种解决方法,(1)对x补0至同维度,(2)线性映射的方法,y = Wx + F(x)。

另外,如下如所示,对于Resnet34,采用下图左图中的Residual unit, 对于Resnet50以上深度的Resnet,采用的是下图右图中的Residual unit。右图中对Residual unit进行了降维,主要作用是减少参数,减少计算量。
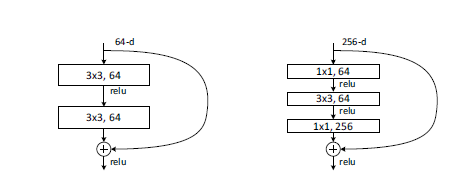
另外Resnet这种旁路支线的将输入连接到后面的层,使得后面的蹭课有直接学习残差,这种结构称为shortcut。

- Resnet在featuremap大小减半的时候,featuremap的数量增加一倍,保证了网络的复杂度
- Resnet 用全局池化global average pooling 代替全连接层,一定程度上加快了训练速度。
结论,Resnet解决了在网络加深时的退化问题,使得网络可以进一步加深。我认为是深度学习历史性的突破。