数据采集于拉钩上的数据分析师岗位,要对数据分析师这个岗位有所了解,最直观的方式就是获取企业那里获得数据分析师的岗位信息,然后进行一些探索和分析,以此来加深自己对数据分析师这个岗位的认识
简要介绍一下本次爬取数据的字段信息:city(城市),companyId(公司ID),companyShortName(公司简称),education(教育程度),industryFileld(公司领域),positionId(职位id,此值唯一),salary(薪资范围),workYear(工作年限)
下面贴上此次分析的代码及简要分析

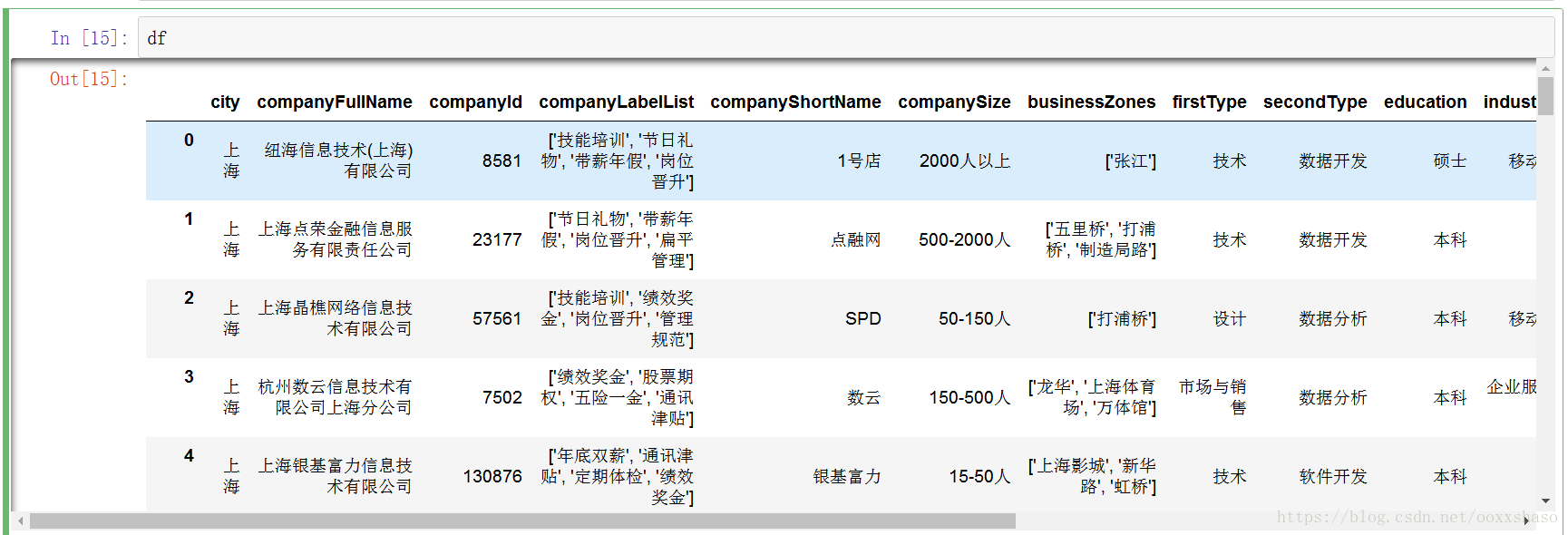
df.info()#显示出数据具有的字段信息,可以发现companyId和positionId为数字,其余均为字符串信息

c
要判断薪水的集中趋势,需要对salary字段进行清洗,计算出薪资上限和下限 想要针对pandas对象的行或列运用函数,可以使用apply()方法 salary中含有脏数据,K的大小写不确定,还有'6K以上这种写法',这里处理为上下限相同
#定义一个函数切分出薪水上下限
def cut_topsalary(salary):
pos = salary.find('-') #找出"-"所在的位置,没有的话返回-1
length = len(salary)
if pos != -1:
topsalary = salary[pos+1:length-1]
else:
topsalary = salary[:salary.upper().find('K')]#将薪水数字全部转换为K然后截取
return topsalary
df_duplicates['topsalary'] = df_duplicates.salary.apply(cut_topsalary)
df_duplicates.topsalary = df_duplicates.topsalary.astype('int')#topsalary的数据类型转换为数字
#再定义一个函数分出薪水下限
def cut_bottomsalary(salary):
pos = salary.find('-') #找出"-"所在的位置,没有的话返回-1
length = len(salary)
if pos != -1:
bottomsalary = salary[:pos-1]
else:
bottomsalary = salary[:salary.upper().find('K')]#将薪水数字全部转换为K然后截取
return bottomsalary
df_duplicates['bottomsalary'] = df_duplicates.salary.apply(cut_bottomsalary)
df_duplicates.bottomsalary = df_duplicates.bottomsalary.astype('int')然后计算出平均薪资,上面已经将top和bottom salary转换为数值类型了,这里直接求平均数即可
df_duplicates['bottomsalary'] = df_duplicates.salary.apply(cut_bottomsalary)

#先看几个描述性统计的数据
df_clean.city.value_counts()out:
北京 2347
上海 979
深圳 527
杭州 406
广州 335
成都 135
南京 83
武汉 69
西安 38
苏州 37
厦门 30
长沙 25
天津 20
Name: city, dtype: int64从以上可以看到北京招聘的数据分析师数量遥遥领先
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')#使用ggplot作为配色风格
df_clean.avg_salary.hist()
用hist函数直接绘制出直方图,图中列出了数据分析师的薪资分布,可以看出大多数位于20K以下,为了更细的粒度,将直方图宽度缩小
df_clean.avg_salary.hist(bins=15)
现在来细分维度观察,看不同城市不同学历对薪资的影响,这里采用箱线图来表现
from matplotlib.font_manager import FontProperties #导入字体管理包,因为图表默认的是英文,这里都是中文,显示的时候会出问题
font_zh = FontProperties(fname = 'C:/Windows/Fonts/simsun.ttc')#载入中文字体变量
df_box1 = df_clean.boxplot(column = 'avg_salary',by = 'city',figsize = (9,7))
for lable in df_box.get_xticklabels():
lable.set_font_properties(font_zh)
从上图我们可以看到,北上深杭的薪资的较高的,在薪资的中位数比较上,北京明显高于其他城市,值的注意的是西安的薪资中位数偏上,苏州的薪资中位数偏下,但是中位数数值大致相当,推测一下,西安的数据分析师岗位较少,招聘数据分析师的工资给的工资一般较高,有小公司招聘的数据分析师给的薪资较低,所以拉低了薪资下限,而苏州的公司给出的工资大多在10K以上,极个别给出了更高的工资,有趣的是南京的薪资中位数还不到苏州,看来南京的互联网行业还真是需要反思一下0_0
#下面看一下学历和薪资的关系
df_box2 = df_clean.boxplot(column = 'avg_salary',by = 'education',figsize = (12,10))
for label in df_box2.get_xticklabels():
label.set_fontproperties(font_zh)
可以看出博士的薪资明显高于其他学历,但在top区域上不如本科和硕士,这点在后续进行分析,大专学历在整个薪资水平上显得有些劣势
df_clean.sort_values('workYear')
df_box3 = df_clean.boxplot(column = 'avg_salary',by = 'workYear',figsize=(9,7)
)
for label in df_box3.get_xticklabels():
label.set_font_properties(font_zh)
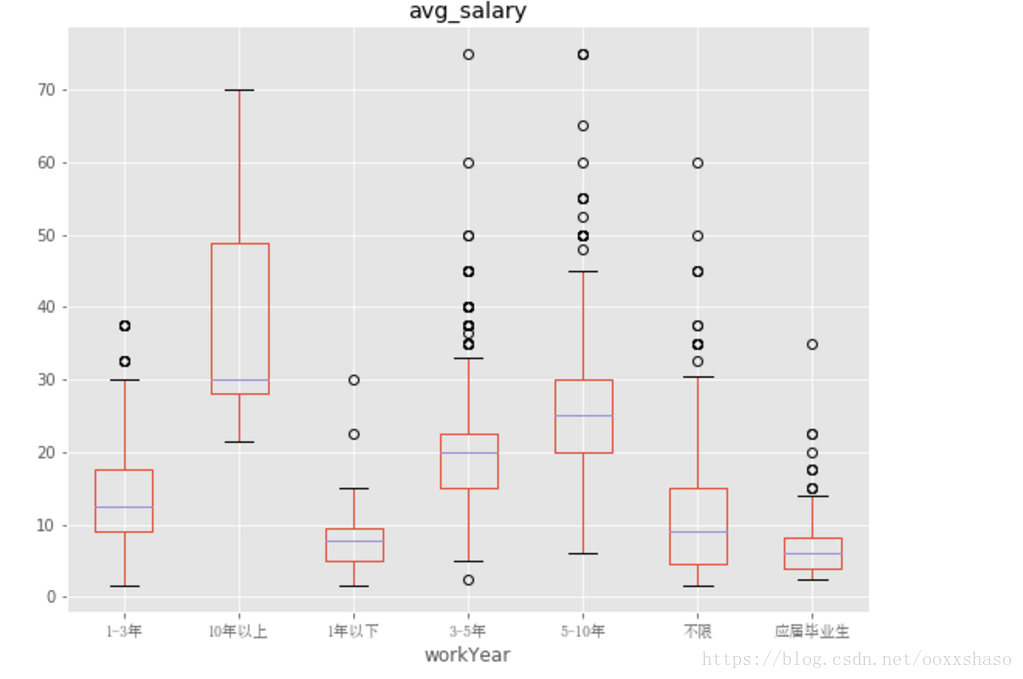
从工作年限看,工作10年以上薪资遥遥领先,工作一年以下和应届毕业生的薪资水平也较低,可以发现,随着工作年限的增长,薪资水平也在上升,可见,数据分析师在职场上的发展路线还是较好的
现在已经了解了城市,学历和工作年限对薪资的影响,但这些都是在单一变量的条件下探究的,在上面的研究中,我们也发现了一些不常见的现象,为何本科生和研究生的薪资top会超过博士生呢,为了一探究竟,我们分析北京,上海两座城市中学历对薪资的影响
df_bj_sh = df_clean[df_clean['city'].isin(['北京','上海'])]
df_box4 = df_bj_sh.boxplot(column = 'avg_salary',by = ['education','city'],figsize=(14,6)
)
for label in df_box4.get_xticklabels():
label.set_font_properties(font_zh)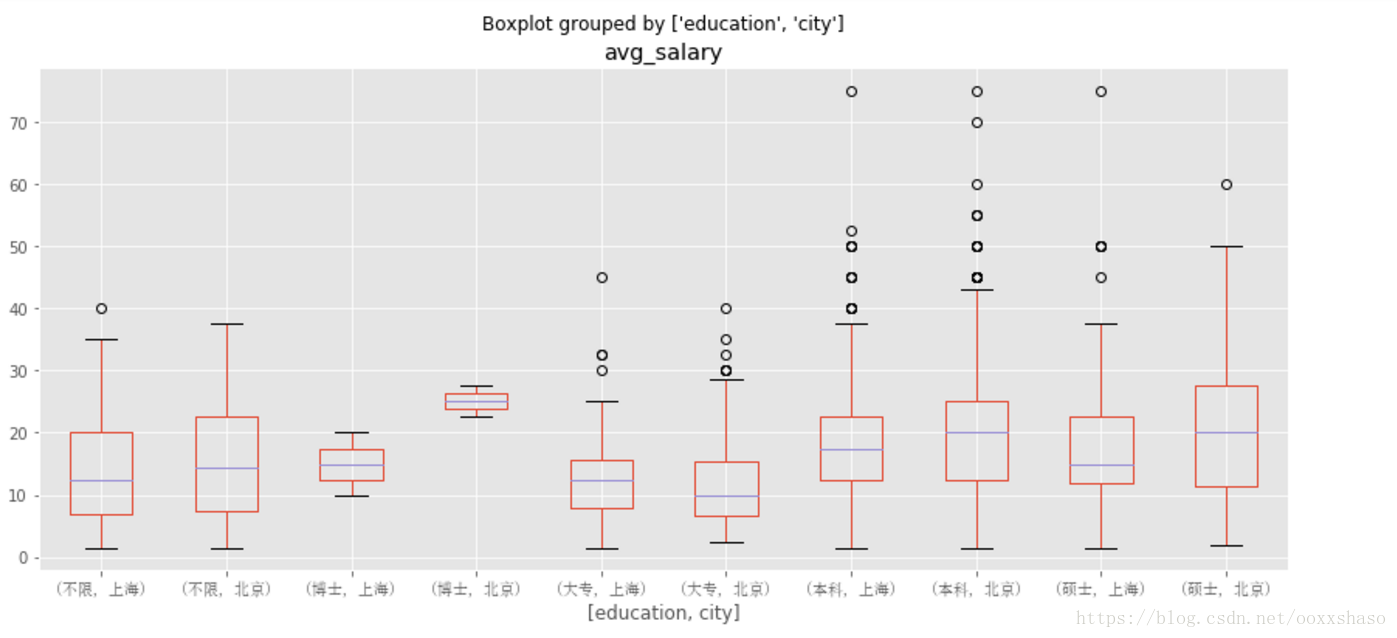
由上图我们可以发现,博士在北京的薪资明显高于上海的,且薪资高于同地区的本科和硕士薪资
df_clean.groupby('city').count()#将不同城市进行分组,并用count()方法计数
df_clean.groupby('city').mean()#看一下各个城市的平均薪资,这里只有avg_salary是数值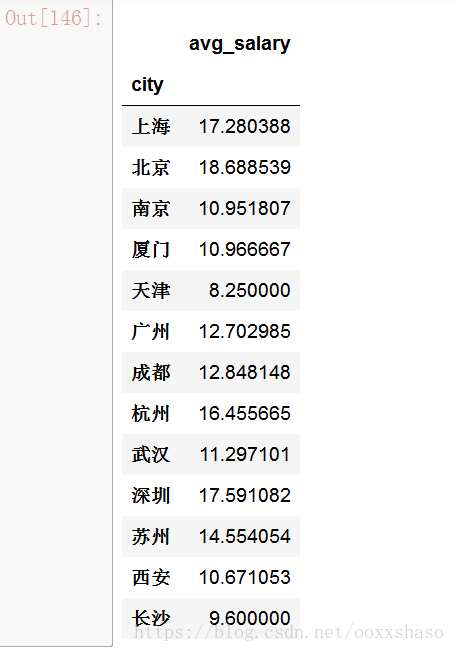
#再来看一下针对不同学历在不同城市的平均薪资
df_clean.groupby(['city','education']).mean()#这里得到了一组层次化的Series,按城市和学历进行分组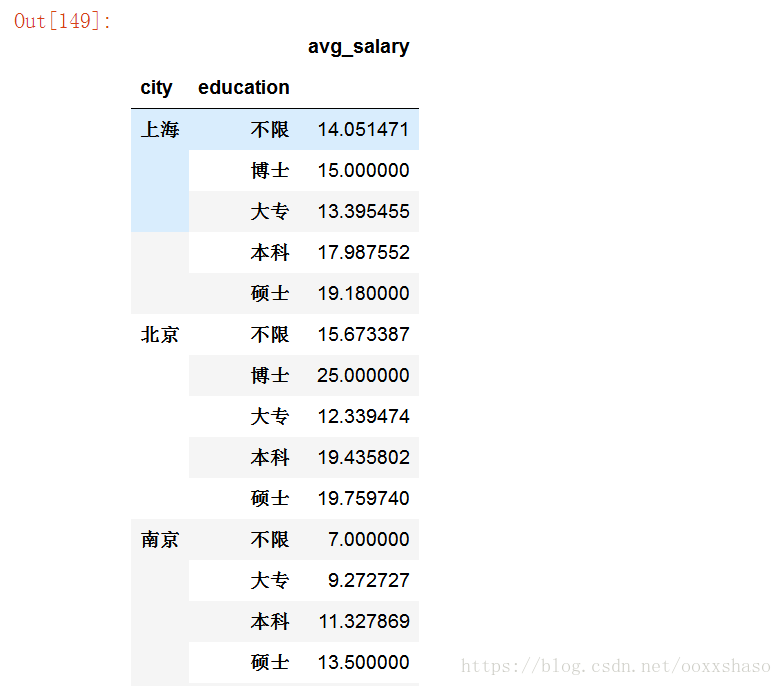
df_clean.groupby(['city','education']).mean().unstack() #将数据变为表格数据
从上表中乍一看,博士在深圳薪资最高,硕士在杭州薪资最好,综合来说北京数据分析师的薪资最高,可是,事实真的是这样吗?联想到我们一开始探究的招聘人数,好像事情没那么简单?
df_clean.groupby(['city','education']).avg_salary.count().unstack()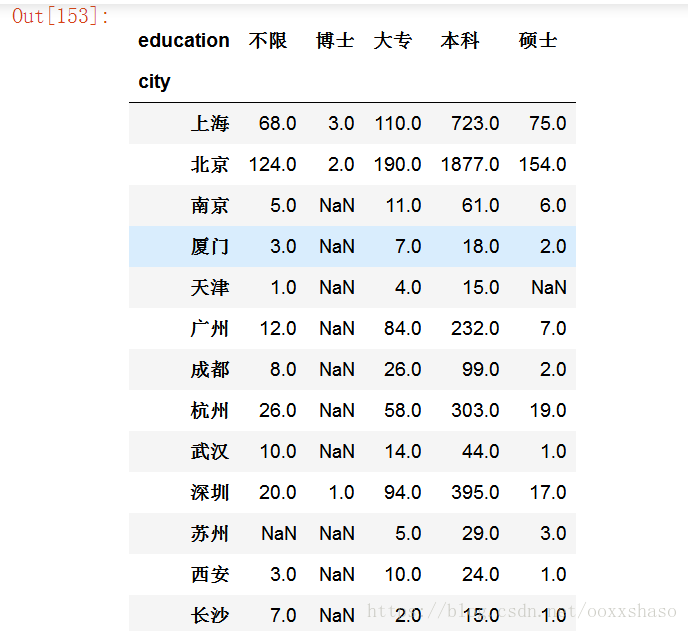
在groupby后加上一个avg_salary,表明只统计avg_salary的计数结果,从上图的结果中我们发现要求博士学位的岗位一共只有6个,因此统计的平均薪资,也只是这几家公司给博士生开出的价格,不具有代表性,也不能说明博士的真实薪资范围,这也解释了上面图表中博士工资会比硕士本科上限低的异常原因
下面看一下哪些公司在招聘数据分析师,在地域上有何分布
#agg函数传入count和mean方法,返回不同公司的计数和均值两个信息,在分组是常用agg函数来聚合,能够针对分组后的列数据进行计算
df_clean.groupby('companyShortName').avg_salary.agg(['count','mean']).sort_values(by = 'count',ascending = False)
#想列出每个城市数据分析师招聘数量最多的5家公司
def topN(df,n=5):
counts = df.value_counts()
return counts.sort_values(ascending = False)[:n]
df_clean.groupby('city').companyShortName.apply(topN)
可以看出美团在北京地区招聘的数据分析师数量一骑绝尘,招聘如此之多的数据分析师的美团又在谋划着怎样一盘大棋我们拭目以待
#同样的想知道不同城市不同职位招聘数量的前五也可以直接调用topN
df_clean.groupby('city').positionName.apply(topN)
#运用groupby,我们已经可以随意组合不同的维度,接下来配合groupby作图
df_bar1 = df_clean.groupby('city').mean().plot.bar()
for label in df_bar1.get_xticklabels():
label.set_fontproperties(font_zh)
#多重聚合在作图上面没有太大的差异,行列数据转置不要弄混淆即可
df_bar2 = df_clean.groupby(['city','education']).mean().unstack().plot.bar(figsize=(14,6))
for label in df_bar2.get_xticklabels():
label.set_font_properties(font_zh)
df_bar2.legend(prop = font_zh)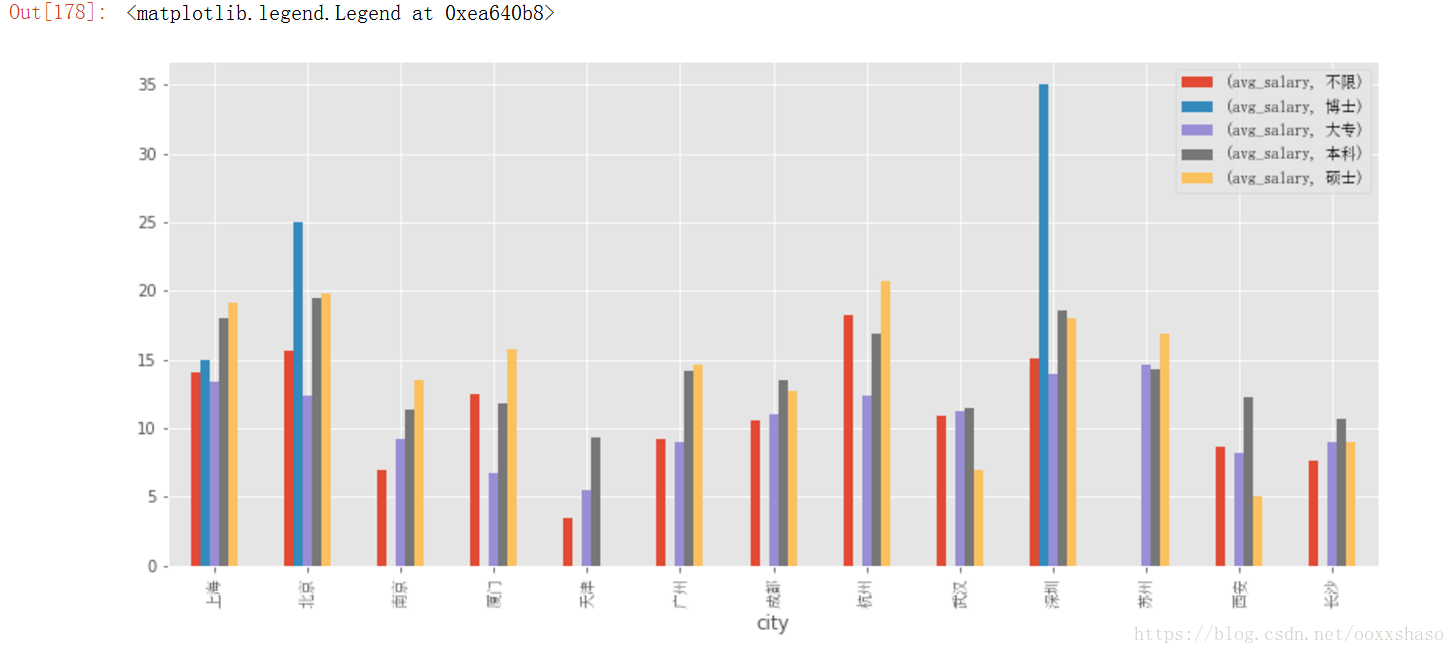
#上面的作图都是使用pandas封装过的作图方法,如果需要更自由的作图,直接调用matplotlib函数会比较好
plt.hist(x = df_clean[df_clean.city == '上海'].avg_salary,
bins=15,
normed =1,
facecolor = 'blue',
alpha = 0.5)
plt.hist(x = df_clean[df_clean.city == '北京'].avg_salary,
bins =15,
normed =1,
facecolor = 'red',
alpha =0.5
)
plt.show()
因为北京和上海的职位差距较多,无法直接对比,用normed参数将数据转化为比率来比较,比箱线图更加直观
#现在,我们利用cut来对薪资进行不同等级的划分
bins = [0,3,5,10,15,20,30,100]
level = ['0-3','3-5','5-10','10-15','15-20','20-30','30+']
df_clean['level'] = pd.cut(df_clean['avg_salary'],bins=bins,labels = level)
df_clean[['avg_salary','level']]
#将数据划分成不同等级
df_level = df_clean.groupby(['city','level']).avg_salary.count().unstack()
df_level_prop = df_level.apply(lambda x:x/x.sum(),axis =1)#转换为百分比
ax = df_level_prop.plot.bar(stacked = True,figsize =(14,6))
for label in ax.get_xticklabels():
label.set_font_properties(font_zh)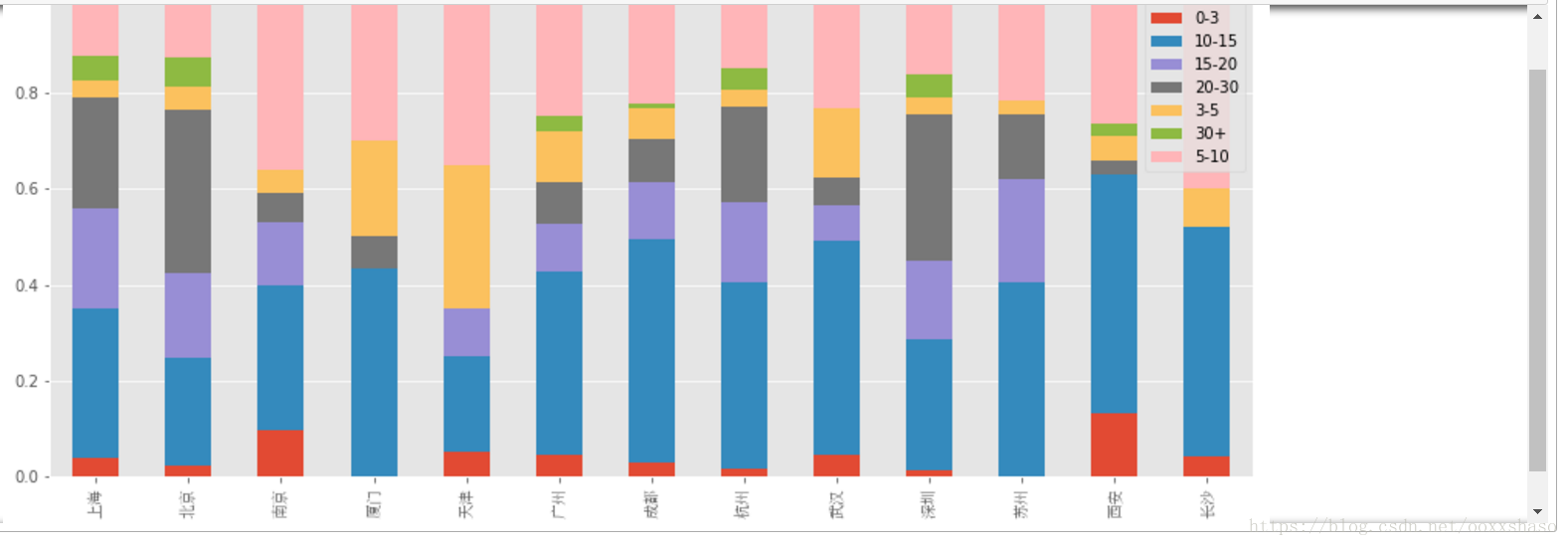
这里作堆积百分比柱形图,通过人为的划分薪资等级,可以看到不同level在不同地区的薪资多少,也具有一定的业务含义,0-3的一般是实习生的价位,再往上3-5是没有基础的新人等等.
还剩下标签数据没有处理,来看看数据分析师到底被贴了哪些标签
df_clean.positionLables
[ ]在这里是没有意义的,需要去除掉
df_clean.positionLables.str[1:-1]#去掉[],需要注意的是这里的str方法针对的是列中的元素进行的切片
word = df_clean.positionLables.str[1:-1].str.replace(' ','')
df_word = word.dropna().str.split(',').apply(pd.value_counts)#value_counts会逐行计算列表中的标签,形成一张新表
df_word.unstack()#用unstack完成行列转换,它是统计所有标签在各个职位的出现次数,绝大多数肯定是NaN
df_word.unstack().dropna().reset_index()#删除空值,此时level_0为标签名,level_1为df_index的索引,也可以认为它对应着一个职位,0是该标签在职位中出现的次数,之前我没有命名,所以才会显示0。
#用groupby计算出标签出现的次数
df_word_counts = df_word.unstack().dropna().reset_index().groupby('level_0').count()from wordcloud import WordCloud
df_word_counts.index = df_word_counts.index.str.replace(' ','')
wordcloud_show = WordCloud(font_path ='C:/Windows/Fonts/simsun.ttc', width = 900,height = 400,background_color = 'white')
f,axs = plt.subplots(figsize=(15,15))
wordcloud_show.fit_words(df_word_counts.level_1)
axs = plt.imshow(wordcloud_show)
plt.axis('off')
plt.show()
到这里,数据分析的内容也就告终了,虽然还可以做很多维度的分析,但是限于自己目前的数据分析库的运用,这次就算是初识了数据分析中常用的一些内容,今后多多练习.