导库
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r'c:\windows\fonts\simsun.ttc',size=12)
plt.style.use('ggplot')数据来自网络
读取数据
df = pd.read_csv(r'C:\Users\Administrator\Desktop\DataAnalyst.csv',encoding='gbk')该招聘信息主要包含城市、公司Id、公司规模、公司规模、招聘要求学历、薪资水平等
df.head()
因为positionID是唯一的,可以根据这个特征删除重复行
df_duplicates = df.drop_duplicates(subset='positionId',keep='first')查看salary字段,发现是一个str值,且是一个范围值,后面需要计算平均薪资,需要先拆分该字段的值并转为数值类型
df_duplicates.salary.head()0 7k-9k 1 10k-15k 2 4k-6k 3 6k-8k 4 2k-3k Name: salary, dtype: object
定义拆分函数
def cut_word(word,method):
position = word.find('-')#找到‘-’符号,存在返回位置索引,不存在返回-1
length = len(word)
if position != -1:#‘3k-4k’字样
bottomSalary = word[:position-1]
topSalary = word[position+1:length-1]
else:#‘3k以上字样’
bottomSalary = word[:word.upper().find('K')]#因为某些行的k是大写,先全转为大写,再定位
topSalary = bottomSalary
if method == 'bottomSalary':
return bottomSalary
else:
return topSalary取出最小值,新生成一列
df_duplicates['bottomSalary']=df_duplicates.salary.apply(cut_word,method='bottomSalary')转换数值类型
df_duplicates['bottomSalary'] = df_duplicates.bottomSalary.astype('float')取出最大值,新生成一列
df_duplicates['topSalary']=df_duplicates.salary.apply(cut_word,method='top')转换数值类型
df_duplicates['topSalary'] = df_duplicates.topSalary.astype('float')计算薪资的平均值并新生成一列
df_duplicates['avgSalary']=df_duplicates.apply(lambda x:(x.bottomSalary+x.topSalary)/2,axis=1)查看新生成的列
df_duplicates.head()
df_clean = df_duplicates[['city','companyShortName','companySize','education','positionName',
'positionLables','workYear','avgSalary']]df_clean.head()
EDA
1、分析教育水平和平均薪资的关系
ax = df_clean.boxplot(column = 'avgSalary',by = 'education',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(font)
plt.show()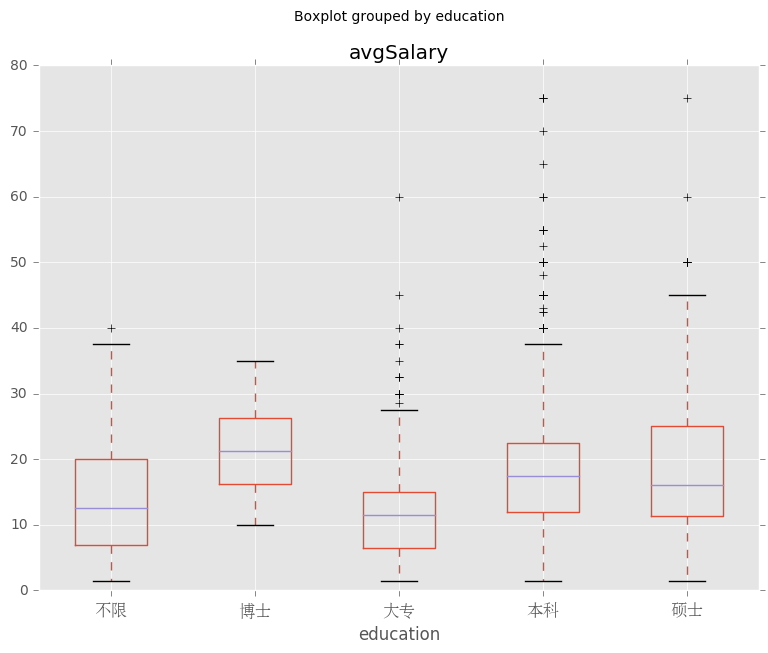
可见博士薪资水平较高,符合预期;另外本科的平均薪资要高于研究生
2、找出招聘岗位最多的公司,其平均薪资水平如何
df_clean.groupby('companyShortName').avgSalary.agg(['count','mean']).sort_values(by = 'count',ascending=False)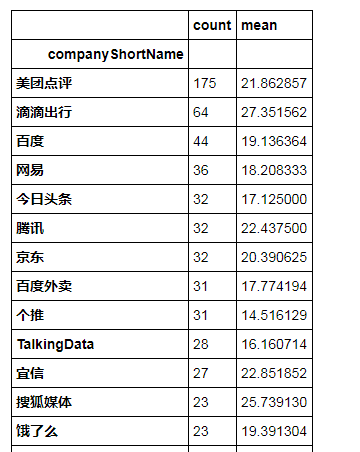
美团、滴滴、百度排在前三
3、分析不同城市招聘最多的前5名
def topN(df,n=5):
return df.value_counts().sort_values(ascending = False)[:5]df_clean.groupby('city').companyShortName.apply(topN)city
上海 饿了么 23
美团点评 19
返利网 15
买单侠 15
点融网 11
北京 美团点评 156
滴滴出行 60
百度 39
今日头条 32
百度外卖 31
南京 途牛旅游网 8
通联数据 7
中地控股 6
创景咨询 5
南京领添 3
厦门 美图公司 4
厦门融通信息技术有限责任公司 2
Datartisan 数据工匠 2
护航科技 1
咪咕动漫 1
天津 神州商龙 2
众嘉禾励 1
数极客 1
58到家 1
易商互动 1
广州 探迹 11
唯品会 9
广东亿迅 8
阿里巴巴移动事业群-UC 7
聚房宝 6
...
杭州 个推 22
网易 15
有数金服 15
同花顺 14
51信用卡管家 11
武汉 斗鱼直播 5
武汉物易云通网络科技 4
卷皮 4
榆钱金融 3
至易科技 2
深圳 腾讯 25
金蝶 14
华为技术有限公司 12
香港康宏金融集团 12
顺丰科技有限公司 9
苏州 同程旅游 10
智慧芽 3
朗动网络科技 3
食行生鲜 2
思必驰科技 2
西安 思特奇Si-tech 4
绿盟科技 3
天晓科技 3
全景数据 2
海航生态科技 2
长沙 芒果tv 4
惠农 3
思特奇Si-tech 2
网舜科技 1
共致开源 1
Name: companyShortName, Length: 65, dtype: int64
注意到杭州招聘最多的公司:个推、网易、有数金服、同花顺、51信用卡
4、分析不同城市的平均薪资
df_clean.groupby('city').avgSalary.agg('mean').sort_values()city 天津 8.250000 长沙 9.600000 西安 10.671053 南京 10.951807 厦门 10.966667 武汉 11.297101 广州 12.702985 成都 12.848148 苏州 14.554054 杭州 16.455665 上海 17.280388 深圳 17.591082 北京 18.688539 Name: avgSalary, dtype: float64
ax = df_clean.groupby('city').mean().plot(kind='bar')
for label in ax.get_xticklabels():
label.set_fontproperties(font)
plt.show()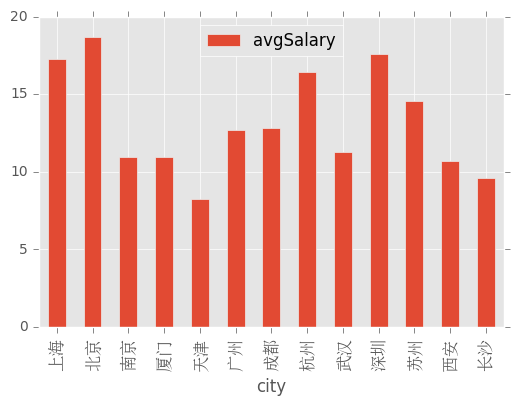
北京、上海、深圳前3,杭州第4
5、分析不同城市不同学历的薪资水平
df_clean.groupby(['city','education']).mean().unstack()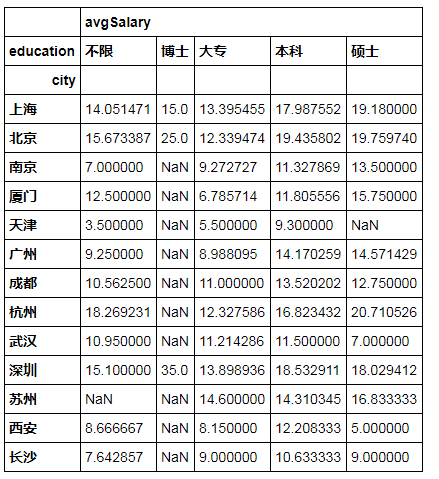
ax = df_clean.groupby(['city','education']).mean().unstack().plot(kind='bar',figsize=(14,6))
for label in ax.get_xticklabels():
label.set_fontproperties(font)
ax.legend(prop=font)
plt.show()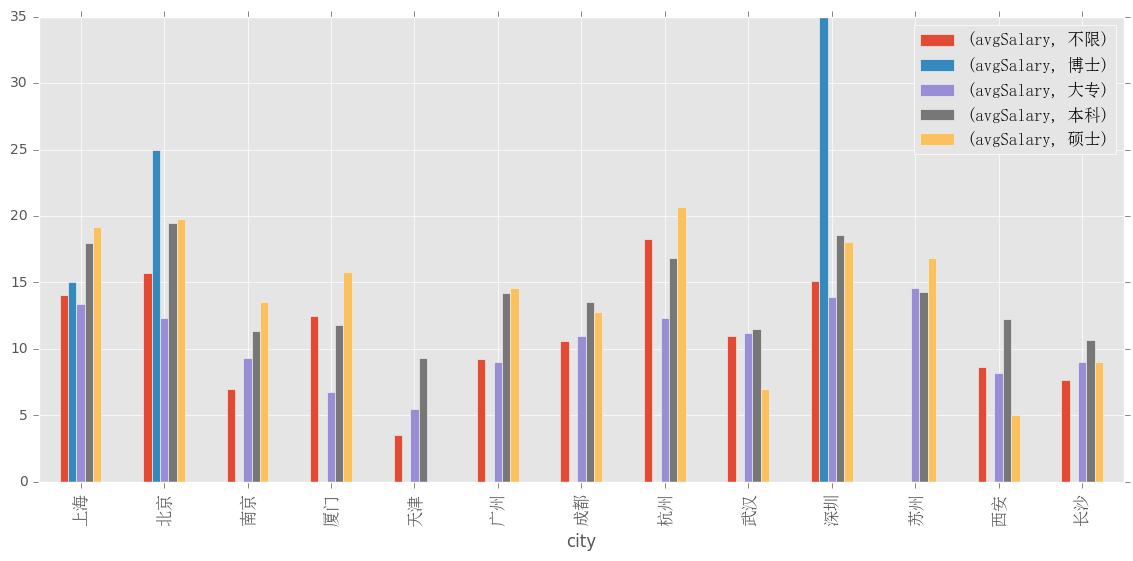
上海、北京的薪资水平普遍较高,深圳的博士薪资很高,可能是异常值或者招的人少,有价无市
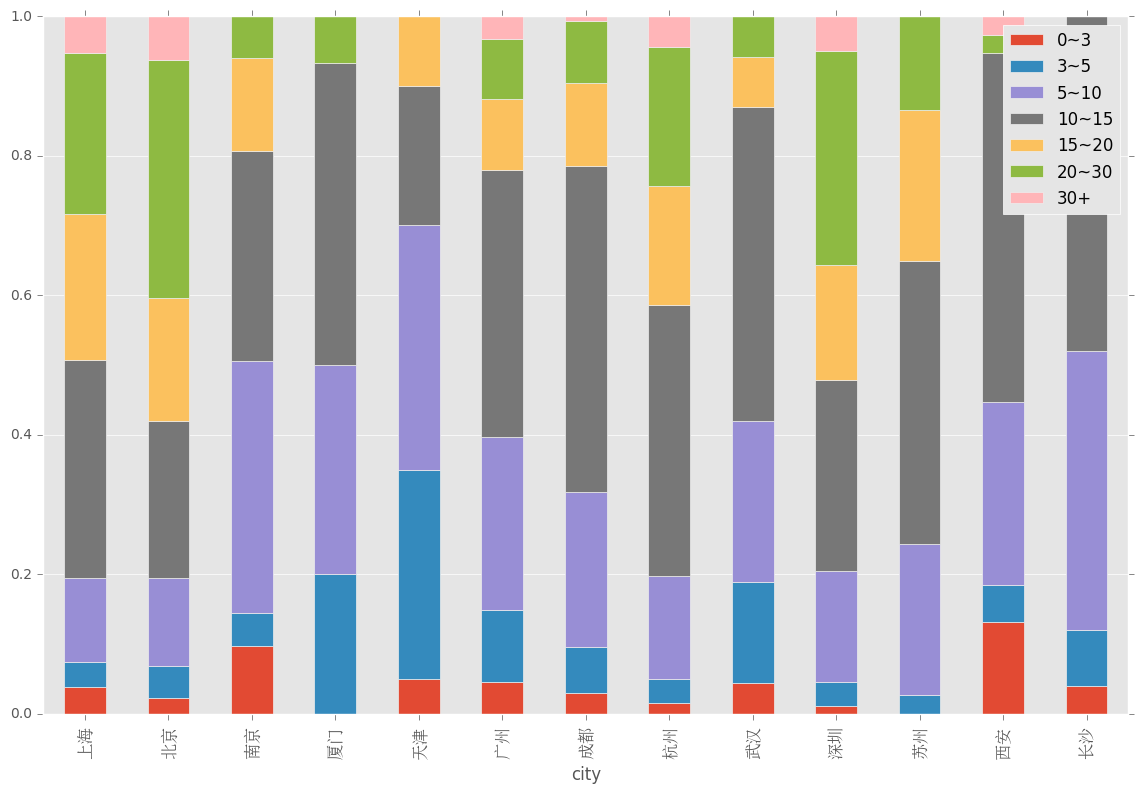
6、离散化平均薪资,绘制堆叠图
bins = [0,3,5,10,15,20,30,100]
level = ['0~3','3~5','5~10','10~15','15~20','20~30','30+']
df_clean['level']=pd.cut(df_clean['avgSalary'],bins=bins,labels = level)df_clean.groupby(['city','level']).avgSalary.count()df_clean.groupby(['city','level']).avgSalary.count().unstack()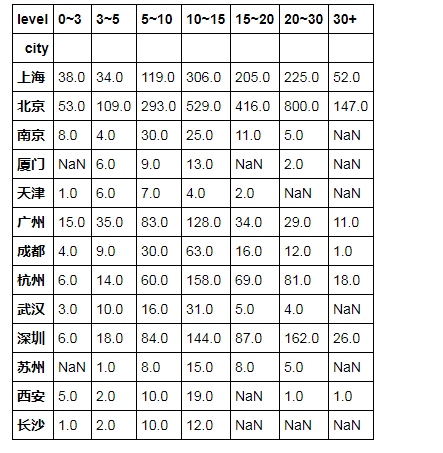
对每个城市的不同薪资水平均一化
df_level=df_clean.groupby(['city','level']).avgSalary.count().unstack().apply(lambda x:x/x.sum(),axis=1)ax = df_level.plot(kind='bar',stacked=True,figsize=(14,9))
for label in ax.get_xticklabels():
label.set_fontproperties(font)
ax.legend(loc='upper right')
plt.show()