关注微信公共号:小程在线


关注CSDN博客:程志伟的博客
import numpy as np
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
from pyecharts.globals import ThemeType
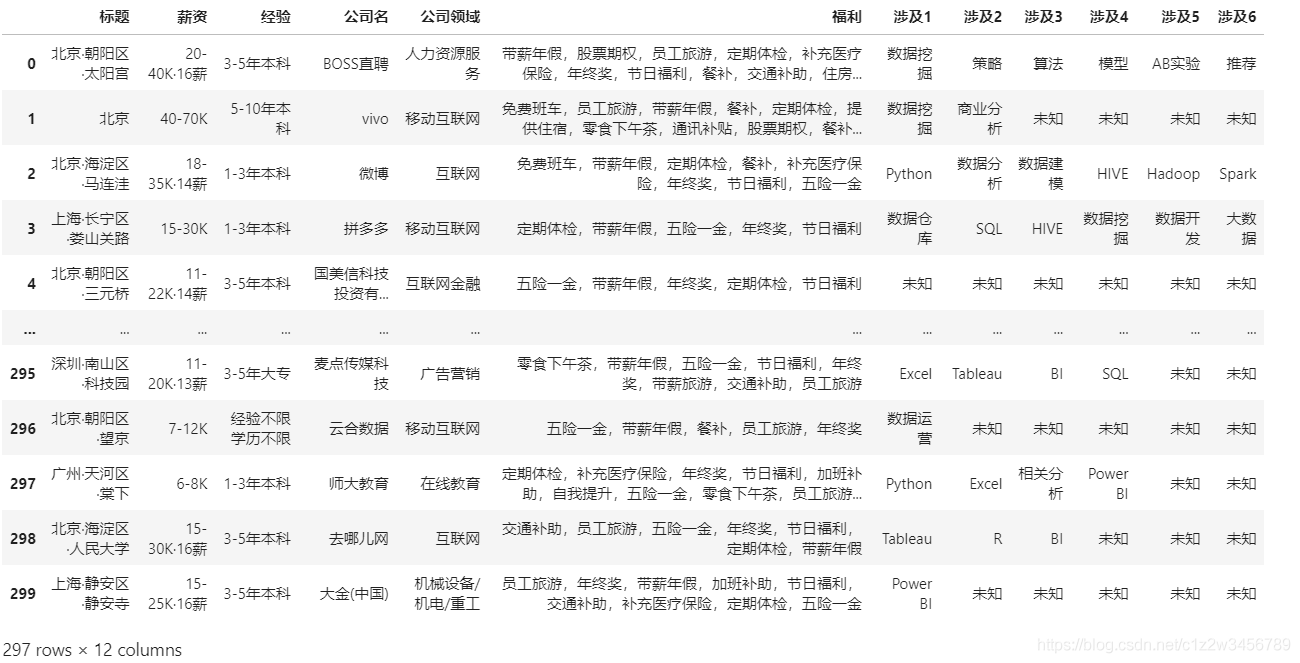
1.导入数据集
df = pd.read_csv(r'F:\Python\\xx直聘数据分析师.csv',encoding='UTF-8')
df.head()

df.info()#查看整体性描述
<class 'pandas.core.frame.DataFrame'> RangeIndex: 300 entries, 0 to 299 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 标题 300 non-null object 1 薪资 300 non-null object 2 经验 300 non-null object 3 公司名 300 non-null object 4 公司领域 300 non-null object 5 福利 273 non-null object 6 tags1 258 non-null object 7 tags2 219 non-null object 8 tags3 163 non-null object 9 tags4 127 non-null object 10 tags5 103 non-null object 11 tags6 80 non-null object dtypes: object(12) memory usage: 28.2+ KB
df.describe()

#查看重复值
df.duplicated().sum()
3
df.drop_duplicates(inplace = True)#删除重复值
df.duplicated().sum()
0
df.isnull().sum()#查看空值
标题 0 薪资 0 经验 0 公司名 0 公司领域 0 福利 26 tags1 41 tags2 80 tags3 135 tags4 170 tags5 194 tags6 217 dtype: int64
df['福利'].fillna('无',inplace=True)#用“无”填充福利列空值
df.isnull().sum()
标题 0 薪资 0 经验 0 公司名 0 公司领域 0 福利 0 tags1 41 tags2 80 tags3 135 tags4 170 tags5 194 tags6 217 dtype: int64
df.rename(columns={'tags1':'涉及1','tags2':'涉及2','tags3':'涉及3','tags4':'涉及4','tags5':'涉及5','tags6':'涉及6'},inplace=True)#选择性重命名列名
df

df.fillna('未知',inplace=True)#用“未知”填充空值
df
df['地区'] = df['标题'].apply(lambda x:x.split('·')[0])#获取地区
df['地区'].unique()
array(['北京', '上海', '广州', '深圳', '福州', '南京', '杭州', '苏州', '郑州', '常州', '长沙',
'佛山', '扬州', '西安', '武汉', '东莞', '云浮', '宁波', '桂林', '贵阳', '潍坊', '厦门',
'温州', '廊坊', '成都', '淄博', '太原', '南昌', '合肥', '克孜勒苏柯尔克孜自治州', '乌鲁木齐',
'无锡', '南阳', '中山', '天津', '保定', '珠海', '汕尾', '湖州', '绵阳', '日照', '石家庄',
'昆明', '青岛', '嘉兴', '绍兴'], dtype=object)
df['经验'].unique()
array(['3-5年本科', '5-10年本科', '1-3年本科', '1-3年大专', '经验不限本科',
' ',
'3-5年硕士', '在校/应届本科', '5天/周2个月本科', '经验不限大专', '经验不限学历不限', '1-3年硕士',
'5-10年硕士', '经验不限硕士', '5天/周6个月大专', '3天/周12个月本科', '3-5年大专',
'3天/周3个月硕士', '4天/周6个月硕士', '3-5年学历不限', '5-10年大专', '5天/周3个月本科',
'5天/周6个月本科'], dtype=object)
df['经验'].replace('在校/应届本科','经验不限本科', inplace=True)#重命名经验
df['经验'].replace('5天/周2个月本科','经验不限本科', inplace=True)
df['经验'].replace('经验不限学历不限','经验不限大专', inplace=True)
df['经验'].replace('5天/周6个月大专','经验不限大专', inplace=True)
df['经验'].replace('3天/周12个月本科','经验不限本科', inplace=True)
df['经验'].replace('3天/周3个月硕士','经验不限硕士', inplace=True)
df['经验'].replace('4天/周6个月硕士','经验不限硕士', inplace=True)
df['经验'].replace('3-5年学历不限','经验不限大专', inplace=True)
df['经验'].replace('5-10年大专','经验不限大专', inplace=True)
df['经验'].replace('3-5年大专','经验不限大专', inplace=True)
df['经验'].replace('5天/周6个月本科','经验不限本科', inplace=True)
df['经验'].replace('5天/周6个月本科','经验不限本科', inplace=True)
df['经验'].replace('
df['经验'].unique()
array(['3-5年本科', '5-10年本科', '1-3年本科', '1-3年大专', '经验不限本科', '3-5年硕士',
'经验不限大专', '1-3年硕士', '5-10年硕士', '经验不限硕士', '5天/周3个月本科'], dtype=object)
df['薪资'].unique()
array(['20-40K·16薪', '40-70K', '18-35K·14薪', '15-30K', '11-22K·14薪',
'20-35K·16薪', '15-30K·16薪', '40-60K·14薪', '25-50K·16薪',
'12-22K·14薪', '15-30K·13薪', '15-25K·14薪', '20-40K·15薪',
'23-45K·15薪', '15-28K', '11-22K', '15-22K·14薪', '18-35K', '15-23K',
'15-25K·13薪', '18-35K·15薪', '20-30K·16薪', '11-20K', '12-20K',
'11-20K·13薪', '15-18K', '15-25K', '20-25K·16薪', '15-30K·14薪',
'20-40K·14薪', '20-30K·15薪', '15-25K·15薪', '15-20K·13薪', '13-26K',
'11-14K·13薪', '12-24K·13薪', '17-29K', '18-30K·15薪', '20-35K·14薪',
'12-24K·14薪', '16-30K', '130-200元/天', '9-14K', '4-5K', '11-18K',
'15-30K·15薪', '8-12K', '10-15K', '12-15K', '14-20K·14薪',
'5-8K·15薪', '5-6K', '5-8K', '8-10K', '8-13K', '4-6K', '13-25K',
'12-24K', '6-8K', '8-10K·13薪', '5-9K', '20-40K', '7-12K', '5-10K',
'5-7K', '10-15K·14薪', '10-11K', '30-60K·14薪', '25-45K·14薪',
'30-45K·16薪', '25-50K·13薪', '18-35K·13薪', '22-30K·16薪',
'25-45K·16薪', '20-30K', '14-28K', '12-20K·13薪', '25-30K', '12-16K',
'25-40K·14薪', '60-90K', '11-22K·13薪', '18-25K·15薪', '20-30K·14薪',
'12-18K', '11-14K', '4-7K', '11-18K·14薪', '25-35K', '18-23K',
'15-20K·14薪', '11-18K·15薪', '10-15K·13薪', '15-20K', '6-11K',
'8-11K·13薪', '6-10K', '7-12K·13薪', '7-9K·13薪', '13-18K',
'90-110元/天', '7-10K·13薪', '250-300元/天', '9-14K·13薪', '200-250元/天',
'8-13K·13薪', '6-11K·13薪', '100-200元/天', '5-7K·13薪', '18-25K·13薪',
'30-50K·14薪', '30-50K·16薪', '15-25K·16薪', '20-35K', '14-24K',
'25-50K·14薪', '25-40K·15薪', '11-19K·13薪', '16-26K', '30-40K',
'17-18K', '220-260元/天', '12-18K·15薪', '7-8K', '18-30K',
'23-45K·18薪', '12-18K·13薪', '3-4K', '7-10K', '150-200元/天',
'11-15K', '12-20K·15薪', '8-11K', '4-7K·13薪', '6-9K·13薪',
'12-20K·14薪', '3-5K', '1-2K', '7-11K·13薪', '120-200元/天', '6-7K'],
dtype=object)
df['m_max'] = df['薪资'].str.extract('(\d+)')#提取出最低薪资
df['m_min'] = df['薪资'].str.extract('(\d+)K')#提取出最高薪资
df['m_max'] = df['m_max'].apply('float64')#转换数据类型
df['m_min'] = df['m_min'].apply('float64')
df['平均薪资'] = (df['m_max']+df['m_min'])/2
df.head()

#每个地区的招聘数量
dq = df.groupby('地区').count()['标题']
dq_index = dq.index.tolist()
dq_value = dq.values.tolist()
bar1 = (Bar(init_opts=opts.InitOpts(width='800px', height='400px',theme=ThemeType.MACARONS))
.add_xaxis(dq_index)
.add_yaxis('', dq_value,category_gap="50%")
.set_global_opts(title_opts=opts.TitleOpts(title="每个地区的招聘数量"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-50)),
visualmap_opts=opts.VisualMapOpts(max_=80),#彩色块
datazoom_opts=[opts.DataZoomOpts()]#拉动条形轴
)
)
bar1.render_notebook()

salary_average = df.groupby('地区').mean()['平均薪资']
salary_average.isnull().sum()
0
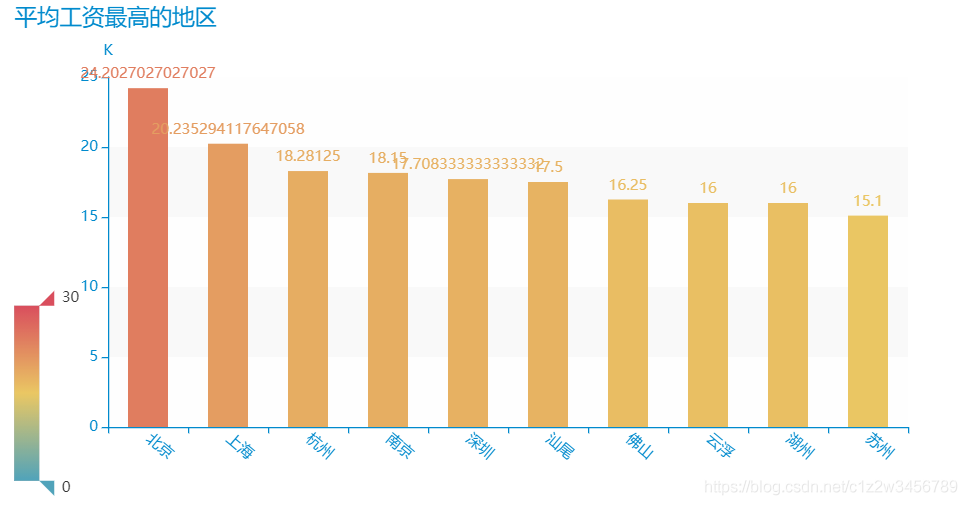
#找出平均薪资最高的十个地区
salary_average = salary_average.sort_values(ascending=False)[:10]
salary_average
地区 北京 24.202703 上海 20.235294 杭州 18.281250 南京 18.150000 深圳 17.708333 汕尾 17.500000 佛山 16.250000 云浮 16.000000 湖州 16.000000 苏州 15.100000 Name: 平均薪资, dtype: float64
#平均工资最高的地区
bar2 = (Bar(init_opts=opts.InitOpts(width='800px', height='400px',theme=ThemeType.MACARONS))#更改主题色
.add_xaxis(salary_average.index.tolist())
.add_yaxis('',salary_average.values.tolist(),category_gap="50%")
.set_global_opts(title_opts=opts.TitleOpts(title="平均工资最高的地区"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-40)),
visualmap_opts=opts.VisualMapOpts(max_=30),
yaxis_opts=opts.AxisOpts(name='K')
)
)
bar2.render_notebook()
jingyan = df.groupby('经验').count()['标题']
jingyan
经验 1-3年大专 17 1-3年本科 89 1-3年硕士 1 3-5年本科 106 3-5年硕士 9 5-10年本科 20 5-10年硕士 1 5天/周3个月本科 1 经验不限大专 21 经验不限本科 28 经验不限硕士 4 Name: 标题, dtype: int64
#经验学历需求图
pair_1 = [(i, int(j)) for i, j in zip(jingyan.index,jingyan.values)]
pie = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS,width='1000px',height='600px'))
.add('', pair_1, radius=['40%', '70%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="经验学历需求图",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='black',
font_size=20,
font_weight='bold'
),
)
)
)
pie.render_notebook()

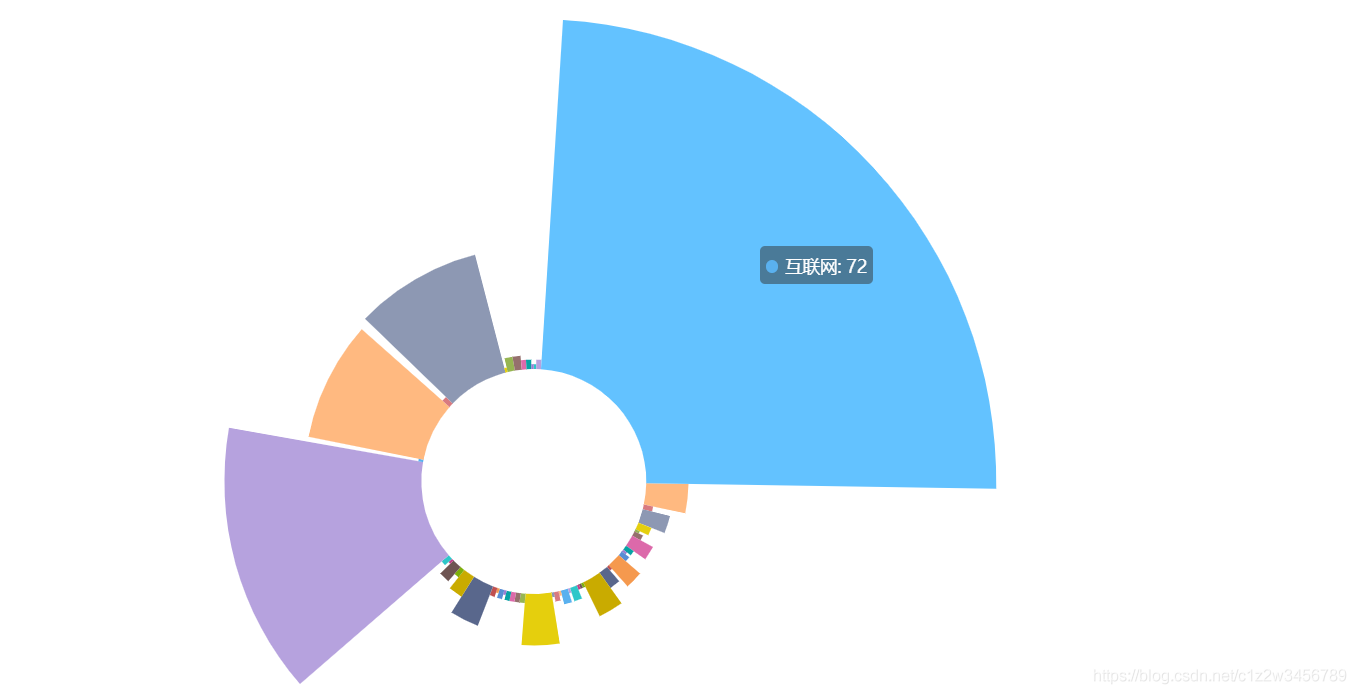
gongsi = df.groupby('公司领域').count()['标题']
#招聘公司所在领域
pie1 = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS,width='1500px',height='900px'))
.add(
"",
[list(z) for z in zip(gongsi.index.tolist(), gongsi.values.tolist())],
radius=["20%", "80%"],
center=["25%", "70%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),
).set_global_opts(title_opts=opts.TitleOpts(title="招聘公司所在领域"))
)
pie1.render_notebook()