项目简介
既然想要从事数据分析及其相关岗位,那么首先就得对这个岗位及相关岗位有所了解。而最直接的方式就是从企业那里获取最为直接的信息,但是并不容易获取。因此,本次项目就是通过手动方式,利用爬虫来爬取拉勾网上数据分析,数据挖掘,机器学习,深度学习等与数据分析相关的岗位的信息,然后进行一些探索和分析,以此来了解数据分析岗位的情况,并加深对数据分析的了解。
项目开发环境准备
操作系统
- windows
开发工具
- PyCharm
- Anconda 5.20
- Jubyter Notebook
- Python 3.6.5
第三方模块包
- Numpy 1.14.3
- Pandas 0.23.0
- Matlotlib 2.2.2
- Xpath
- requests 2.18.4
数据来源
本项目使用的数据全部来源于拉勾网,通过爬虫框架爬取。由于拉钩网上的数据多为动态页面,分页操作时,URL上并不显示加载的页面数。因此可我们通过ajax动态页面获取数据。
本项目选择拉勾网作为数据源,主要是由于该网站信息量大,并且招聘信息齐全,更新比较快,能实时更新招聘信息。此外,拉勾网上的信息非常完整、整洁,存在少量的漏洞信息,布局编排规范化,极大的减少了前期的数据清洗和数据整理的工作。
目的
本项目希望通过实际的数据来解答针对数据分析岗位的一些疑惑。主要从高一下几个方面分析:
- 数据分析师岗位需求的地域性及行业分布
- 数据分析师岗位对学历和工作经验的要求
- 招聘数据分析师的企业的融资状况和规模
- 不同城市、经验、行业、学历、企业融资情况的薪酬分布情况
- 从用人单位角度看,数据分析师应当具备那些技能
数据采集与清洗
在拉勾网分别搜索:'数据分析师','机器学习','数据挖掘','深度学习',通过爬虫一共得到1650条数据

将数据在jupyter notebook中运行
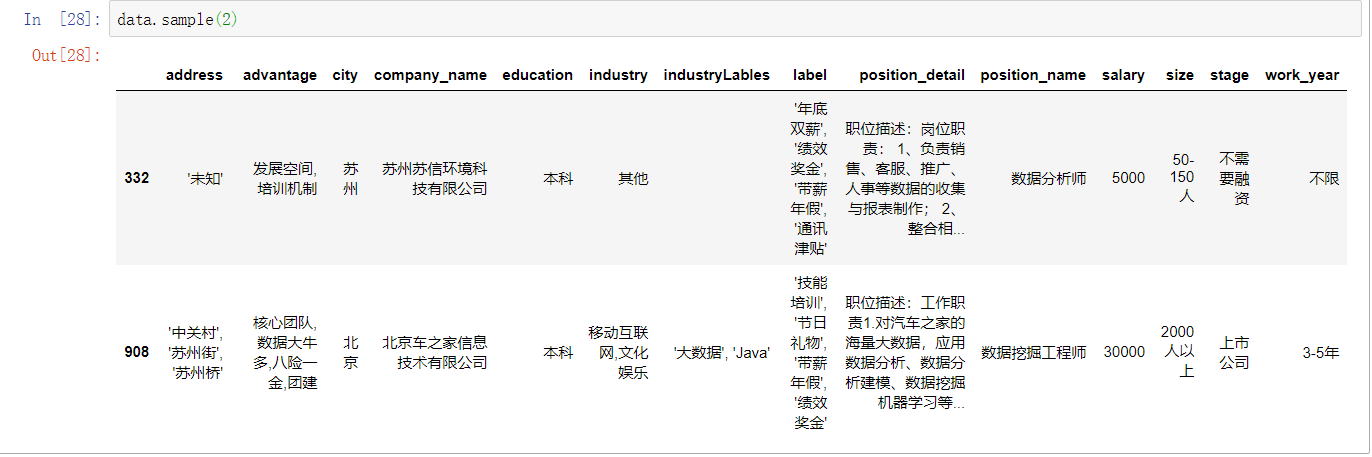
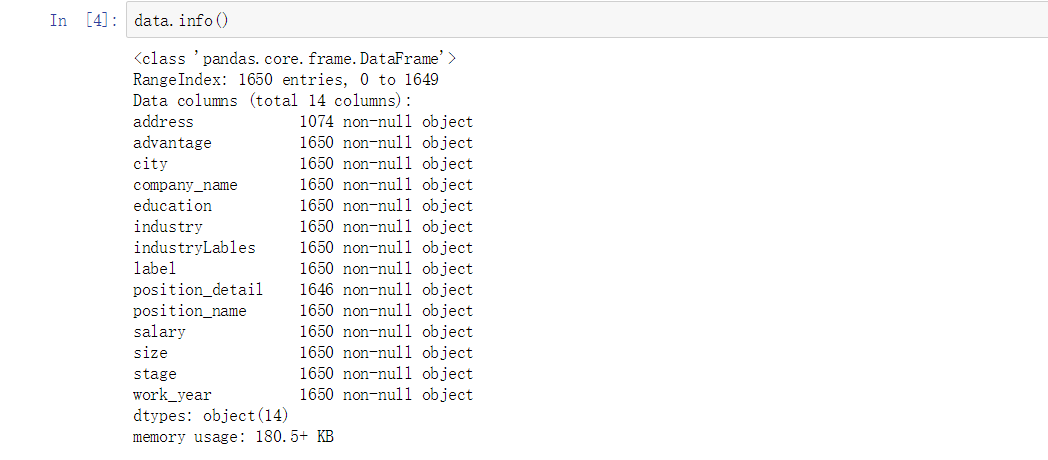
从上面可以看到,一共有14个字段,公司地址有一些缺失值,其他基本上没有缺失值
数据清洗与预处理
- 从上面的字段信息可以看出,address字段出现空值,因此我们将其改为 '未知'
- 上面某些字段出现"[...]",我们需将其使用replace()将其替换掉成: ' '
- 因变量为薪资水平是一个连续变量,我们需要将其转换为一个具体的值,取其范围的平均值即可
- 岗位名称不一致,某些岗位出现:'数据分析','数据分析师','数据分析工程师'等,因此我们将其一致化,都改为‘数据分析师’
最后清洗完成后的结果展示为:


import numpy as np import pandas as pd import string import warnings warnings.filterwarnings('ignore') class data_clean(object): def __init__(self): pass def get_data(self): data1 = pd.read_csv('./data_analysis.csv', encoding='gbk') data2 = pd.read_csv('./machine_learning.csv', encoding='gbk') data3 = pd.read_csv('./data_mining.csv', encoding='gbk') data4 = pd.read_csv('./deep_learning.csv', encoding='gbk') data = pd.concat((pd.concat((pd.concat((data1, data2)), data3)), data4)).reset_index(drop=True) return data def clean_operation(self): data = self.get_data() data['address'] = data['address'].fillna("['未知']") for i, j in enumerate(data['address']): j = j.replace('[', '').replace(']', '') data['address'][i] = j for i, j in enumerate(data['salary']): j = j.replace('k', '').replace('K', '').replace('以上', '-0') j1 = int(j.split('-')[0]) j2 = int(j.split('-')[1]) j3 = 1/2 * (j1+j2) data['salary'][i] = j3*1000 for i, j in enumerate(data['industryLables']): j = j.replace('[', '').replace(']', '') data['industryLables'][i] = j for i, j in enumerate(data['label']): j = j.replace('[', '').replace(']', '') data['label'][i] = j data['position_detail'] = data['position_detail'].fillna('未知') for i, j in enumerate(data['position_detail']): j = j.replace('\r', '') data['position_detail'][i] = j return data opt = data_clean() data = opt.clean_operation() data.head()
数据分析与可视化
工资水平整体分布
plt.hist(data['salary'],bins=10) plt.show()
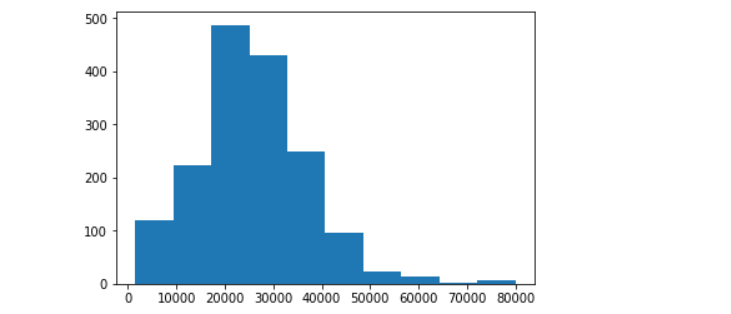

从上图以及导入scipy函数分析结果可知,偏度小于1,峰度小于3,所以目标变量右偏且瘦尾。
数据分析等岗位城市分布:
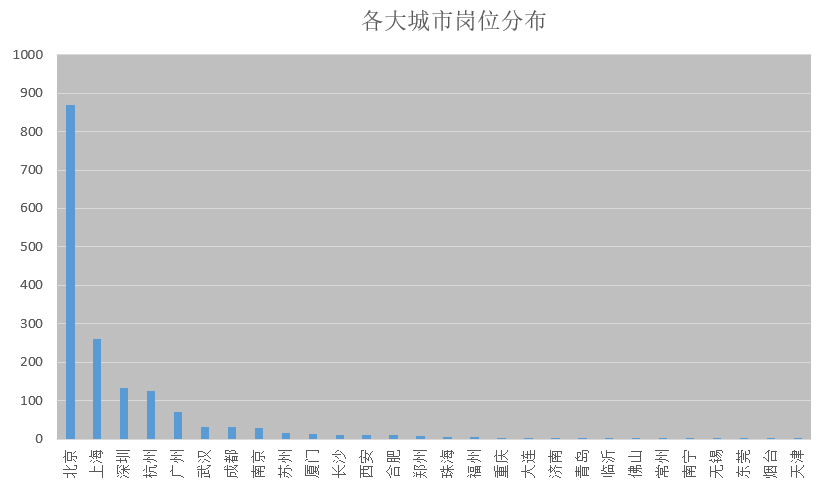
从这1650条招聘信息里,有869条数据来自北京,需求量居全国第一,并且需求量远超第二名的上海、深圳、杭州、广州等地,排在前8位的城市依次是:北京、上海、深圳、杭州、广州、武汉、成都、南京。
从上图可以看出:数据分析等行业大量集中在北上广深一线城市,以及杭州这个互联网和电子商务企业的聚集地。其中北京市的需求量超过上海的两倍,不得不感叹帝都的数据分析人才需求量之大。上海作为国内经济中心,紧随其后。广深地区有腾讯坐镇,杭州则有阿里巴巴,数据人才的需求也都很大。
总而言之,想从事数据分析的小伙伴请重点关注北上广深和杭州的招聘信息。当然,从另一个方面说,这些城市的竞争压力想必也是很大的。
数据类岗位对学历的要求
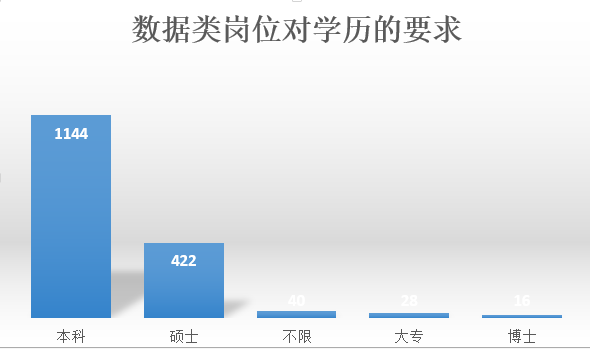
很明显,对于数据分析岗位而言,本科学历要求是目前主流,其次是大专和硕士学历,部分不限学历和只要求高中学历的岗位明显看重工作经验。
数据分析岗位对经验的要求

工作3-5年经验的资深分析师需求量最大,其次是1-3年工作经验的熟手。对应届生的需求很少,但要求10年以上的更少。
我们大致可以猜测出:
- 数据分析是个年轻的职业方向,大量的工作经验需求集中在1-3年;
- 对于数据分析师来说,5年是个瓶颈期,如果在5年之内没有转型或者质的提升,大概以后的竞争压力会比较大;
- 应届生找数据分析工作可能比较困难,需要累积实习经验。
数据分析师岗位行业分布
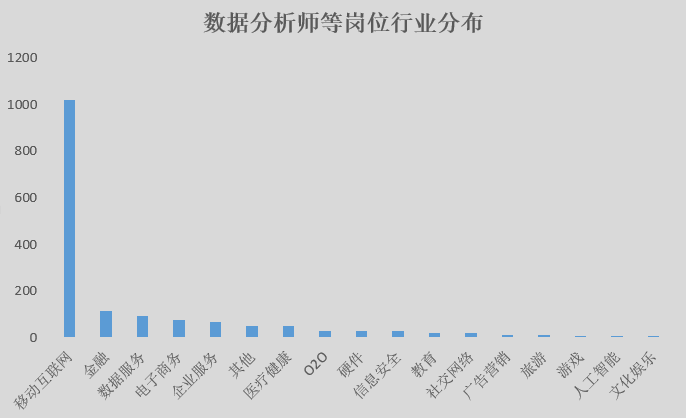
移动互联网,金融,数据服务,电子商务,企业服务等行业为数据分析等岗位提供了大量的 就业机会,数据行业的繁荣也相应的催生了专门提供数据服务的公司。虽然传统行业对数据人才的需求目前并不显著,但相信随着互联网+对传统行业的渗透,这些行业对数据人才的需求也会慢慢增加。
公司融资状况分布
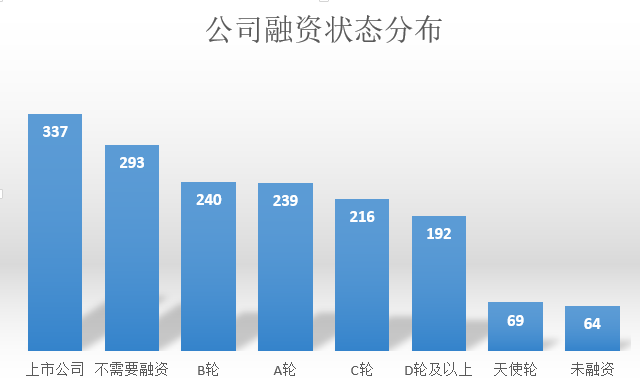
上市公司对数据人才的需求最大;其次是不需要融资和未融资的公司,这类公司大多处于初创型,急需数据人才加快公司发展。天使轮的公司规模大多较小,对数据分析和数据挖掘的需求也相对较小。
公司规模分布
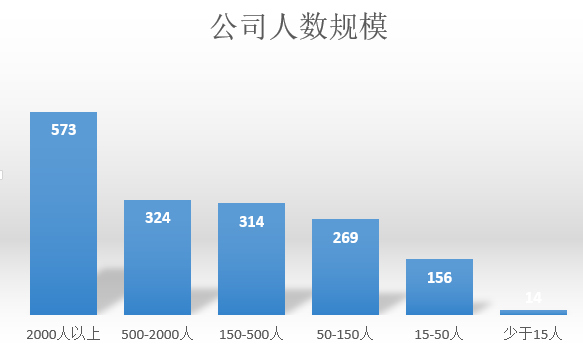
2000人以上的公司对数据分析师的需求最大,反之,少于15人的公司因为规模小,需求也少。但总体来看,除极小规模的公司以外,数据分析岗位受公司规模的影响不大。
城市与薪酬分布

前几名的城市依次为:北京,深圳,上海,杭州,广州等,这些城市开的工资相较于其他城市要高一些,其他城市相对要稍低一点,可能是因为这些城市企业种类较多,开出的工资差异也较大。对于工资而言,留在大城市似乎是不错的选择。
工作经验与薪酬分布

可以看出,工作经验越高,平均薪酬也越高。10年以上经验的平均薪酬最高,高其他薪资一个档次。而应届毕业生平均薪资最低。
行业与薪酬分布

O2O、互联网和金融行业的薪酬都处于领先地位,不愧是当下热度最高的三大行业。随着大众生活水平的提升,人们对健康也越来越关注,因此医疗健康行业的薪酬也非常高。
学历与薪酬分布
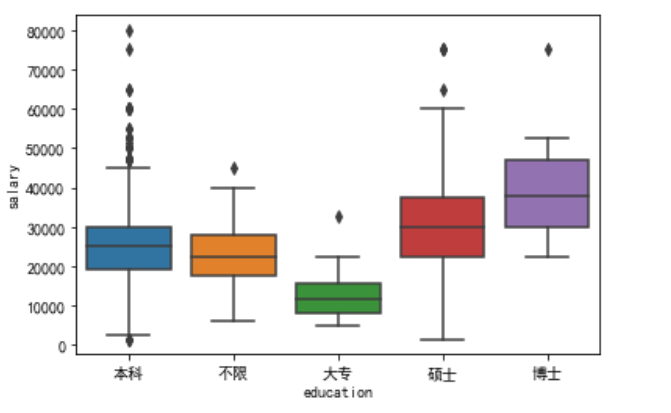
总体来看学历越高薪酬越高。大学似乎是一个坎,拥有大学学历的数据分析师们平均薪酬比较低学历或不限学历的人更高。看来接受高等教育对数据分析师还是很重要的。
企业融资阶段与薪酬分布
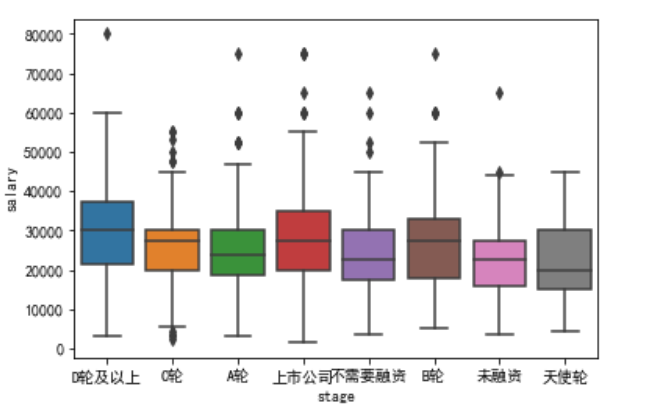
上市公司并不如预想中的财大气粗,开出的平均薪酬的中位数低于D轮融资的公司。主要因为上市公司对数据人才的需求参差不齐,尽管最高的薪酬还是来自上市公司。这样看来,成熟型(B、D轮)公司似乎是不错的选择。
企业规模与工资水平
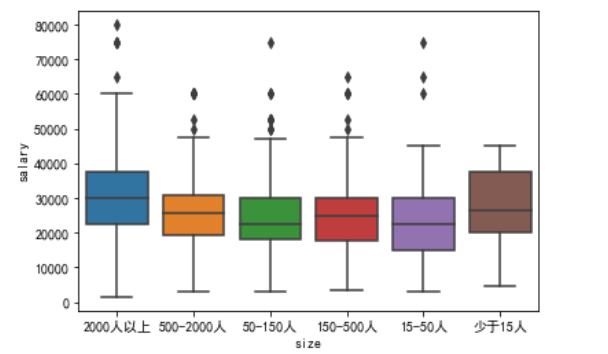
从上图可以看出,企业规模与薪酬水平相差不是非常大,而规模大于2000人与公司规模小于15人的公司薪酬要大于其他规模的公司。这主要是由于大型公司的福利制度相对更加完善,而初创型公司为了吸引人才,所以开出更高的工资。
岗位与工资水平

数据分析师的工资要低于其他岗位。这表明数据分析师还是属于一个较初级的阶段,如果想要得到更好的发展,并且拿到一个更高的工资,所以还是得更加努力得学习和工作,争取往数据挖掘工程师或机器、深度学习工程师方向发展。
职位描述词云

结论
- 大多数数据分析岗位要求本科学历;
- 高学历更可能获得高薪;
- 数据分析是个年轻的职业方向,大量的工作经验需求集中在1-3年;
- 对于数据分析师来说,5年似乎是个瓶颈期,如果在5年之内没有转型或者质的提升,大概以后的竞争压力会比较大;
- 工作经验越多,越可能获得高薪;
- 数据分析这一岗位,有大量的工作机会集中在北上广深以及杭州,而且这些城市的薪酬也处于较高水平;
- 互联网、移动互联网、金融、IT软件和电子商务行业对数据分析师的需求较大,传统行业则相反;
- O2O、互联网和金融行业的薪酬相对较高;
- 上市公司对数据人才的需求最大,但开出的平均薪酬不算高,反而是B、D轮融资的公司提供的平均薪酬处于领先地位;
- 数据分析师必须掌握的技能有:数据库知识(如SQL),数据分析语言(如Python),基本的统计分析软件(如Excel)。
- 想要得到更好得职业发展,并不能只局限于数据分析,毕竟数据分析只是属于比较初级阶段,我们应该向着更加上层次得方向,如:数据挖掘,机器学习,深度学习方向发展。
参考文献: