毕设研究需要阅读文献,在此记录部分阅读笔记,只是记录了我关注的一些点
一、摘要
本文开发了一种能够检测多种心率不齐的算法(基于穿戴式心电图监测器采集的信号),该算法的性能超过了心脏病医师。我们构建的数据集比前人大500倍。在此数据集上,我们训练了一个34层的卷积神经网络,其以心电图(ECG)序列为输入,输出类别(rhythm
classes)。顶级心脏病专家对测试集的标记为 ground truth,在测试集上,将本文算法与6个心脏病医师进行了性能比较。本文的算法在召回率(灵敏度)和准确率(预测正确的比例)上都超过了心脏病医师。
二、数据
从 29163 位病人收集、标记的 64121 个心电图信号构成了本文的数据集。心电图信号的采样频率为 200 Hz。训练集的每一个记录的长度都是 30 秒,并且可能包含多个 rhythm 类。每一个记录都被“三个心脏病专家组成的委员会”进行了标记:专家标记了信号中异常的段,并将其标记为 14 个 rhythm 类别中的一个。
30 秒记录的标签制作使用了一个基于 web 的心电图标记工具(专门用来标记心电图)。制作标签的都是国际认证的专家。标签采用了 offset 的方式。从而将输入心电图信号完全分割。为了提高不同标记人员标签的一致性,对每一个
rhythm 变化使用特定的规则。
我们将数据集分为一个训练集和验证集。训练集包含数据集 90% 的数据。数据集的划分过程中,训练、验证、测试集中的病人不重叠。
收集了 328 个病人的 336 个心电图记录作为测试集。对于测试集,每一个记录的 ground truth 标记由三位心脏病专家组成的委员会商议产生:每个顶尖专家负责测试集不同的分割(意思应该是负责不同的种类的标签)。顶尖专家对每一个记录进行组讨论、产生一个一致的标签(意思是,综合各位专家的意见,为每一个记录产生一个合理的标签)。对于测试集中的每一个记录,我们也额外收集 6 个专家的独立标记(这6个专家不在委员会里)。委员会产生的
ground truth 用于对于模型和心脏病医师的性能。
三、方法
在本文的序列到序列任务中,使用卷积神经网络。模型总的架构如图 2 所示。网络以原始的心电图信号(时序)为输入,输出预测的标签序列。心电图的长度为 30
秒,采样率为 200 Hz,模型每秒输出一个新的预测值。本文的模型包含 33 个卷积层、1 个全连接层、1 个 softmax 层。
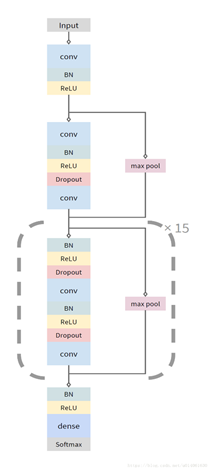
为了使深度网络可训练,本文的模型使用了类似 ResNet 的架构:使用了 shortcut、BN。本文的网络包含16个残差块,每个残差块包含 2 个卷积层。所有的卷积层的 filter size 为 16,filter 数为 64k,这里 k 从 1 开始,每 4 个残差块增加1。每个残差块后都下采样一次(factor
为 2),因此原始的输入最后被下采样为原始大小的2^8分之一。当一个残差块进行下采样时,shortcut 也使用 max-pool 进行下采样。
在每一个卷积层之前,使用pre-activation(BN + ReLU)。由于使用了预激活,网络的第一层和最后一层变得不一样。也在卷积层的激活函数之后使用了 Dropout。最后的全连接层、softmax 激活对每一个时间步产生一个 14 类的概率分布。
从头开始训练了网络,卷积层的参数初始化方式如 ResNet v1。使用默认参数的 Adam 优化器,当验证集上的 loss 停止下降就将学习速率除以 10。将训练过程中在验证集上最好的模型保存下来用于测试。
四、结果
我们使用了两个指标来衡量模式的准确度(将专家委员会的标记作为 ground truth)。
序列级别的准确度(F1):
Sequence Level Accuracy (F1): 我们用预测值与 ground
truth 序列标签之间的平均重合度来衡量模型性能。对于每个记录,一个模型被要求
要在约 1 秒内给出预测(原文为: For every record, a model is
required to make a prediction approximately once per second (every 256 samples))。这些预测被用来和 ground truth 标记进行比较。
集合级别的准确度(F1):
Set Level Accuracy (F1): 不再将每一个记录的标签看做一个序列,我们将每个 30 秒记录出现的异常作为该记录的 ground truth(去掉重复)。与序列级别的准确度不同,集合级别的准确度不考虑记录内
心率异常出现的时间。我们用
预测类别 和 ground truth 的 F1 Score 衡量模型的性能。
在序列、集合两个级别的评价指标中,我们单独为每一个类别计算了 F1 score。我们然后使用类别加权平均来计算 总的 F1 score(和 准确率、召回率)。

表 1 展示了心脏病专家、模型在不同 rhythm 类别上的性能。在绝大数 rhythm 上,本文模型的性能超过了心脏病专家。尤其注意的是:在 AV Block 心律不齐集(包括 Mobitz I (Wenckebach)、Mobitz II (AVB Type2)、complete heart block (CHB))上超过了人类专家。Mobitz
II 和 CHB 是恶性的,而 Wenckebach 被认为是良性的,因此能够将恶性和良性分开是非常有用的。
表 1 也比较了总精度、总召回率、总 F1。心脏病专家的总分被定义为了各位独立的心脏病专家的得分的均值。模型的平均精度、平均召回率都超过了心脏病专家。
