1. 论文思想
训练深度学习网络是相当复杂的,每个层的输入分布会在训练中随着前一层的参数变化而改变。仔细地网络初始化以及较低的学习率下会降低网络的训练速度,特别是具有饱和非线性的网络。在该论文中将该中现象称之为“internal covariate shift”,在论文中为了解决该问题提出了BN的概念,它取得的成果也会很显著:
(1)网络中添加了BN层之后可以使得网络使用更高的学习率,减少对网络初始化的关注
(2)网络中加入了BN层相当于增加了正则化,在一些场合下网络中可以取消掉Dropout层
(3)在加入BN层的网络结构中,达到相同的精度,加入BN层的网络能够减少14倍的训练步骤
(4)将论文中提出的理念运用到之前的网络后在ImageNet获得了4.9% Top-5的验证错误率,4.8的测试错误率,已经超过了人类的水平。
在前人的研究中对深度学习网络中的输入进行白化处理,可以使得网络的性能得到提升,其实白化就是将数据进行归一化处理,将数据转换成为0均值和方差为1的数据分布。另外,在深度学习训练过程中SGD使用了batch_size进行训练,避免使用单个样本进行训练,其中的道理也是batch_size进行训练下降的方向更加准确,震荡更小。
而在网络中会出现“internal covariate shift”的问题就是因为网络在学习过程中网络中的输入分布是在不断变化的,那么在输入的时候给它把分布固定,那么网络的训练那么不是会有好转,正是基于这样的思想,就祭出BN操作了。
2. 使用Min-Batch统计标准化
由于对每个输入层做白化操作是花销巨大且其实不可微的,也就没办法进行梯度传递。那么在该文章里面是对
维输入
中的1维单独进行标准化:
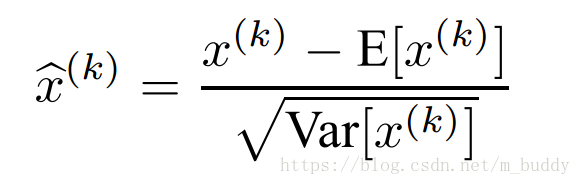
但是值得注意的是单一地对层输入进行标准化会使得层的表达。例如,Sigmoid的输入标准化会将输入压缩到Sigmoid函数的非线性函数中的线性部分中去。
但是这样的操作会使得网络层的表达能力下降。因而在该篇论文中对标准化函数进行了修正。为每个
增加一对参数
与
,用作在原分布上做缩放和偏移。
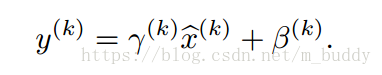
其中,对于参数取值为:
与
。因而对于输入一个Batch-Size
对应的
,其对应的线性变化
描述为:
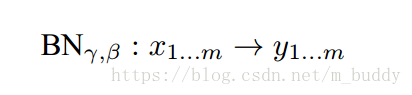
因而当前Batch-Size的标准化变换可以描述为如下形式:

上面的内容是BN操作的前向操作,但是网络要进行训练就需要梯度信息进行反向传递那么这里加入的BN层能够进行反向运算么?这里其实就是判断该变换是不是可微分的。论文中给出了其证明
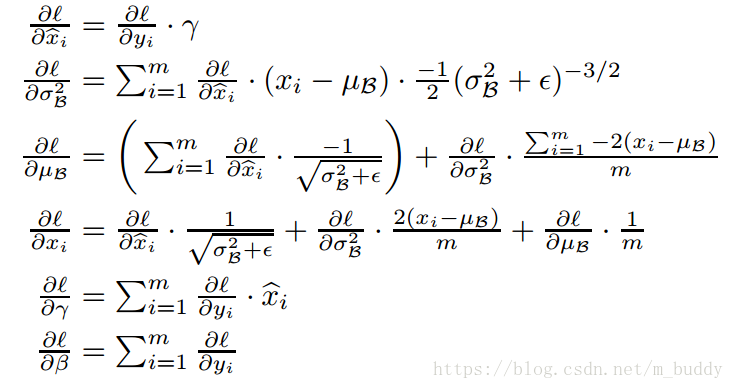
因为引入了BN操作,这就消除了“internal covariate shift”的问题,因而可以加快网络的训练过程。
2.1 BN网络的训练与推断
在上面的内容中给出了如何给一个Batch-size使用BN操作进行网络分布变换。那么在网络训练之后怎么使用每个Batch-size训练的结果来推断网络最后应该取值的参数呢?接下来的内容便是网络的推断(最后参数确立)。首先网络训完成之后就需要使用总体统计来标准化网络,即是下面的公式
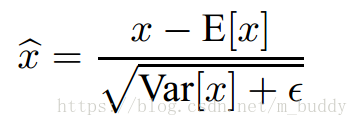
其中无偏方差估计
,
是Batch-size的大小,而
是这些采样的方差。下面这幅图便是推断网络的大致流程。

这里的输入是参数为
的训练网络与子集数据
,输出是经过推断在之后的
。这里算法的1~5便是当前Batch-size的标准化,之后步骤6开始训练去优化训练与BN中的参数。接下来步骤8~12是推断总体统计,得到最后该BN层的参数。
2.2 BN可以使用更高的学习率
在传统的深度网络中太高的学习率会导致梯度爆炸或是消失,以及陷入局部最优值的问题。在网络中加入BN之后可以防止网络中参数微小的变化被放大。在网络中使用更大的学习率,可以被理解成为是层参数范围的增大,这在反相传播的过程中会导致模型梯度爆炸。那么增大的参数可以使用
a$来表示,那么训练的时候层的标准化可以表示为
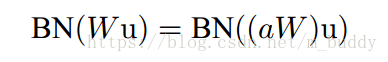
可以看到缩放参数的范围并不会对BN的结果带来影响,因而加入BN之后可以使得网络可以使用更高的学习率。
3. 实验
下面这幅图是在MNIST数据集上进行测试,结果为
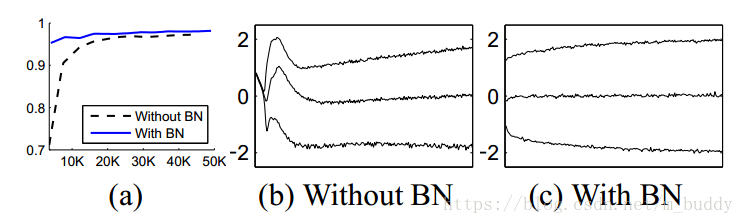
可以明显看到网络在加入BN之后训练的曲线变得更加平滑,收敛也更快。
3.1 加速BN网络
只是使用BN并不能使得该文章中的BN作用最大化,文章中给出了如下的建议:
(1)提高学习率:在批标准化模型中,我们已经能够从高学习率中实现训练加速,没有不良的副作用。
(2)删除Dropout层:我们发现从BN-Inception中删除Dropout层可以使网络实现更高的验证准确率。我们推测,批标准化提供了类似丢弃的正则化收益,因为对于训练样本观察到的激活受到了同一小批量数据中样本随机选择的影响。
(3)更彻底地搅乱训练样本。我们启用了分布内部搅乱训练数据,这样可以防止同一个例子一起出现在小批量数据中。这导致验证准确率提高了约1%,这与批标准化作为正则化项的观点是一致的:它每次被看到时都会影响一个样本,在我们的方法中内在的随机化应该是最有益的。
(4)减少L2全中正则化。虽然在Inception中模型参数的L2损失会控制过拟合,但在修改的BN-Inception中,损失的权重减少了5倍。我们发现这提高了在提供的验证数据上的准确性。
(5)加速学习率衰减。在训练Inception时,学习率呈指数衰减。因为我们的网络训练速度比Inception更快,所以我们将学习速度降低加快6倍。
(5)删除局部响应归一化(Local Response Normalization, LRN)。虽然Inception和其它网络(Srivastava等人,2014)从中受益,但是我们发现使用批标准化它是不必要的。
(5)减少光照扭曲。因为批标准化网络训练更快,并且观察每个训练样本更少的次数,所以通过更少地扭曲它们,我们让训练器关注更多的“真实”图像。