在之前的博文中,我总结了神经网络的大致结构,以及算法的求解过程,其中我们提高神经网络主要分为监督型和非监督型,在这篇博文我总结下一种比较实用的非监督神经网络——稀疏自编码(Sparse Autoencoder)。
1.简介
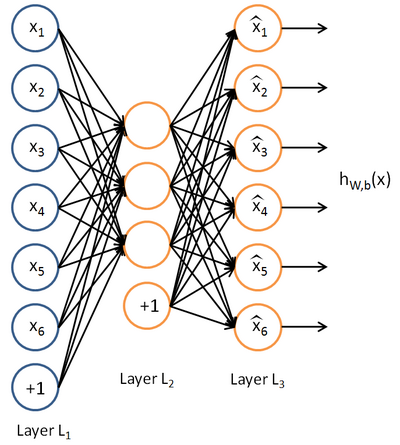
上图是稀疏自编码的一般结构,最大的特点是输入层结点数(不包括bias结点)和输出层结点数相同,而隐藏层结点个数少于输入层和输出层结点的个数。该模型的目的是学习得到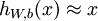
在监督神经网络中,训练数据为(x(i),y(i)),我们希望模型能够准确的预测y,从而使得损失函数(具体实际需求建立不同的损失函数)的值最小,当然,为了避免过拟合,我们引入了惩罚项。在非监督网络中,训练数据是x(i),没有标注的样本值(即y值),但是为了构建损失函数,我们仍然需要y值,在稀疏自动编码中y(i) = x(i)。在我看来,稀疏自动编码就是一般神经网络的特例,只是要求输入值和输出值近似,另外使得隐藏层变的稀疏。
2.何为稀疏(What’s sparsity)
在上面我们提到,一般使得隐含层小于输入结点的个数,但是我们也可以让隐藏层的节点数大于输入结点的个数,只需要对其加入一定的稀疏限制就可以达到同样的效果。如何隐藏层的节点中大部分被抑制,小部分被激活,这就是稀疏。那什么是抑制,什么是激活能?如果的非线性函数是sigmoid函数,当神经元的输出接近1时为激活,接近0时为稀疏;如果采用tanh函数,当神经元的输出接近1时为激活,接近-1时为稀疏。
那添加什么限制可以使的隐含层的输出为稀疏呢?稀疏自动编码希望让隐含层的平均激活度为一个比较小的值。
隐含层的平均激活的数据表示为:
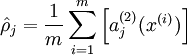
其中, 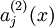
为了使得均激活度为一个比较小的值,引入 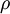
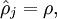
3.损失函数(loss function)
上面只是理论上的解释,那如何转化成数据表示,该模型引入了相对熵(KL divergence),使得隐含层结点的活跃度很小。KL的表达式为:
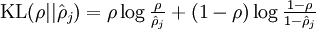
我们假设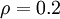
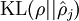
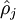
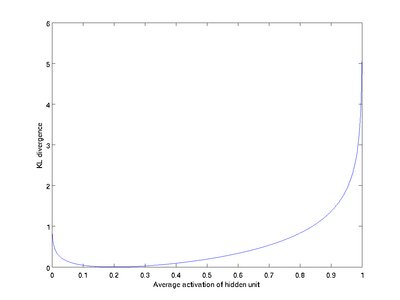
如上图所示,相对熵在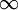
根据这个性质,我们就可把相对熵加入到损失中,惩罚平均激活度离
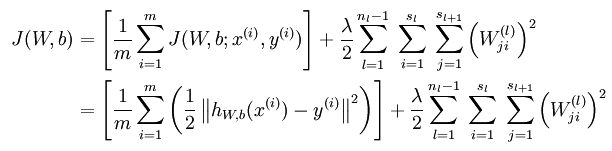
在隐含层加上稀疏约束后,损失函数为:
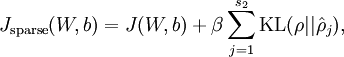
4.损失函数的偏导数(partial derivative of loss function)
损失函数的偏导数计算同样采用了back propagation方法,只是在求解隐含层的时候有所区别,无稀疏约束的BP算法可表示为以下几个步骤:
1、进行正反馈传导计算,根据公式,得到
2、对输出层(第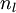
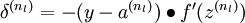
3、对于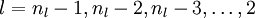
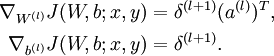
4、计算最终需要的偏导数值:
加入稀疏约束后,隐藏结点的误差表达式由:
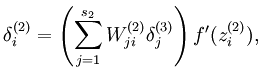
变为:
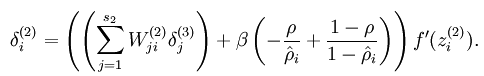
5.参数求解
到目前为止,我们已经知道了模型的损失函数和损失函数相对于所有参数的偏导数,为了求得使损失函数最小的参数,我们很自然的想到的就是梯度下降,具体细节参照之前的博文。
6.总结:
总的来说,稀疏自动编码是在一般神经网络中加上稀疏限制的特殊的三层神经网络。该模型希望从原始数据中得到一种低维表示,可以和PCA做类比加深理解。从输入层到隐含层,类似于PCA找到一个低维空间,把高维数据映射到低维数据;从隐含层到输出层类似于PCA从投影后的低维数据又恢复到原始的高维数据。在实际应用中,稀疏自动编码会作为数据的预处理过程,栈式自编码算法(Stacked Autoencoders)中就使用方法进行数据的预处理,降低数据的维度,提取出潜在的数据信息。