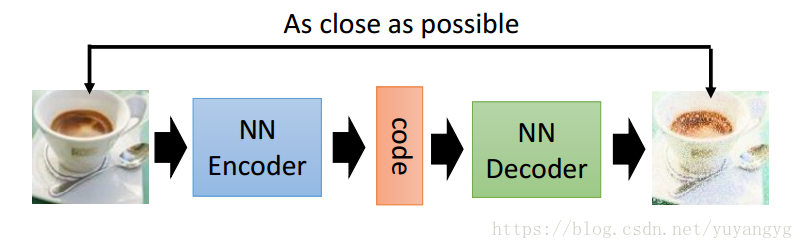
盗图一张,自动编码器讲述的是对于一副输入的图像,或者是其他的信号,经过一系列操作,比如卷积,或者linear变换,变换得到一个向量,这个向量就叫做对这个图像的编码,这个过程就叫做encoder,对于一个特定的编码,经过一系列反卷积或者是线性变换,得到一副图像,这个过程叫做decoder,即解码。
所以现在自动编码器主要应用有两个方面,第一是数据去噪,第二是进行可视化降维。然而自动编码器还有着一个功能就是生成数据。
然而现在还没有用过这方面的应用,在这里需要着重说明一点的是autoencoder并不是聚类,因为虽然对于每一副图像都没有对应的label,但是autoencoder的任务并不是对图像进行分类。
__author__ = 'SherlockLiao'
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import os
if not os.path.exists('./dc_img'):
os.mkdir('./dc_img')
def to_img(x):
x = 0.5 * (x + 1)
x = x.clamp(0, 1)
x = x.view(x.size(0), 1, 28, 28)
return x
num_epochs = 100
batch_size = 128
learning_rate = 1e-3
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = MNIST('./data', transform=img_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = autoencoder().cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate,
weight_decay=1e-5)
for epoch in range(num_epochs):
for data in dataloader:
img, _ = data
img = Variable(img).cuda()
# ===================forward=====================
output = model(img)
loss = criterion(output, img)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ===================log========================
print('epoch [{}/{}], loss:{:.4f}'
.format(epoch+1, num_epochs, loss.data[0]))
if epoch % 10 == 0:
pic = to_img(output.cpu().data)
save_image(pic, './dc_img/image_{}.png'.format(epoch))
torch.save(model.state_dict(), './conv_autoencoder.pth')


编码和解码输出。点击打开链接

自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。作为无监督学习模型,自动编码器还可以用于生成与训练样本不同的新数据,这样自动编码器(变分自动编码器,Variational Autoencoders)就是生成式模型。
本文将会讲述自动编码器的基本原理以及常用的自动编码器模型:堆栈自动编码器(Stacked Autoencoder)。后序的文章会讲解自动编码器其他模型:去噪自动编码器(Denoising Autoencoder),稀疏自动编码器(Sparse Autoencoder)以及变分自动编码器。所有的模型都会使用Tensorflow进行编程实现。
自动编码器原理
自动编码器的基本结构如图1所示,包括编码和解码两个过程:
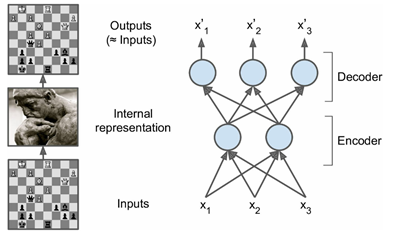 图1 自动编码器的编码与解码
图1 自动编码器的编码与解码
自动编码器是将输入 进行编码,得到新的特征
,并且希望原始的输入
能够从新的特征
重构出来。编码过程如下:
可以看到,和神经网络结构一样,其编码就是线性组合之后加上非线性的激活函数。如果没有非线性的包装,那么自动编码器就和普通的PCA没有本质区别了。利用新的特征 ,可以对输入
重构,即解码过程:
我们希望重构出的 和尽可能一致,可以采用最小化负对数似然的损失函数来训练这个模型:
对于高斯分布的数据,采用均方误差就好,而对于伯努利分布可以采用交叉熵,这个是可以根据似然函数推导出来的。一般情况下,我们会对自动编码器加上一些限制,常用的是使 ,这称为绑定权重(tied weights),本文所有的自动编码器都加上这个限制。有时候,我们还会给自动编码器加上更多的约束条件,去噪自动编码器以及稀疏自动编码器就属于这种情况,因为大部分时候单纯地重构原始输入并没有什么意义,我们希望自动编码器在近似重构原始输入的情况下能够捕捉到原始输入更有价值的信息。