在学概率统计之前,我们学习的都是确定的函数。概率统计讨论了一次取值时获得的值是不确定的,而随机过程讨论了不确定会发生哪个时间函数。
每个小x(t)函数(样本函数)就是实际发生的一个表达式确定的函数,对每个小x(t)的处理,都是与之前确定函数的处理方法相同的,但是由于我们没法确定某次究竟发生哪个确定表达式的小x(t),所以我们只能研究发生哪种情况的概率大些,或者当这件事多次发生时,呈现出来的统计特性是什么。虽然每个小x(t)的特性是不定的,但小x(t)的统计特性却是确定的,所以我们研究的还是变中的不变量。
学习随机过程时困扰我的一个基本式子是自相关函数。我开始一直不明白为什么要用E{X(t1)X(t2)}来表现函数变化的剧烈程度。我一开始不明白具体操作代入时X(t1)和X(t2)应该代入什么,是在不同的小x(t)上取两个时刻的值相乘?还是在同一个小x(t)上取两个时刻的值相乘。后来我又仔细看了一下书上的例子,那个例子用了两张图,一张是每个小x(t)变化都很缓,另一张是每个小x(t)变化都很起伏剧烈。但是两个随机过程的均值和方差是相同的。书上说均值和方差只刻画随机过程X(t)在各个独立时刻的概率统计特性,反映不了随机过程的内在相关性,所以引入了自相关函数。从引入自相关函数的目的看来,它是为了分辨形状不同的小x(t),所以代入E{X(t1)X(t2)}公式的值应该是每个小x(t)上取两个时刻的函数值自己相乘,这样才能反映小x(t)的差异。而因为前面所说,我们面对的不是一定会发生的某个小x(t),而是一组均可能发生的小x(t)。所以应该对每个样本函数取两个时刻的值函数值相乘后做统计平均来获得这一组样本函数的统计特性,或说是平均特性。在这里我想说一下自己对于统计平均曾经的错误理解和修正。物理实验处理数据时,我们求的都是算术平均,即每个记录值的权重是相同的。然而求期望时,我们算的是加权平均。看似矛盾但实则相同。这是因为算术平均时若是数值相同的数出现多次,那么这个数就被重复的代入多次,事实上某数出现的频率就是它的权重。而当引入概率密度函数时,因为横轴上的x是不会出现重复的值的,所以要用频率来做纵坐标表现某个x出现可能性的大小。
假设实际发生了n个样本函数(在实际工程中不可能测无穷组数据,只能是测n组数据认为已经包罗万象了),分别为<img src="https://pic4.zhimg.com/263d26176c80ad50d7df42b8a31ff6a3_b.png" data-rawwidth="134" data-rawheight="24" class="content_image" width="134">,这n个样本函数是可以出现表达式(形状样子)相同的,但是下标仍是各不相同,在这种前提下每个样本函数的权值是相同的。所以X(t)的自相关函数的表达式就应为: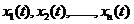 ,这n个样本函数是可以出现表达式(形状样子)相同的,但是下标仍是各不相同,在这种前提下每个样本函数的权值是相同的。所以X(t)的自相关函数的表达式就应为:
,这n个样本函数是可以出现表达式(形状样子)相同的,但是下标仍是各不相同,在这种前提下每个样本函数的权值是相同的。所以X(t)的自相关函数的表达式就应为:

应该注意的是样本函数下标的对应关系。
我认为比起<img src="https://pic4.zhimg.com/95d0123e63db373625a52f249c61288b_b.png" data-rawwidth="159" data-rawheight="26" class="content_image" width="159">,上边的具体操作式子才更为重要,因为它体现了自相关函数真正想表达的含义。因为自相关函数在实际工程中是被测出来,再拟合成某个数学表达式的,而不像题目中直接告诉一个成型的式子。所以在工程中如何对一系列测得的值进行关系正确的运算组合是至关重要的。而我认为挺多同学实际上并不明白测算自相关函数的方法,所以大家才会对书第85页的习题2.12产生不解(周荫清 随机过程理论)。他们没有理解为什么不同的样本函数之间不能相乘。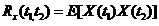 ,上边的具体操作式子才更为重要,因为它体现了自相关函数真正想表达的含义。因为自相关函数在实际工程中是被测出来,再拟合成某个数学表达式的,而不像题目中直接告诉一个成型的式子。所以在工程中如何对一系列测得的值进行关系正确的运算组合是至关重要的。而我认为挺多同学实际上并不明白测算自相关函数的方法,所以大家才会对书第85页的习题2.12产生不解(周荫清 随机过程理论)。他们没有理解为什么不同的样本函数之间不能相乘。
,上边的具体操作式子才更为重要,因为它体现了自相关函数真正想表达的含义。因为自相关函数在实际工程中是被测出来,再拟合成某个数学表达式的,而不像题目中直接告诉一个成型的式子。所以在工程中如何对一系列测得的值进行关系正确的运算组合是至关重要的。而我认为挺多同学实际上并不明白测算自相关函数的方法,所以大家才会对书第85页的习题2.12产生不解(周荫清 随机过程理论)。他们没有理解为什么不同的样本函数之间不能相乘。
这要从随机过程的研究对象与确定函数的异同说起。我想若是研究某个确定函数
<img src="https://pic4.zhimg.com/886c6d6477f90ccc584794d9dfc4fd23_b.png" data-rawwidth="34" data-rawheight="23" class="content_image" width="34">的特征,大家肯定不会觉得研究过程会和 的特征,大家肯定不会觉得研究过程会和<img src="https://pic1.zhimg.com/5e0c7ce74fe4b597d35100e4a0f092ac_b.png" data-rawwidth="35" data-rawheight="23" class="content_image" width="35">有什么联系。而随机过程的研究和确定函数的研究相同点就是:虽然随机过程中每次究竟会发生哪个样本函数并不确定,但是一旦发生了,则就是这个样本函数,不会串扰了。那么对于这个已成事实的样本函数,研究方法和对确定函数的研究是相同的。而随机过程与确定函数的不同就在于:这个样本函数并不是次次都会发生,所以要求统计特征。但是统计特征的获取是在把每个样本函数当做确定函数处理变换后,再对变换后的一系列新的样本函数求算数平均(类比X是一个连续的随机变量,其概率密度函数为f(x),y=g(x),求y的统计特性)。所以求算数平均前的操作都是限制在各个样本函数内部的,不同样本函数间不发生关联。求算数平均前的操作即为与确定函数相同的地方。
的特征,大家肯定不会觉得研究过程会和<img src="https://pic1.zhimg.com/5e0c7ce74fe4b597d35100e4a0f092ac_b.png" data-rawwidth="35" data-rawheight="23" class="content_image" width="35">有什么联系。而随机过程的研究和确定函数的研究相同点就是:虽然随机过程中每次究竟会发生哪个样本函数并不确定,但是一旦发生了,则就是这个样本函数,不会串扰了。那么对于这个已成事实的样本函数,研究方法和对确定函数的研究是相同的。而随机过程与确定函数的不同就在于:这个样本函数并不是次次都会发生,所以要求统计特征。但是统计特征的获取是在把每个样本函数当做确定函数处理变换后,再对变换后的一系列新的样本函数求算数平均(类比X是一个连续的随机变量,其概率密度函数为f(x),y=g(x),求y的统计特性)。所以求算数平均前的操作都是限制在各个样本函数内部的,不同样本函数间不发生关联。求算数平均前的操作即为与确定函数相同的地方。 有什么联系。而随机过程的研究和确定函数的研究相同点就是:虽然随机过程中每次究竟会发生哪个样本函数并不确定,但是一旦发生了,则就是这个样本函数,不会串扰了。那么对于这个已成事实的样本函数,研究方法和对确定函数的研究是相同的。而随机过程与确定函数的不同就在于:这个样本函数并不是次次都会发生,所以要求统计特征。但是统计特征的获取是在把每个样本函数当做确定函数处理变换后,再对变换后的一系列新的样本函数求算数平均(类比X是一个连续的随机变量,其概率密度函数为f(x),y=g(x),求y的统计特性)。所以求算数平均前的操作都是限制在各个样本函数内部的,不同样本函数间不发生关联。求算数平均前的操作即为与确定函数相同的地方。
有什么联系。而随机过程的研究和确定函数的研究相同点就是:虽然随机过程中每次究竟会发生哪个样本函数并不确定,但是一旦发生了,则就是这个样本函数,不会串扰了。那么对于这个已成事实的样本函数,研究方法和对确定函数的研究是相同的。而随机过程与确定函数的不同就在于:这个样本函数并不是次次都会发生,所以要求统计特征。但是统计特征的获取是在把每个样本函数当做确定函数处理变换后,再对变换后的一系列新的样本函数求算数平均(类比X是一个连续的随机变量,其概率密度函数为f(x),y=g(x),求y的统计特性)。所以求算数平均前的操作都是限制在各个样本函数内部的,不同样本函数间不发生关联。求算数平均前的操作即为与确定函数相同的地方。
然而既然引入自相关函数的目的是为了描述样本函数变化的剧烈程度,直观的想,若让我来做,我一定会在一个样本函数上取两个时刻的函数值,然后 让它们相减,看差距的大小来判断样本函数变化的剧烈程度。为什么书中会想到相乘呢?这个问题我想了许久,我发现当是两个随机变量的均值和方差相同时,似乎变化剧烈的样本函数的自相关函数是会大一些,但是我无法用严格的数学推导出来,而且关于样本函数长什么样就叫变化平缓,长什么样就叫变化剧烈也并没有定量的定义,所以我推不下去了。这时我突然发现随机过程题目中从来没有通过比较两个随机过程自相关函数的大小来确定它们哪个样本函数变化更剧烈。所以或许虽然自相关函数的引入是从描述样本函数的变化剧烈程度来的,但是自相关函数的真正作用并非如此。
纵观全书,非常多的统计特性量都是由自相关函数变化而成,所以自相关函数的真正意义是基本元素。
比如在随机过程的线性变换那章讲到了随机过程的均方积分和微分,可看出研究的对象仍是类似于确定函数的,比如是否连续,是否可导,然后再讨论积分微分结果的特性。但由于研究对象并非确定函数,所以引入均方连续放宽条件,即不需要每个样本函数都连续,而是大部分连续,即便极个别跳变在做统计平均后其影响也被削弱。这时连续就需要对相邻两时间函数值的差值求期望。但是为了数学处理的方便,我们不愿意每次都分辨差值的正负然后再让大的减去小的以避免不适当的抵消,我们经常直接对差值求平方后再求期望。在展开平方的过程中式子将变成<img src="https://pic3.zhimg.com/960ab50dee2789bb05abf0332ad48722_b.png" data-rawwidth="322" data-rawheight="24" class="content_image" width="322">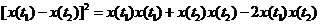
可以看出,展开后的每一项都是自相关函数的形式。
另外的例子有:<img src="https://pic1.zhimg.com/48836e7875877b9224b254f2728a010c_b.png" data-rawwidth="256" data-rawheight="46" class="content_image" width="256">
展开后会出现很多类似x(t1)x(t2)的项
所以用自相关函数作为基本元素的好处就是对于一个随机过程,只需实际测出一些值算出(拟合出)自相关函数的表达式,之后若想得到这个随机过程的其他数字特征都可基于测得的相关函数通过一些变换(如加减,积分,求导)得出,而不用每想求一个统计特征时都得实际测量一组值了。
而若是用<img src="https://pic2.zhimg.com/059c1376865ad993ebac10d2d3770e1d_b.png" data-rawwidth="88" data-rawheight="23" class="content_image" width="88">来做基本元素,实际操作起来不方便,因为对每一组值都要判断正负,而且若是需要求随机变量X(t)的二重积分,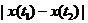 来做基本元素,实际操作起来不方便,因为对每一组值都要判断正负,而且若是需要求随机变量X(t)的二重积分,<img src="https://pic2.zhimg.com/059c1376865ad993ebac10d2d3770e1d_b.png" data-rawwidth="88" data-rawheight="23" class="content_image" width="88">也是用不上的。也就是说也是用不上的。也就是说<img src="https://pic2.zhimg.com/059c1376865ad993ebac10d2d3770e1d_b.png" data-rawwidth="88" data-rawheight="23" class="content_image" width="88">虽然可以描述样本函数的变化剧烈程度,但是用实验的方法测得它并不能为以后求其他的数字特征带来方便。而虽然可以描述样本函数的变化剧烈程度,但是用实验的方法测得它并不能为以后求其他的数字特征带来方便。而<img src="https://pic3.zhimg.com/8eaaa7e395c71dbc7e66ee93b7548f3a_b.png" data-rawwidth="94" data-rawheight="24" class="content_image" width="94">虽然省去了判断正负的麻烦,但是它同样不会作为组成其他数字特征求解表达式的基本项,因此无法被推广使用。
来做基本元素,实际操作起来不方便,因为对每一组值都要判断正负,而且若是需要求随机变量X(t)的二重积分,<img src="https://pic2.zhimg.com/059c1376865ad993ebac10d2d3770e1d_b.png" data-rawwidth="88" data-rawheight="23" class="content_image" width="88">也是用不上的。也就是说也是用不上的。也就是说<img src="https://pic2.zhimg.com/059c1376865ad993ebac10d2d3770e1d_b.png" data-rawwidth="88" data-rawheight="23" class="content_image" width="88">虽然可以描述样本函数的变化剧烈程度,但是用实验的方法测得它并不能为以后求其他的数字特征带来方便。而虽然可以描述样本函数的变化剧烈程度,但是用实验的方法测得它并不能为以后求其他的数字特征带来方便。而<img src="https://pic3.zhimg.com/8eaaa7e395c71dbc7e66ee93b7548f3a_b.png" data-rawwidth="94" data-rawheight="24" class="content_image" width="94">虽然省去了判断正负的麻烦,但是它同样不会作为组成其他数字特征求解表达式的基本项,因此无法被推广使用。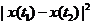 虽然省去了判断正负的麻烦,但是它同样不会作为组成其他数字特征求解表达式的基本项,因此无法被推广使用。
虽然省去了判断正负的麻烦,但是它同样不会作为组成其他数字特征求解表达式的基本项,因此无法被推广使用。
基于上述考虑,我开始思考或许自相关函数的引出顺序并不像书中介绍的那样最初是为了描述样本函数的变化剧烈程度。而是古人在研究一系列感兴趣的数字特征时发现它们的表达式中有着共同的基本项,因此产生了把这个基本项单独提出来研究的想法。
这样的研究思路让我联想到了很多学科。线性代数应该是上大学以来第一个明确提出基的思想的科目。它打碎事物千变万化纷杂的表象,探寻组成表面不同事物的基本分量的特性。基本分量具有无冗余和完备性的特征,这使得我们对看似复杂不同的事物的研究大大简化,也更接近于本质。物理的基是微积分中的微元,形状不同的物体经过无限分割后变成一堆性质相同的小块,研究清楚每个小块的作用特性,再应用线性叠加原理,即可获得复杂各异的问题的求解。信号与系统中傅里叶变换也是利用了基的思想,把千变万化的时域信号分解成正交完备的三角函数的线性叠加。若系统也是线性时不变的,则系统对时域信号的作用可看成是分别对每个组成时域信号的正弦分量作用再将每个正弦分量作用的结果进行线性叠加。这样一来不用对每个特别的时域信号进行基于信号本身特性进行分析,而是只要研究清楚正弦信号输入时的响应即可,由此得到通用的求解方法。
科学研究一个重要的关注点就是如何找到解决问题的通用方法,以省去冗余的分析和处理,而基本元素的确立为通用性奠定了基础。