Introduction
本文主要利用了RNN和C3D解决视频分类问题,其中RNN将CNN从每个视频帧中提取出来的特征进行时序上的编码,C3D对人脸表征和运动信息同时建模,最后再融合音频特征,完成视频分类。本文以59.02%的正确率较EmotiW 2015 53.8%的正确率高出许多。
Model
整体模型如图1,该模型主要由三个子模型组成:CNN-RNN,C3D和音频模型;CNN-RNN和C3D模型较为核心。本文单独训练三个子模型,每个子模型都能得到一个预测结果,最后根据它们在验证集上的表现,为三个子模型各分配一个权重,最后加权以获取最终得分。
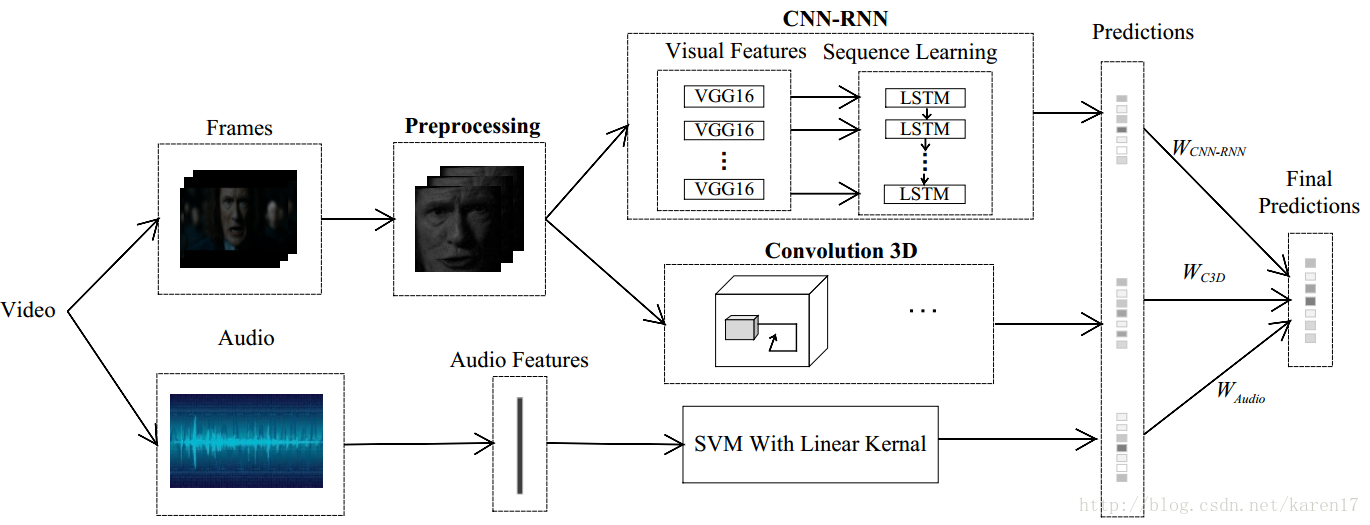
图1 整体视频分类模型
1. LSTM
LSTM的优势即在于它可以记住任意长度的数据,它有记忆单元,来控制数据的输入和遗忘,以及什么样的数据要被输出。
2. C3D
具体了解C3D的基本原理请参照博客上一篇文章:3D Convolutional Neural Networks for Human Action Recogn。
C3D可对人脸表征和运动信息同时建模。传统2D CNN中,仅在2D静态图像上执行卷积和池化操作,然而在3D卷积中,通过额外增加一个时间维度,来在空间和时间维度通过执行卷积操作,2D和3D卷积框架如图2所示。
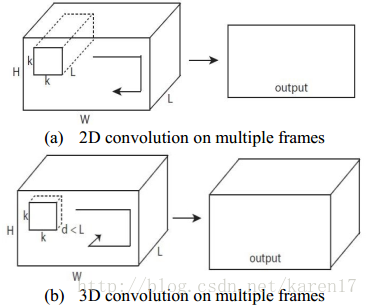
2D和3D比较

3. 组合CNN-RNN 和C3D网络
过去的一些工作表明,单独使用CNN-RNN和C3D模型都能在行为识别上取得较优结果,将二者组合更能增加预测性能。而音频特征差不多能提高约3%的正确率,由此这里利用OpenSmile toolkit提取了音频特征,再对音频特征训练了SVM。
回到整体模型图1,这里作者单独训练了三个子模型CNN-RNN,C3D和音频SVM,通过各子模型在验证集上的表现,为他们分配了权重Wcnn-rnn,Wc3d和Waudio,通过三个子模型的加权融合得到类别的最终得分。
Experiment
1. 数据集:AFEW6.0
该数据集中每个视频被标记为一种情绪,一共七种情绪:anger,disgust,fear,happiness,sad,surprise和neural,我们的任务就是为测试集中每个视频标记一种情绪标签。该数据集共有1750个短视频,其中训练集774个,验证集383个,测试集593个。
2. 一些实施细节
1)数据预处理部分,要先过滤掉non-faces的图片帧;
2)CNN-RNN模型中,CNN选用的是用FER2013数据集预训练过参数的VGG16-Face模型,将fc6层特征提出来输入到LSTM中。本文实验发现用一层LSTM、128个隐藏层单元效果最优。笔者试验过,发现这里有几点要注意:如果用VGG16模型的话,迭代多次训练过程的正确率也就50%左右,模型不能收敛;另外如果不用FER2013数据集对模型参数初始化,预测结果与论文也会差很多。
3)C3D模型:每个视频选了16个图片帧,如果该视频图片帧数少于16,则不断复制最后一帧。这里作者说:In the test stage, a series of 16 sequences is taken for each video by a stride of 8 frames,但笔者实际操作时候是在训练集和验证集中按一定间隔选取图片,间隔取决于每个视频的总体图片数,step=视频总帧数/15,也能达到与论文差不多的结果。
本文搭建的C3D网络有8个卷积层、5个下采样层和2个全连接层,最后一个softmax分类层,如图所示;模型中很多参数可以参见论文:Learning Spatiotemporal Features with 3D Convolutional Networks 。

C3D结构
Conclusion
本文为竞赛论文,比较好懂,作者对为什么选取一层、128神经元LSTM,为什么选CNN的fc6层特征以及最终组合了哪几个模型,这些细节都有详细实验证明,详见论文。但对如何将三个子模型融合部分一笔带过,这部分不是本文的重点。关于视频图像子模型融合问题,后期会写笔记:Recurrent Neural Networksfor Emotion Recognition in Video(EmotiW 2015)
用这个方法跑EmotiW2017的数据集,开源代码:https://github.com/ebadawy/EmotiW2017