这篇文章将classfication,localization和detection三种任务同时用一个CNN网络进行实现。并且提出了一个十分厉害的feature extractor:Overfeat。
在ImageNet数据集中,物体在图片中呈现的位置大致是在图片的中间,而且占据了图片很大的地方,但是感兴趣的物体分布却非常的不同。常用的解决方案有3种:1. 将CNN用在图片的不同位置,或者使用多尺寸的图片,但是这种方法使得CNN能够准确地抓住物体的关键部位,但是无法将整个物体划分出来;2. 使用滑窗的时候不仅仅只计算物体类别分布的可能性,同时也生成一个bounding box来划分整个物体;3. 累加在不同位置、不同大小的类别的置信区间。
1 Classification
1.1 Model design and training
训练图片尺寸:固定尺寸221*221。(所有的图片都下采样到256*256,然后从中随机抽取5个随机crops和他们的horizontal flips)
mini-batch:128
weights initialization:(μ, σ)=(0, 0.01)
SGD,momentum为0.6,L2 weight decay为0.00005
learning rate初始化为0.05,然后在(30,50,60,70,80) epoch后分别下降0.5
在第6,7层的Dropout rate为0.5
和AlexNet的区别在于:1. 没有使用任何normalization的方法;2. pooling是不重叠的; 3.1,2层的stride为2,可以获得更大的feature map。
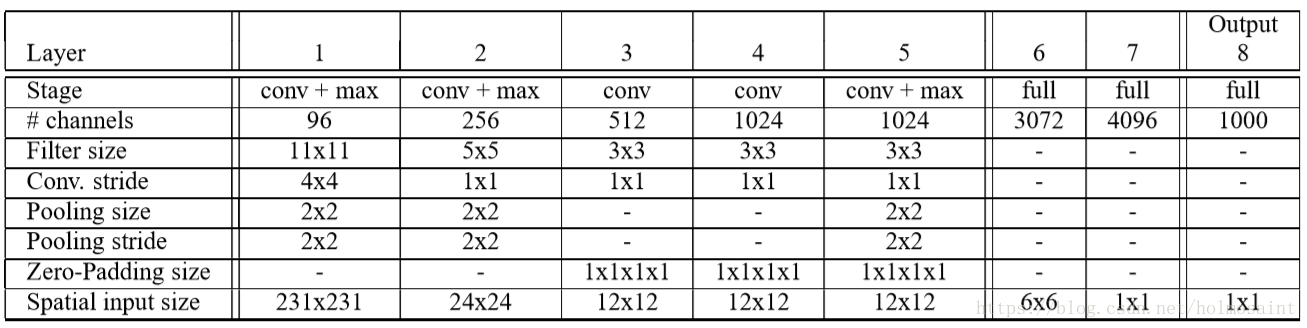
fast model
accurate model
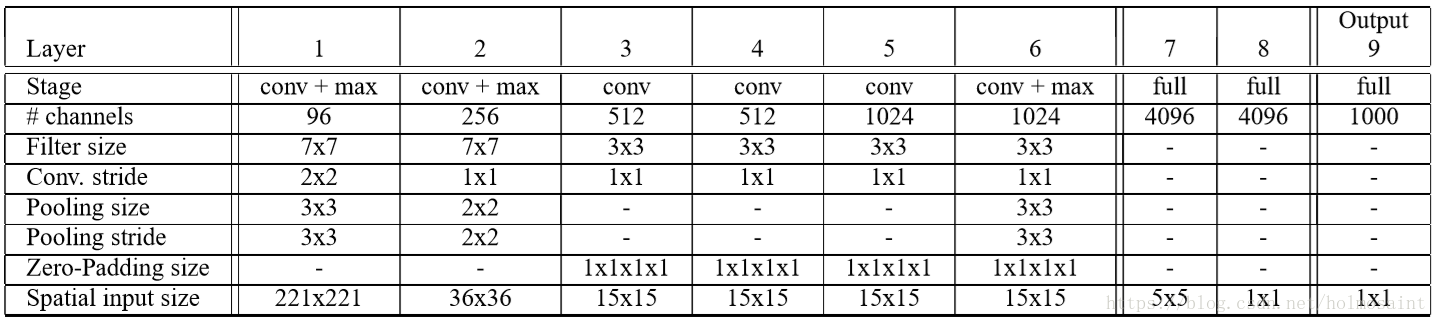
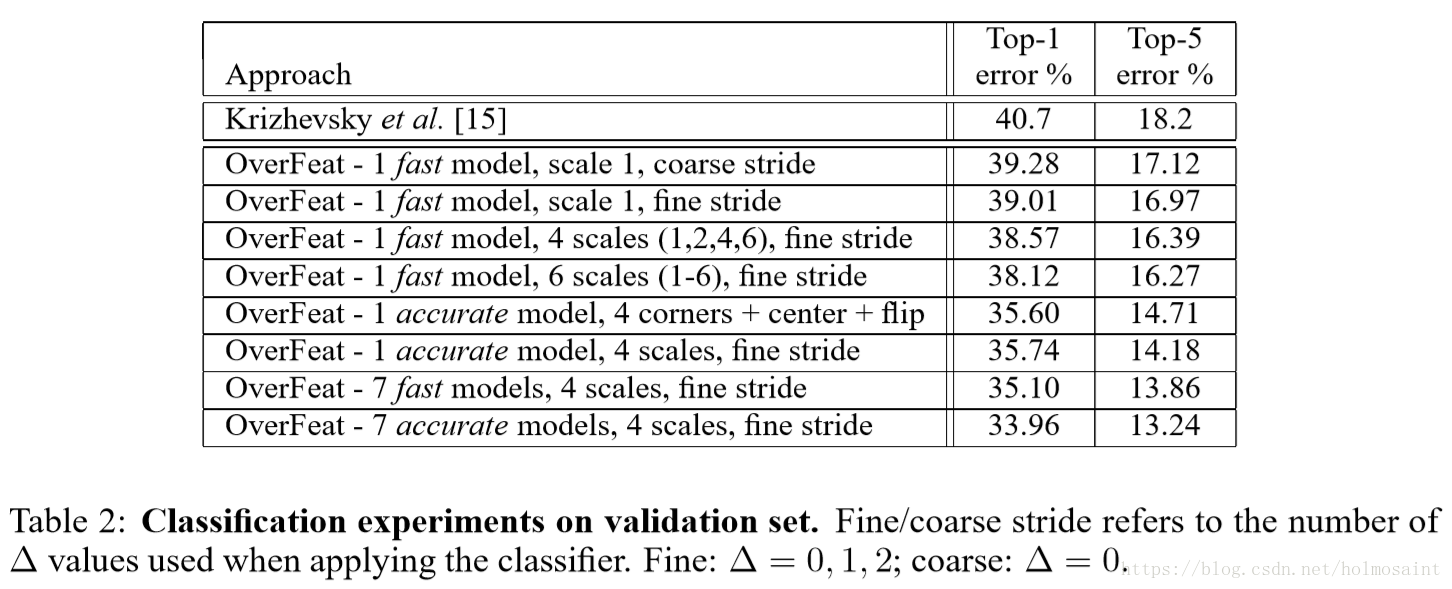
accurate model(14.18%)相比fast model而言(16.39%)降低了2.21%的error rate,但是连接数几乎是两倍。
1.2 Multi-scale classification
在AlexNet中使用的是multi-view voting的方式来进行inference,具体来说就是选取原始图片中的5个部分(中间和4个角)的crops以及它们的horizontal flips一共10个crops,然后丢到网络中平均。但是这种方法不可避免的忽视掉了图片中很多地方。
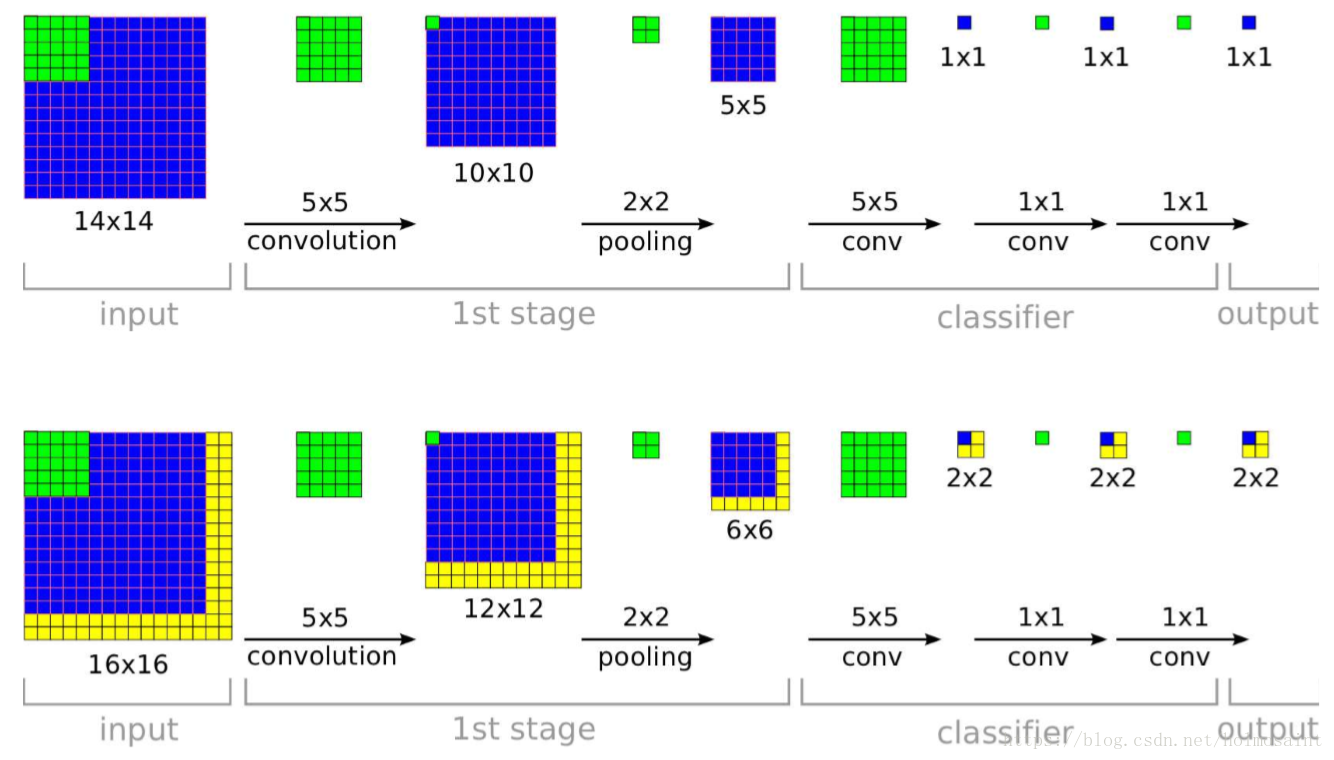
在这篇文章当中作者选择了densely将整个图片扔到网络中以便涉及到图片中的每一个位置。这使得任何尺寸的图片可以扔到网络中去(不必是和training中一样的尺寸),最终得到的结果是一个取决于input size的C-dimension vector。(C就是catogary的总数)
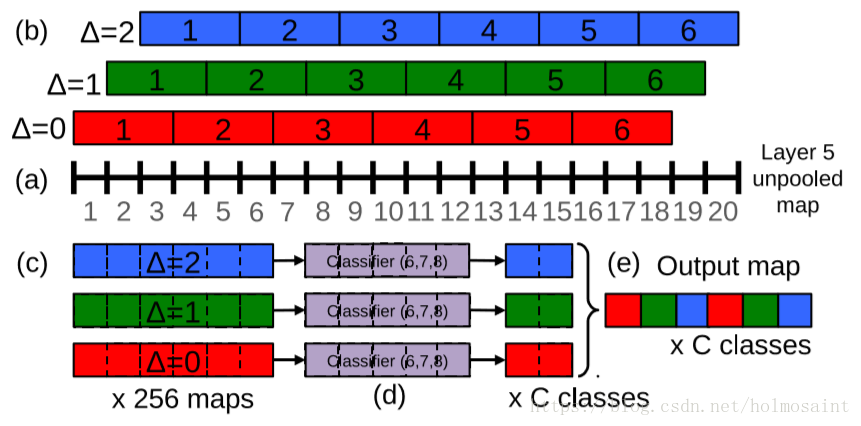
但是由于两次stride>1的conv和三次pooling(这都属于下采样的过程),使得图片最终被缩放了2*3*2*3=36倍,于是我们最终在整个图片上做inference的时候,每个坐标轴上得36个pixel才能出一个classfication vector,这显然是非常粗糙的。于是使用了一种offset pooling的方式替换最后的naive max pooling,可以使得下采样的比例变成12×。
offset pooling
在pooling的时候stride (Δx,Δy)是{0,1,2}的9种组合,所以说最后每一张input image可以得到9张feature map。一维的offset pooling的示意图如下图所示:
fully convoluted
在inference的时候,最后的fc layer同样地被视为convolution layer用以应对不同输入大小的图片。