这篇论文主要利用了RNN和C3D解决视频分类问题,其中RNN将CNN从每个视频帧中提取出来的特征进行时序上的编码,C3D对人脸表征和运动信息同时建模,最后再融合音频特征,完成视频分类。本文以59.02%的正确率较EmotiW 2015 53.8%的正确率高出许多。
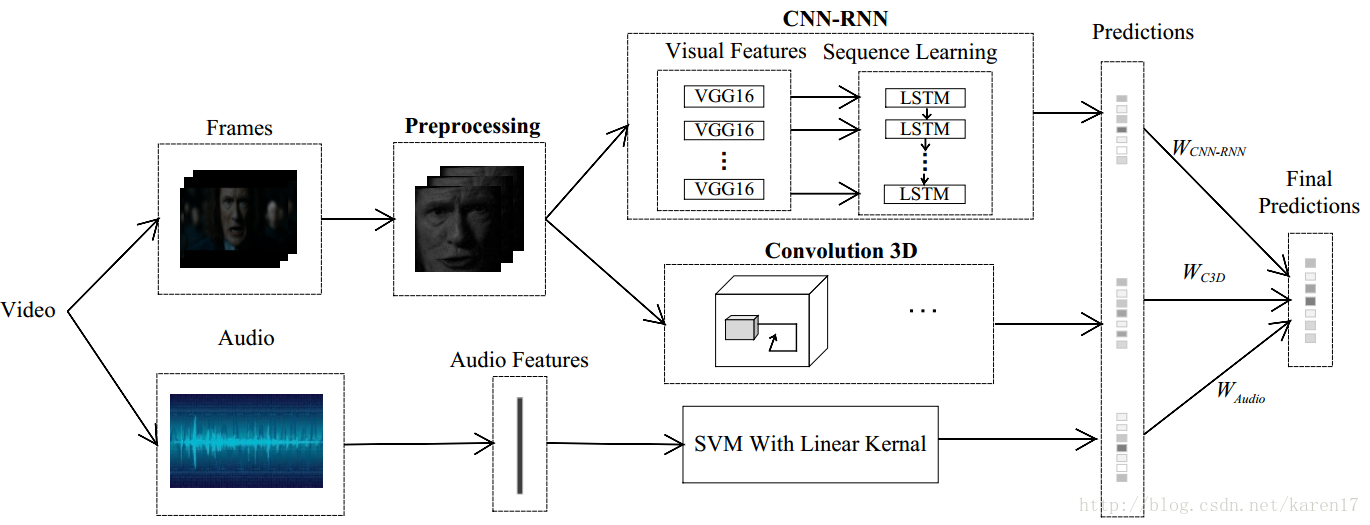
整体模型如图1,该模型主要由三个子模型组成:CNN-RNN,C3D和音频模型;CNN-RNN和C3D模型较为核心。本文单独训练三个子模型,每个子模型都能得到一个预测结果,最后根据它们在验证集上的表现,为三个子模型各分配一个权重,最后加权以获取最终得分。
Experiment
1. 数据集:AFEW6.0
该数据集中每个视频被标记为一种情绪,一共七种情绪:anger,disgust,fear,happiness,sad,surprise和neural,我们的任务就是为测试集中每个视频标记一种情绪标签。该数据集共有1750个短视频,其中训练集774个,验证集383个,测试集593个。
2. 一些实施细节
1)数据预处理部分,要先过滤掉non-faces的图片帧;
2)CNN-RNN模型中,CNN选用的是用FER2013数据集预训练过参数的VGG16-Face模型,将fc6层特征提出来输入到LSTM中。本文实验发现用一层LSTM、128个隐藏层单元效果最优。有几点要注意:如果用VGG16模型的话,迭代多次训练过程的正确率也就50%左右,模型不能收敛;另外如果不用FER2013数据集对模型参数初始化,预测结果与论文也会差很多。
3)C3D模型:每个视频选了16个图片帧,如果该视频图片帧数少于16,则不断复制最后一帧。但在训练集和验证集中按一定间隔选取图片,间隔取决于每个视频的总体图片数,step=视频总帧数/15,也能达到与论文差不多的结果。
本文搭建的C3D网络有8个卷积层、5个下采样层和2个全连接层,最后一个softmax分类层,如图所示;模型中很多参数可以参见论文:Learning Spatiotemporal Features with 3D Convolutional Networks 。

C3D结构
Conclusion
本文为竞赛论文,比较好懂,作者对为什么选取一层、128神经元LSTM,为什么选CNN的fc6层特征以及最终组合了哪几个模型,这些细节都有详细实验证明,详见论文。但对如何将三个子模型融合部分一笔带过,这部分不是本文的重点。关于视频图像子模型融合问题,后续会写Recurrent Neural Networksfor Emotion Recognition in Video(EmotiW2015的论文)笔记。