目录
1. 论文&代码源
《MULTI-VIEW GAIT RECOGNITION USING 3D CONVOLUTIONAL NEURAL NETWORKS》
论文地址:https://mediatum.ub.tum.de/doc/1304824/document.pdf
代码下载地址: 作者未提供
2. 论文亮点
本文作者提出了一个使用三维卷积的深度卷积网络,用于多视角的步态识别,从而捕捉时空特征。
模型的输入数据由灰度图像和光流组成,以增强色彩不变性(“color invariance”应该是这个词,原文打错了。。。)
3. 模型结构
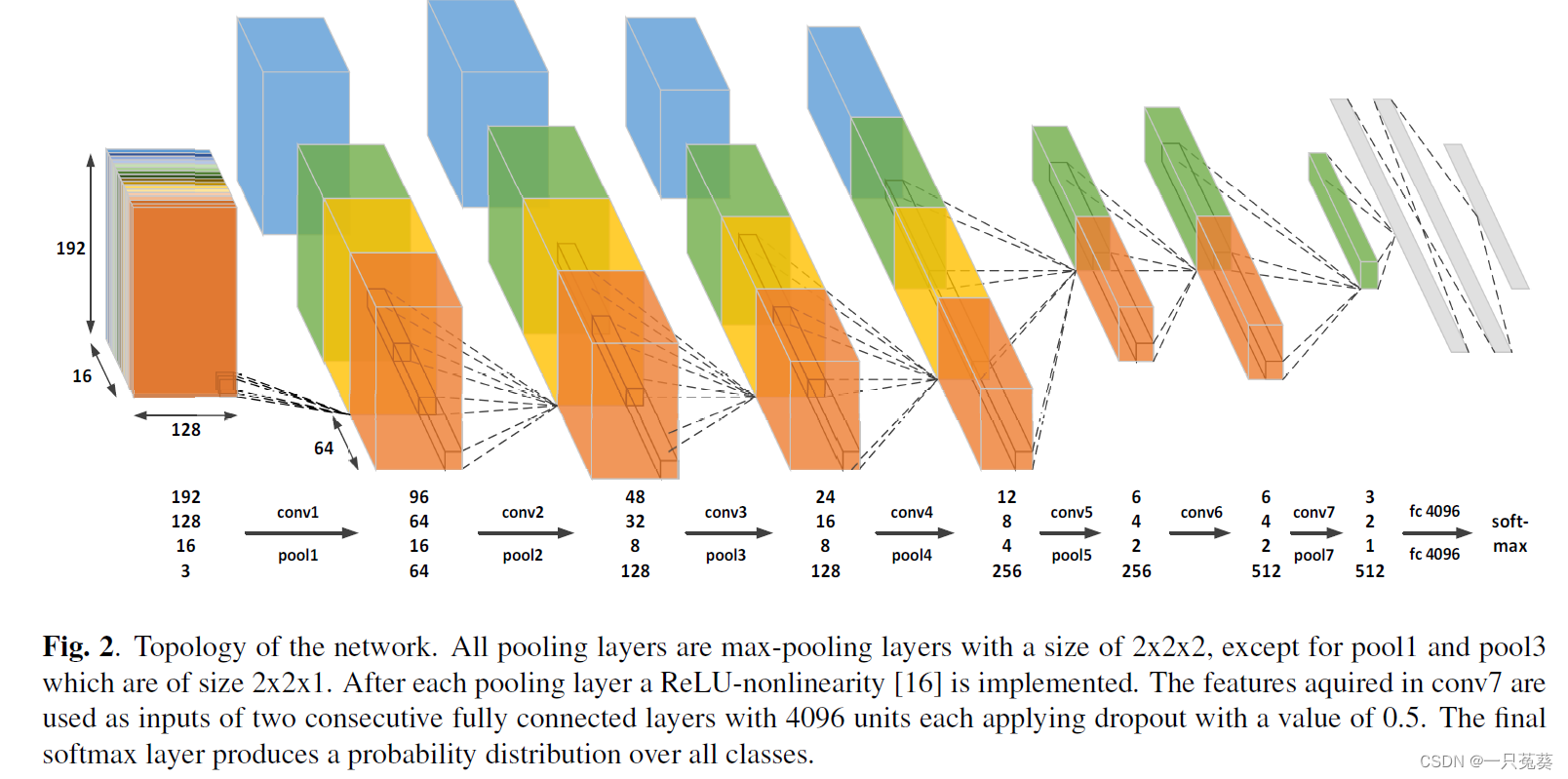
3.1 技术路线
模型结构如上图所示,将帧长度设置为 16 16 16,以平衡捕获足够的时间信息和计算复杂度;池化层尺寸均为 2 × 2 × 2 2 \times 2 \times 2 2×2×2,第 1 1 1、 3 3 3层不进行池化操作,避免过早折叠时间信息;所有卷积层尺寸均为 3 × 3 × 3 × N 3 \times 3 \times 3 \times N 3×3×3×N,通道数 N = [ 3 , 64 , 128 , 128 , 256 , 256 , 512 ] N=[3, 64, 128, 128, 256, 256, 512] N=[3,64,128,128,256,256,512],最后一个卷积层的输出是两个连续全连接层的输入,每个全连接层有 4096 4096 4096个神经元,每个神经元的dropout值为 0.5 0.5 0.5;最后一层使用softmax函数产生分类的概率分布。
3.2 数据预处理
颜色和着装变化是步态识别算法中十分重要的影响因素,现有数据集提供的衣着变化类型较少,一个理想的数据集应包括同一受试者不同衣着条件的多个序列,这限制了模型学习色彩不变性的能力,为了解决这一问题,作者对输入图像进行了下述改造。
第一个通道: 将RGB图像转换为灰度图
第二三个通道: 利用【Secrets of optical flow estimation and their principles】一文中的方法,计算 x x x、 y y y方向上的光流,目的是使用光流来增强网络学习步态特征的能力。
训练和测试过程使用有重叠的帧序列,具体解释如下:
一个受试者主体可能会在第一帧出现(与该受试者)不相配的相似姿态,网络会学习这个起始姿态与该受试者主动联系起来,为了避免这种情况的出现,一个序列被分割成16帧,比如一个 50 50 50帧的视频就被分为 ( 1 − 16 ) , ( 2 − 17 ) , . . . , ( 35 − 50 ) (1-16), (2-17), ..., (35-50) (1−16),(2−17),...,(35−50)这些片段。
3.3 训练和测试
为了使网络学习到“纯净”的步态特征,而不受步行速度、衣着等变化因素的影响,作者将训练集和测试集进行了一定的调整:因为原始数据集的训练集和测试集是在不同条件下(被记录)的,将两者分别分为原数据集的 2 3 \frac 23 32和 1 3 \frac 13 31,然后将 2 3 \frac 23 32训练集数据和 2 3 \frac 23 32测试集数据结合起来,形成新的训练集,剩下的 1 3 \frac 13 31同理,生成新的测试集。
网络采用随机梯度下降法进行训练,对USF和CASIA-B数据集的初始学习率为 1 0 − 4 10^{-4} 10−4,CMU为 1 0 − 5 10^{-5} 10−5,momentum系数为 0.9 0.9 0.9,衰减系数为 5 ∗ 1 0 − 4 5*10^{-4} 5∗10−4,每10个epoch,学习率下降10倍。
4.实验结果
4.1 CMU
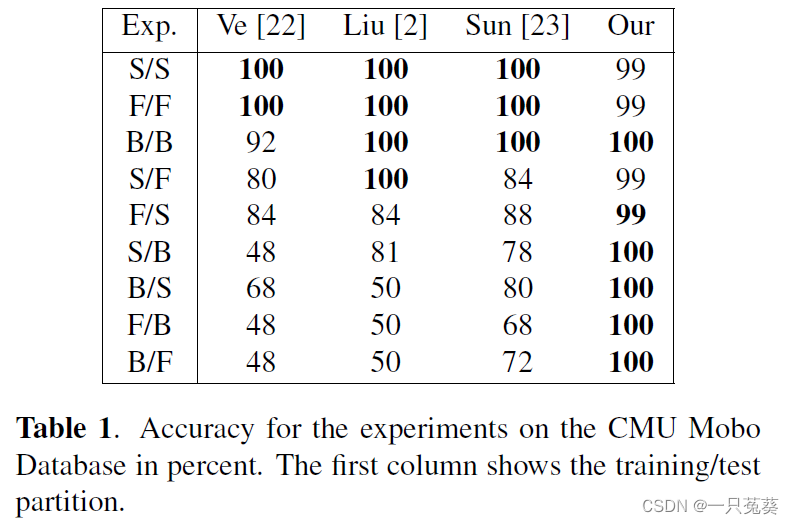
一共进行了9次实验,其中3次使用相同的条件进行训练和测试,6次使用不同条件数据集拆分后的数据进行训练和测试。
4.2 USF
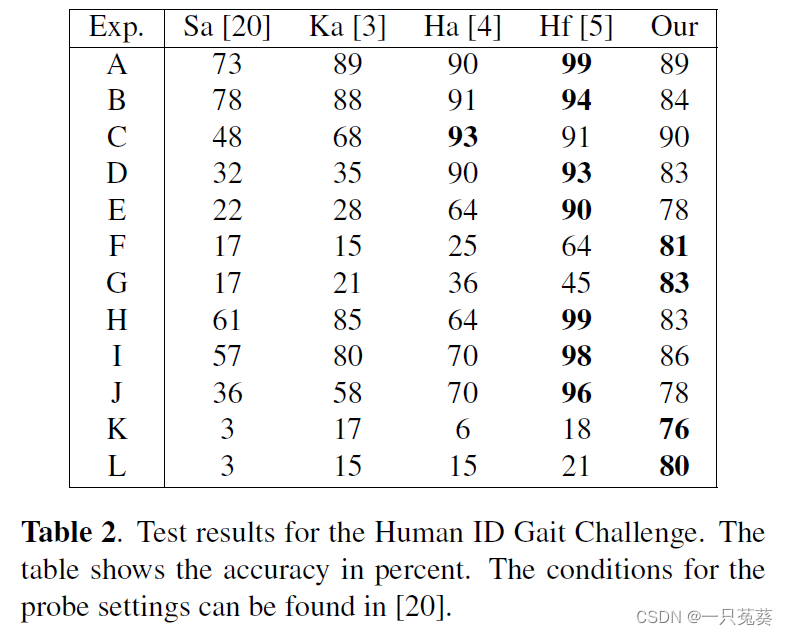
一共进行了12次实验,其中定义了1个训练集和12个测试集,具体条件同【The humanid gait challenge problem: Data sets, performance, and analysis】这篇论文,所有实验都是使用“训练/测试”数据集。
4.3 CAISA-B
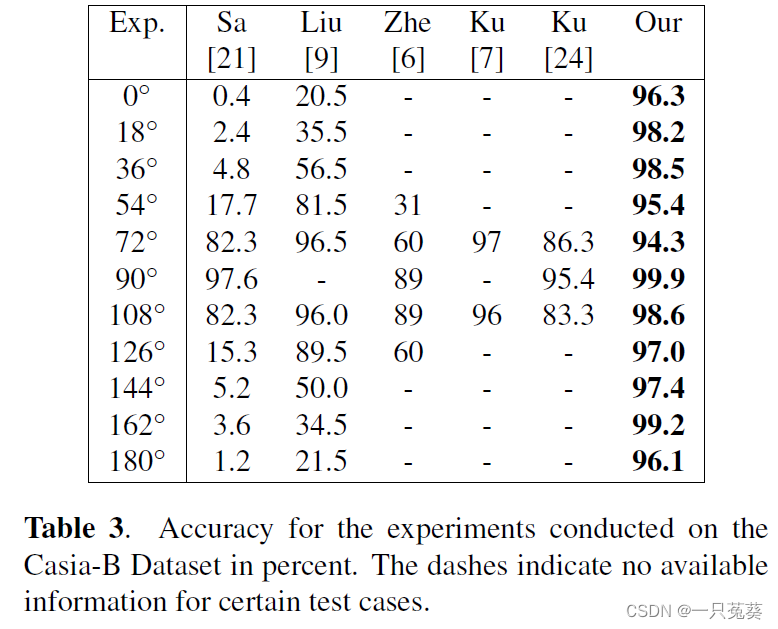
训练实验使用 90 ° 90° 90°视角下的6个步态序列;测试实验使用各个视角下的6个步态序列。
5.总结
作者提出了一种基于卷积神经网络技术的模型,提取时空特征进行分类。在不同数据集的实验中,这种表示方法的准确率很高,指出了CNN在步态识别方面的巨大潜力。
此外,由于少量的变异和小规模的数据库,过度拟合是一个潜在的问题。除了更好的硬件和更大的网络结构可以提高性能外,作者期待一个有更多情况更大规模的数据集的出现。使用包括成千上万个在行走行为和外观上有很大差异的主体的数据集,可以进一步提高性能,减少过度拟合。
0. 知识补充
0.1 光流法
光流(Optical flow or optic flow)是关于视域中的物体运动检测中的概念。用来描述相对于观察者的运动所造成的观测目标、表面或边缘的运动。光流法在样型识别、计算机视觉以及其他影像处理领域中非常有用,可用于运动检测、物件切割、碰撞时间与物体膨胀的计算、运动补偿编码,或者通过物体表面与边缘进行立体的测量等等。
光流法实际上是通过检测图像像素点的强度随时间的变化进而推断出物体移动速度及方向的方法。
光流定义另外两种有趣的说法:
1.光流就是你能感觉到的视觉运动
2.光流是空间运动物体在观察成像平面上的像素运动的瞬时速度(这种似乎更加合适)
光流的概念最早是Gibson在1950年提出。
被称为「光流」的原因:当人的眼睛观察运动物体时,物体在人眼的视网膜上形成一系列连续变化的图像,这一系列连续变化的信息不断“流过”视网膜(即图像平面),好像一种光的“流”,故称之为光流(optical flow)。
光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况。
参考博客: