1.首先对训练集的信息进行了解


data_train = pd.read_csv('train.csv') data_test = pd.read_csv('test.csv') data_train.info()

我们看到有些是空的,有些是全的。
如果想要对data进行详细的了解,用excel看比较方便。
2.特征分析
1)Pclass
阶层高的贵族群众往往住在头等舱,或许能够更快的跑到甲板获救;而阶层低的普通群众人多且住在二三等舱,生存几率可能会比较低。
sns.barplot(x='Pclass',y='Survived',data=data_train) plt.show()
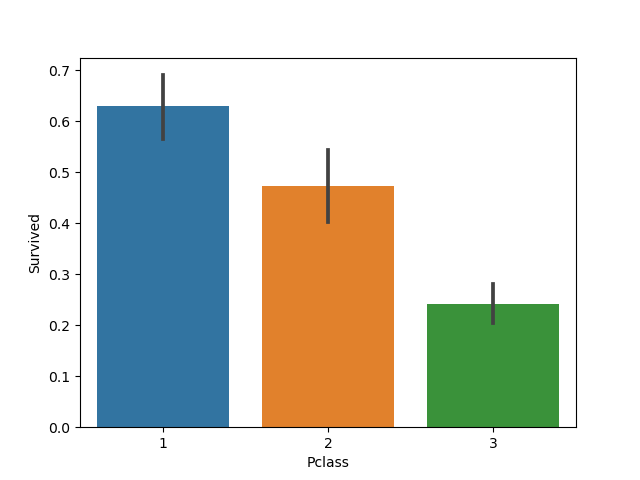
hh,资本主义……
2)Sex
自古以来lady first,大难临头的时候,欧美的绅士们还是这样吗?
sns.barplot(x='Sex',y='Survived',data=data_train) plt.show()

3)Age
年龄有几个是缺漏的,但是不多,我们先看没有缺漏的生存情况。
reduced_data_train=data_train.dropna(subset=['Age']) Survived_reduced_data_train=reduced_data_train.loc[reduced_data_train['Survived']==1] Died_reduced_data_train=reduced_data_train.loc[reduced_data_train['Survived']==0] sns.kdeplot(data=Survived_reduced_data_train['Age'],shade=True) sns.kdeplot(data=Died_reduced_data_train['Age'],shade=False) plt.show()

(蓝色是存活)
年轻人跑的快,死的也快?但是我们还是看的到,左边有个极大值,说明在大概5岁以下的婴幼儿生存几率较大。
4)SibSp和Parch
有些人跟着亲人和朋友一起旅行,会不会也会有影响?
data_train['FamilySize']=data_train['SibSp']+data_train['Parch']+1 sns.barplot(x="FamilySize", y="Survived", data=data_train) plt.show()

有点影响,太多和太少死的几率会大。
三、数据清洗
对于一些不必要的或是缺漏太多的数据这里把他们都删除,同时给一些分类变量标上标签值、缺漏少的数据给补充上。
full_data=[data_train,data_test] for dataset in full_data: dataset.loc[dataset['Sex']=='male','Sex']=1 dataset.loc[dataset['Sex'] == 'female', 'Sex'] = 0 dataset['Sex'] = dataset['Sex'].astype(int) dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1 dataset['IsAlone'] = 0 dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1 dataset['Embarked'] = dataset['Embarked'].fillna('S') dataset.loc[dataset['Embarked'] == 'S', 'Embarked'] = 0 dataset.loc[dataset['Embarked'] == 'C', 'Embarked'] = 1 dataset.loc[dataset['Embarked'] == 'Q', 'Embarked'] = 2 dataset['Embarked'] = dataset['Embarked'].astype(int) dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0 dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1 dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2 dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3 dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 dataset.loc[ dataset['Age'].isnull(), 'Age'] = 5 dataset['Age'] = dataset['Age'].astype(int) drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp','Parch','Fare'] data_train = data_train.drop(drop_elements, axis = 1) X_test= data_test.drop(drop_elements, axis = 1)
把训练与测试集都清理好就可以开始预测了
四、建模和预测
鉴于没什么经验,直接选用其他博主的建模方法。
x = data_train.drop('Survived', axis = 1) y=data_train['Survived'] log_reg=LogisticRegression() log_reg.fit(x,y) svm_clf = SVC() svm_clf.fit(x, y) tree_clf=DecisionTreeClassifier() tree_clf.fit(x, y) print(log_reg.score(x, y)) print(svm_clf.score(x, y)) print(tree_clf.score(x, y))

最后一个模拟程度较高选用最后一个进行预测
RF=RandomForestClassifier(random_state=1) PRF=[{'n_estimators':[10,100],'max_depth':[3,6],'criterion':['gini','entropy']}] GSRF=GridSearchCV(estimator=RF, param_grid=PRF, scoring='accuracy',cv=2) scores_rf=cross_val_score(GSRF,x,y,scoring='accuracy',cv=5) model=GSRF.fit(x, y) pred=model.predict(X_test) output=pd.DataFrame({'PassengerId':data_test['PassengerId'],'Survived':pred}) output.to_csv('gender_submission.csv', index=False)
五、提交
 可还行
可还行
六、总结
①pipeline还不太熟
②模型领悟不深
③其实可以每个模型全都试一遍,然后GridSearchCV搜索最优的参数,一个一个进行预测,这种做法技术含量最低,但是操作难度比较大,往后应掌握
④加强对数据的认识
写在最后:
当步入一个新的领域时,往往都是万事开头难。这不懂,那不懂,不去学就永远都不懂,而当你真正的静下心来,去探索新的领域、真正掌握新的知识时,回首望去,你会感谢坚持的自己。
———纪念第一个数据挖掘的实战项目