一元线性回归模型的数学形式
一元线性回归是描述两个变量之间相关关系的最简单的回归模型。自变量与因变量间的线性关系的数学结构通常用式(1)的形式:
y = β0 + β1x + ε (1)
其中两个变量y与x之间的关系用两部分描述。一部分是由于x的变化引起y线性变化的部分,即β0 + β1x,另一部分是由其他一切随机因素引起的,记为ε。该式确切的表达了变量x与y之间密切关系,但密切的程度又没有到x唯一确定y的这种特殊关系。
式(1)称为变量y对x的一元线性回归理论模型。一般称y为被解释变量(因变量),x为解释变量(自变量),β0和β1是未知参数,成β0为回归常数,β1为回归系数。ε表示其他随机因素的影响。一般假定ε是不可观测的随机误差,它是一个随机变量,通常假定ε满足:
 (2)
(2)
对式(1)两边求期望,得
E(y) = β0 + β1x, (3)
称式(3)为回归方程。
一般情况下,对所研究的某个实际问题,获得n组样本观测值(x1, y1),(x2, y2),...,(xn, yn),如果它们符合模型(1),则
yi = β0 + β1xi + εi, i = 1, 2, ..., n (4)
由式(2)有
 i = 1, 2, ..., n. (5)
i = 1, 2, ..., n. (5)
通常还假定n组数据是独立观测的,因而y1,y2,...,yn与ε1,ε2,...,εn都是相互独立的随机变量,而xi(i = 1, 2, ..., n)是确定性变量,其值是可以精确测量和控制的。称式(4)为一元线性回归模型。
对式(4)两边分别求数学期望和方差,得
E(yi) = β0 + β1xi, Var(yi) = σ2, i = 1, 2, ..., n (6)
可知 。
。
E(yi) = β0 + β1xi从平均意义上表达了变量y与x的统计规律性。在应用上,人们经常关系的正是这个平均值。
在实际问题中,为了方便对参数β0,β1作区间估计和假设检验,还假定模型(1)中误差项ε遵从正态分布,即
ε ~ N(0,σ2), (7)
由于ε1,ε2,...,εn是ε的独立同分布的样本,因而有
εi ~ N(0,σ2), i = 1, 2, ..., n (8)
在εi遵从正态分布的假定下,进一步有随机变量y,也遵从正态分布
yi ~ N(β0 + β1xi, σ2), i = 1, 2, ..., n (9)
回归参数β0 , β1的估计
普通最小二乘估计(ordinary least squares estimate, OLSE)
对每一个样本观测值(xi, yi),最小二乘法考虑观测值yi与其回归值 的离差越小越好,综合地考虑n个离差值,定义离差平方和为
的离差越小越好,综合地考虑n个离差值,定义离差平方和为
 (10)
(10)
最小二乘法,就是寻找参数β0,β1的估计值 ,使式(10)定义的离差平方和达极小,即寻找
,使式(10)定义的离差平方和达极小,即寻找 满足
满足
 (11)
(11)
依照式(11)求出的就称为回归参数β0,β1的最小二乘估计。称
 (12)
(12)
为yi(i = 1, 2,...,n)的回归拟合值,简称回归值或拟合值。称
 (13)
(13)
为yi(i = 1, 2, ..., n)的残差。
从式(11)中求出是一个求极值问题。由于Q是关于的非负二次函数,因而它的最小值总是存在的,利用微积分求极值原理,应满足下列方程组
 (14)
(14)
求解正规方程组(14)得β0,β1的最小二乘估计(OLSE)为
 (15)
(15)
其中 。
。
记
 (16)
(16)
 (17)
(17)
则式(15)可简写为
 (18)
(18)
可知
 (19)
(19)
可见回归直线 是通过点
是通过点 的,从物理学角度来看,
的,从物理学角度来看, 是n个样本观测值(xi, yi)的重心,也就是说回归直线通过样本的重心。
是n个样本观测值(xi, yi)的重心,也就是说回归直线通过样本的重心。
最小二乘估计的性质
一、线性性
估计量 为随机变量yi的线性函数。由式(18)得
为随机变量yi的线性函数。由式(18)得
 (20)
(20)
其中 是yi的系数,所以
是yi的系数,所以 是yi的线性组合。同理
是yi的线性组合。同理
 (21)
(21)
二、无偏性
 均为β0,β1的无偏估计。由于xi是非随机变量,yi = β0 + β1xi + εi, E(εi) = 0,因而有
均为β0,β1的无偏估计。由于xi是非随机变量,yi = β0 + β1xi + εi, E(εi) = 0,因而有
E(yi) = β0 + β1xi (22)
再由式(18)可得
 (23)
(23)
 (24)
(24)
无偏估计的意义是:如果屡次变更数据,反复求β0,β1的估计值,这两个估计量没有高估或低估的系统趋向,它们的平均值将趋向于β0,β1,进一步有
 (25)
(25)
这表明 回归值是E(y)的无偏估计,也说明
回归值是E(y)的无偏估计,也说明 与真实值y的平均值是相同的。
与真实值y的平均值是相同的。
三、最小方差性(最优性、有效性)
方差用来评估变量的波动状况。由y1,y2,..,yn相互独立,Var(yi) = σ2及式(25)得
 (26)
(26)
方差的大小表示随机变量取值波动的大小。假设反复抽取容量为n的样本建立回归方程,每次计算 的值是不同的,
的值是不同的, 正是反映这些的差异程度。
正是反映这些的差异程度。
从式(26)可以看到,回归系数不仅与随机误差的方差σ2有关,还与自变量x的取值波动程度有关。如果x取值比较分散,即x的波动较大,则的波动就小,β1的估计量就比较稳定;反之,如果原始数据x是在一个较小的范围内波动,那么β1的估计值稳定性就差。
类似地,有
 (27)
(27)
由式(27)可知,回归常数 的方差不仅与随机误差的方差σ2和自变量x的取值波动程度有关,还与样本数量n有关,n越大,
的方差不仅与随机误差的方差σ2和自变量x的取值波动程度有关,还与样本数量n有关,n越大, 越小。
越小。
所以从式(26)和(27)可以看出,方差的意义可以用来指导抽样。想要是β0,β1的估计量 更稳定,在收集数据时,就要考虑将x取的分散些,样本量尽量大一些。
更稳定,在收集数据时,就要考虑将x取的分散些,样本量尽量大一些。
因为 都是n个独立正态随机变量y1,y2,...,yn的线性组合,因而
都是n个独立正态随机变量y1,y2,...,yn的线性组合,因而 也遵从正态分布。有
也遵从正态分布。有
 (28)
(28)
 (29)
(29)
的协方差
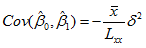 (30)
(30)
式(30)说明,在 =0时,
=0时, 与
与 不相关,在正态假定下独立;在≠0时不独立。它揭示了回归系数之间的关系状况。
不相关,在正态假定下独立;在≠0时不独立。它揭示了回归系数之间的关系状况。
之前给出的回归模型随机误差项εi等方差及不相关的假定条件,这个条件称为Gauss-Markov条件,即
 (31)
(31)
在此条件下可以证明,与分别是β0与β1的最佳线性无偏估计(best linear unbiased estimate, BLUE),也称为最小方差线性无偏估计。BLUE即指在β0和β1的一切线性无偏估计中,它们的方差最小。
进一步,对于固定的x0,有 也是y1,y2,...,yn的线性组合,且
也是y1,y2,...,yn的线性组合,且
 (32)
(32)
即 是E(y0)的无偏估计,且
是E(y0)的无偏估计,且 的方差随给定的x0值与的距离|x0-|的增大而增大。即当给定的x0与x的样本平均值相差较大时,的估计值波动就增大。指导意义:应用回归方程进行控制和预测时,给定的x0值不能偏离样本均值太大。
的方差随给定的x0值与的距离|x0-|的增大而增大。即当给定的x0与x的样本平均值相差较大时,的估计值波动就增大。指导意义:应用回归方程进行控制和预测时,给定的x0值不能偏离样本均值太大。