写在开头
最近在学习一些关于机器学习的基础算法,结合学习Peter Harrington的《机器学习实战》和李航老师的《统计学习方法》两本书以及网上前辈的笔记,写下了以下的学习过程。
代码环境:Pytharm/Python3.7
内容有参考也有自己的想法,由于自己的理解不足,文章肯定存在很多错误,还恳请各位批评指正。
一 . K-近邻算法(KNN)概述
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
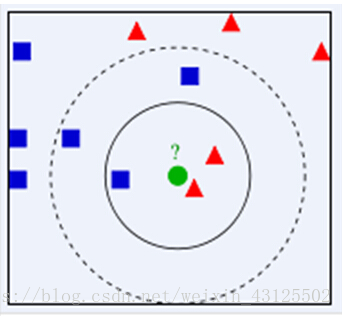
从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形
由此也说明了KNN算法的结果很大程度取决于K的选择。
我们可以看到,KNN本质是基于一种数据统计的方法(memory-based learning,也叫instance-based learning)! ,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。
二.算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
KNN算法源代码
编程环境Python 3.7
import operator
import array
from numpy import *
def create_data():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
# 用于分类的输入向量是inX,输入的训练样本集为dataSet,
# 标签向量为labels,最后的参数k表示用于选择最近邻居的数目,
# 其中标签向量的元素数目和矩阵dataSet的行数相同
def classify0(inX, dataSet, labels, k):
# dataset是一个数组,shape函数是用于建立矩阵,shape[0]代表数组的行数
dataSetSize = dataSet.shape[0]
# tile(A,reps)共有2个参数,A指待输入数组,reps则决定A重复的次数。
# 整个函数用于重复数组A来构建新的数组。
# reps=(dataSetSize, 1)代表行方向重复dataSetSize次,列方向重复1次
# 输入向量与输入样本集做差,是矩阵做差
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# 平方
sqDiffMat = diffMat**2
# 当加入axis = 1,以后就是将一个矩阵的每一行向量相加
sqDistances = sqDiffMat.sum(axis=1)
# 开方得到距离
distances = sqDistances**0.5
# argsort()是将相应数组按照从小到大顺序排列
# 但是返回的不是排序之后的结果(值),而是这些值在原理数组中的位置(下标)
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range (k):
# 取排序后对应的labels
voteIlabel = labels[sortedDistIndicies[i]]
# 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
# 每种label出现的次数都记录下来
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
maxCount = 0
for key, value in classCount.items():
if value> maxCount:
maxCount = value
calsses_ = key
# 返回发生频率最高的元素标签
return calsses_
def main():
dataSet,labels = create_data()
k = 3
input = array([1.1,0.3])
output = classify0(input, dataSet, labels, k)
print("测试数据为:{},分类结果为:{}".format(input,output))
main()
整个代码分为三个部分,第一部分是创造测试数据及待测数据,第二部分即为KNN算法的实现过程,第三部分是输出。整个代码比较难得理解的就下面这段代码
for i in range (k):
# 取排序后对应的labels
voteIlabel = labels[sortedDistIndicies[i]]
# 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
# 每种label出现的次数都记录下来
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
这段代码就是遍历与待测数据最近的K个测试数据,获得他们每一个对应的类,然后对这个类进行统计获得出现频率最高的类,这个类即为分组结果。
KNN算法应用一:约会网站配对
#-------------------------knn算法实例-----------------------------------
#-------------------------约会网站配对-----------------------------------
import numpy
import matplotlib.pyplot as plt
#---------------1 将text文本数据转化为分类器可以接受的格式---------------
def file2matrix(filename):
#打开文件
fr=open(filename)
#读取文件每一行到array0Lines列表
#read():读取整个文件,通常将文件内容放到一个字符串中
#readline():每次读取文件一行,当没有足够内存一次读取整个文件内容时,使用该方法
#readlines():读取文件的每一行,组成一个字符串列表,内存足够时使用
array0Lines=fr.readlines()
#获取字符串列表行数行数
numberOfLines=len(array0Lines)
#创建一个numberOfLines行,3列的特征矩阵
returnMat = numpy.zeros((numberOfLines, 3))
#list存储类标签
classLabelVector=[]
index=0
for line in array0Lines:
#去掉字符串头尾的空格,类似于Java的trim()
line=line.strip()
#将整行元素按照tab分割成一个元素列表
listFromLine=line.split('\t')
#将listFromLine的前三个元素依次存入returnmat的index行的三列
returnMat[index,:]=listFromLine[0:3]
#python可以使用负索引-1表示列表的最后一列元素,从而将标签存入标签向量中
#使用append函数每次循环在list尾部添加一个标签值
#需要注明Int类型,否则就以字符串处理了
classLabelVector.append(int(listFromLine[-1]))
index+=1
# 返回的是测试数据矩阵,和一个标签列表
return returnMat,classLabelVector
#画散点图
def plot():
#新建一个表格
fig = plt.figure()
#将画布分成1行1列,图像画在从左到右从上到下的第1块(三个1的含义,就是只有一块画布)
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
#获取数据
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
#以数据矩阵第二列,第三列作图,不同的大小及颜色(后两个参数是用来设置这个的嘛?不明白啊!)
ax1.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*numpy.array(datingLabels),15.0*numpy.array(datingLabels))
ax2.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*numpy.array(datingLabels),15.0*numpy.array(datingLabels))
plt.show()
#----------------2 准备数据:归一化----------------------------------------------
#计算欧式距离时,如果某一特征数值相对于其他特征数值较大,那么该特征对于结果影响要
#远大于其他特征,然后假设特征都是同等重要,即等权重的,那么可能某一特征对于结果存
#在严重影响
#都是对矩阵进行操作
def autoNorm(dataSet):
#找出每一列的最小值
minVals=dataSet.min(0)# 一行三列
#找出每一列的最大值
maxVals=dataSet.max(0)# 一行三列
ranges=maxVals-minVals# 一行三列
#创建与dataSet等大小的归一化矩阵
#shape()获取矩阵的大小,创建一个一样大小的矩阵
normDataSet=numpy.zeros(numpy.shape(dataSet))
#获取dataSet第一维度的大小
m=dataSet.shape[0]
#将dataSet的每一行的对应列减去minVals中对应列的最小值
#tile进行矩阵扩充
normDataSet=dataSet-numpy.tile(minVals,(m,1))
#归一化,公式newValue=(value-minvalue)/(maxVal-minVal)
normDataSet=normDataSet/numpy.tile(ranges,(m,1))
return normDataSet,ranges,minVals
#-------------------------2.1 KNN算法----------------------------------------------
def classify0(inX, dataSet, labels, k):
# dataset是一个数组,shape函数是用于建立矩阵,shape[0]代表数组的行数
dataSetSize = dataSet.shape[0]
# tile(A,reps)共有2个参数,A指待输入数组,reps则决定A重复的次数。
# 整个函数用于重复数组A来构建新的数组。
# reps=(dataSetSize, 1)代表行方向重复dataSetSize次,列方向重复1次
# 输入向量与输入样本集做差,是矩阵做差
diffMat = numpy.tile(inX, (dataSetSize, 1)) - dataSet
# 平方
sqDiffMat = diffMat**2
# 当加入axis = 1,以后就是将一个矩阵的每一行向量相加
sqDistances = sqDiffMat.sum(axis=1)
# 开方得到距离
distances = sqDistances**0.5
# argsort()是将相应数组按照从小到大顺序排列
# 但是返回的不是排序之后的结果(值),而是这些值在原理数组中的位置(下标)
sortedDistIndicies = distances.argsort()
# 将classCount字典分解为元组列表
classCount = {}
for i in range (k):
# 取排序后对应的labels
voteIlabel = labels[sortedDistIndicies[i]]
# 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
# 每种label出现的次数都记录下来
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
maxCount = 0
for key, value in classCount.items():
if value> maxCount:
maxCount = value
calsses_ = key
# 返回发生频率最高的元素标签
return calsses_
#-------------------------3 测试算法----------------------------------------------
#改变测试样本占比hoRatio,k值等都会对最后的错误率产生影响
def datingClassTest(hoRatio,k):
#从文本中提取得到数据特征,及对应的标签
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
#对数据特征进行归一化
normMat,ranges,minVals=autoNorm(datingDataMat)
#得到第一维度的大小,即行数
m=normMat.shape[0]
#测试样本数量
numTestVecs=int(hoRatio*m)
#错误数初始化
errorCount=0.0
for i in range(numTestVecs):
#利用分类函数classify0获取测试样本数据分类结果
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],k)
#打印预测结果和实际标签
print("the classifier came back with: %d, the real answer is: %d"%(classifierResult,datingLabels[i]))
#如果预测输出不等于实际标签,错误数增加1.0
if(classifierResult != datingLabels[i]):errorCount+=1.0
#打印最后的误差率
print("the total error rate is: %f" %(errorCount/float(numTestVecs)))
#-------------------------4 构建可手动输入系统------------------------------------
#用户输入相关数据,进行预测
def classifyPerson():
#定义预测结果
resultList=['not at all','in small does','in large does']
#在python3.x中,已经删除raw_input(),取而代之的是input()
percentTats=float(input(\
"percentage of time spent playing video games?"))
ffMiles=float(input("frequent filer miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minValues=autoNorm(datingDataMat)
#将输入的数值放在数组中
inArr=numpy.array([ffMiles,percentTats,iceCream])
classifierResult=numpy.classify0((inArr-minValues)/ranges,normMat,datingLabels,3)
print("you will probably like this person:",resultList[classifierResult-1])
#测试结果表明,测试样本占比越高,错误率越大(因为学习的样本少了),但不是单调上升的
#k值的变化会对结果影响,但是K达到一定值之后就对结果没什么影响了,反而增加了计算量
def main():
plot()
datingClassTest(0.5,20)#改变测试样本占比hoRatio,k值等都会对最后的错误率产生影响
main()