我们之前一直是获得url返回的数据并进行分析,取得其中需要的内容的
但是有些界面中的数据并不是在一开始就加载完成的,而是通过动态的加载出来的
假如我们有一天头脑发热,要爬取下面这个网址中的内容
https://www.jd.com/error2.aspx
不要问我为什么爬这个,只是举个栗子
然后按照以往的套路开始爬。。。想获取到这个名字
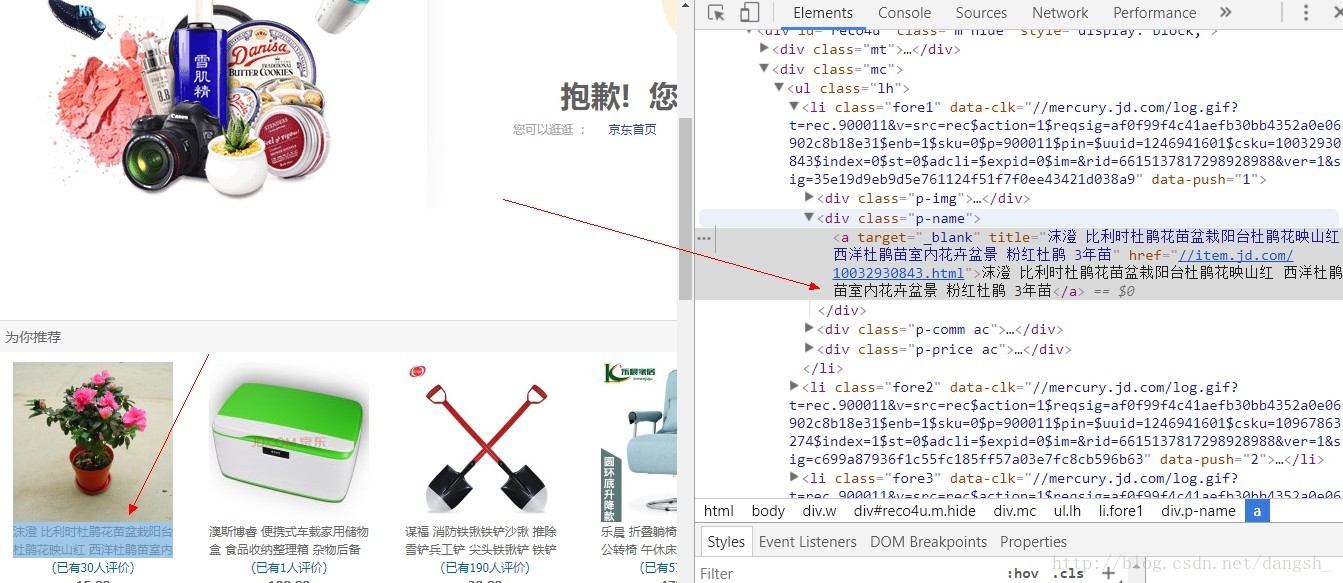
然后以为so easy ,开始自信满满写代码
分析界面的结构
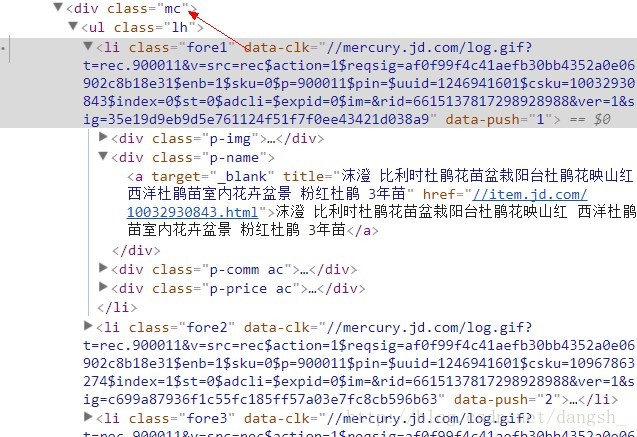
瞬间写出下面的代码
# -*- coding: utf-8 -*-
import scrapy
class MidSpider(scrapy.Spider):
name = 'mid'
start_urls = ['http:////wap.jd.com/category/all.html/']
def parse(self , response):
for item in response.css(".mc"):
title = item.css(".p-name a::text").extract()
print(title)
然后开始跑爬虫

说好的数据去哪了。。。
然后怀疑人生几秒
是不是选择器出问题了,于是开始改,疯狂改。。。。
打印一下response.body.decode()
print(response.body.decode())打印出来的response.body里居然没有自己需要的信息
发现
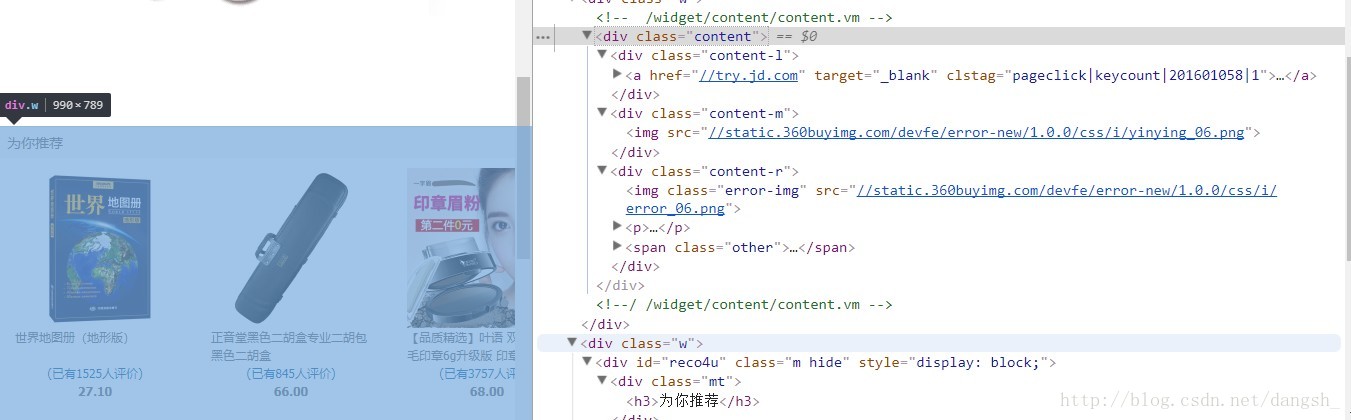
。。。
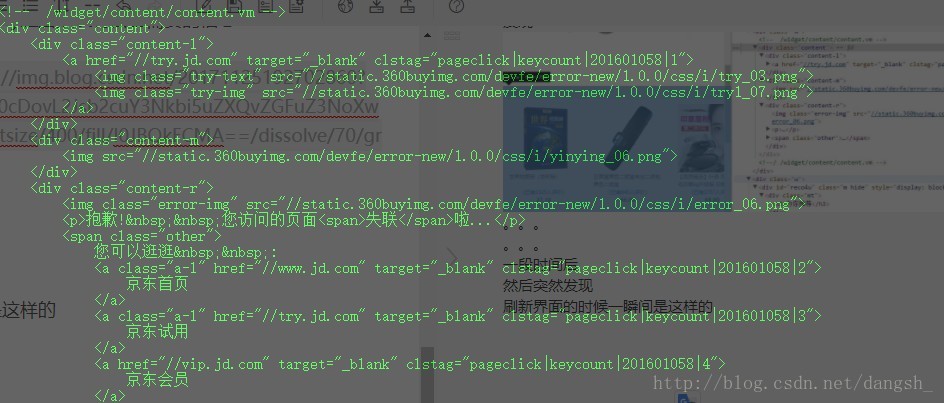
。。。
居然是不一样的
也就是说class=”w” 的div标签及其内容是在我们请求数据的时候是没有的
。。
然后突然发现
刷新界面的时候一瞬间是这样的
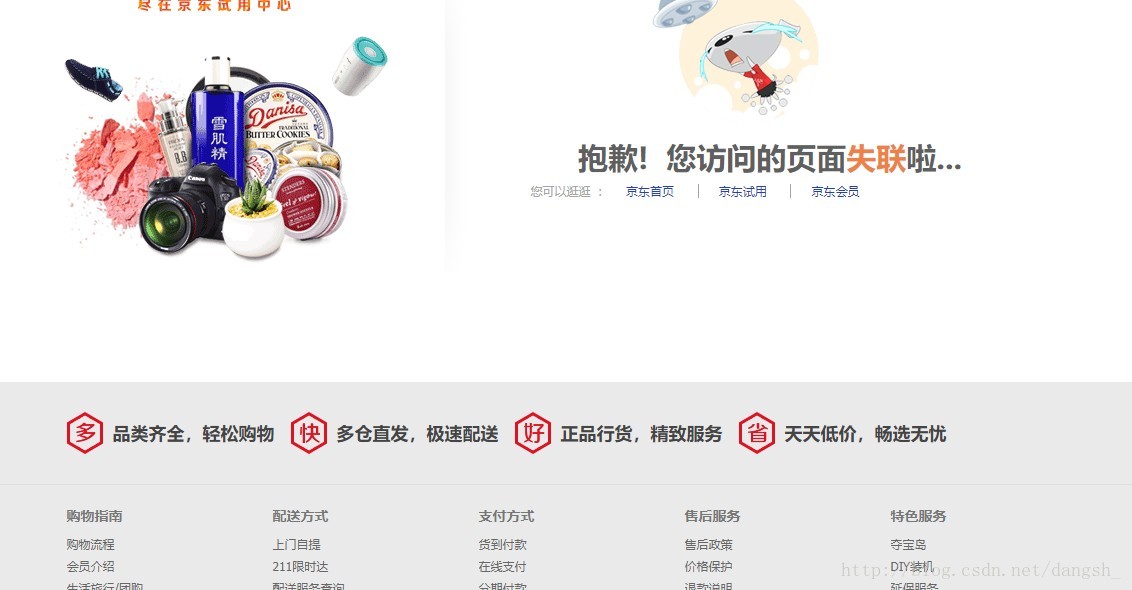
果然和我想的一样
没有办法得到数据了,GG 本篇博客结束
。
。
。
。
。
。
。
当然不是这样了
我们可以使用middleware(中间件)来预加载一下这个界面,获得完整的界面html之后,再取它里面的内容
我们在spiders的同级目录下建一个文件夹,叫做middle
然后在它的下面建一个py文件 myMiddleware.py
在myMiddleware.py文件夹中加入以下内容
from selenium import webdriver
from scrapy.http import HtmlResponse
import time
class JavaScriptMiddleware(object):
def process_request(self, request, spider):
if spider.name == "mid":
driver = webdriver.Chrome("D:\\浏览器代理\chromedriver.exe") #指定使用的浏览器
driver.get(request.url)
time.sleep(1)
js = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js) #可执行js,模仿用户操作。此处为将页面拉至最底端。
time.sleep(3)
body = driver.page_source
print ("访问"+request.url)
return HtmlResponse(driver.current_url, body=body, encoding='utf-8', request=request)
else:
return Noneselenium 是一个 自动化测试的工具,如果你没有这个模块的话可以pip安装一下
pip install selenium解释一下上面的代码
定义一个JavaScriptMiddleware的类,
定义一个process_request(self, request, spider):的方法
当spider的名字是mid的时候执行。
webdriver是什么呢?
是selenium为我们提供的自动化测试工具,
ctrl+左键查看一下
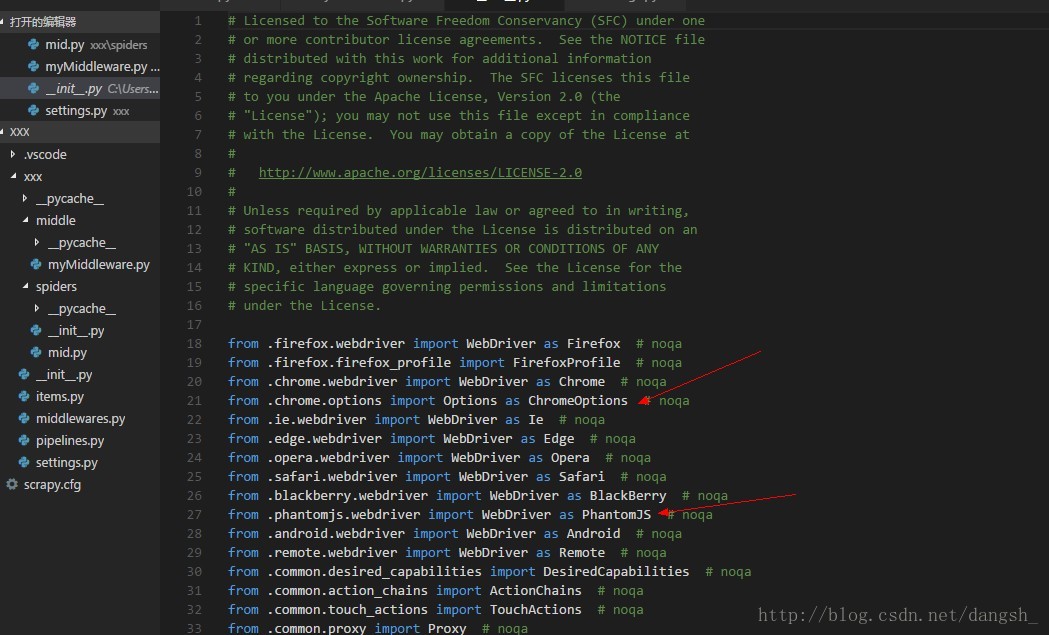
可以使用很多浏览器进行测试
在这里我们使用两个:
Chrome 和 PhantomJS
这里是我放在网盘里的链接,需要的话可以下载一下
链接:http://pan.baidu.com/s/1nv1fYBZ 密码:jokg
下载之后放进一个文件夹待用。
将路径配置一下
定义一个driver 来接收webdriver.Chrome(“D:\浏览器代理\chromedriver.exe”)。
这里需要注意的是D:\\ 是有两个“\”的,
js = "var q=document.documentElement.scrollTop=10000"这段js代码是模拟浏览界面,将界面活动到距离顶部10000的位置,也就是滑动到界面最下方
剩下的代码应该没什么问题了
想要使用我们自定义的middleware需要在settings.py文件内配置一下,在settings.py文件下配置
DOWNLOADER_MIDDLEWARES = {
'xxx.middle.myMiddleware.JavaScriptMiddleware':100 ,
}
调用一下我们自定义的middlewares
然后运行代码会弹出一个界面
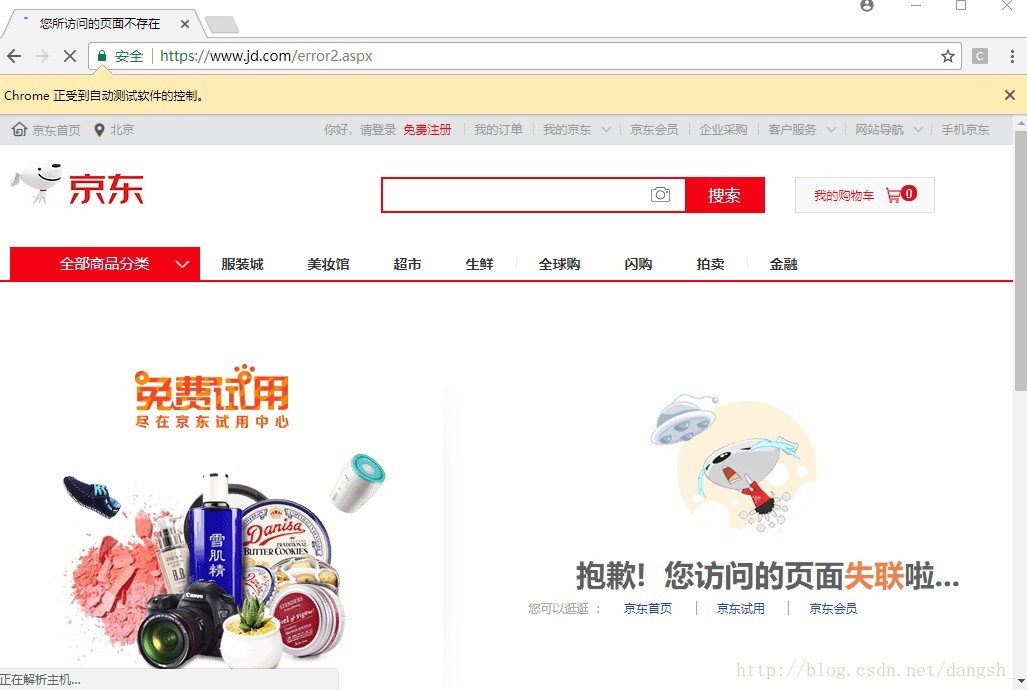
自动测试,几秒后自动关闭,
命令行界面中出现结果
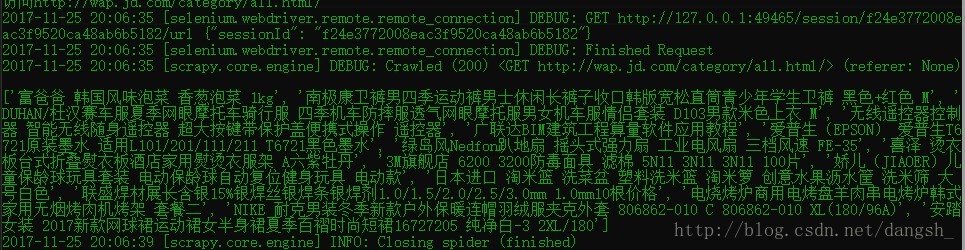
成功~
如果不想弹出这个界面的或,可以使用没有界面的PhantomJS作为测试,只需要修改一行代码
driver = webdriver.PhantomJS("D:\\浏览器代理\phantomjs.exe") #指定使用的浏览器再次运行,等待运行结束后,同样出现结果~
这就是PhantomJS作为middlewares的应用~
项目代码和chromedriver PhantomJS我都放到了github上
https://github.com/dangsh/hive/tree/master/scrapySpider/xxx
https://github.com/dangsh/hive/tree/master/scrapySpider/%E6%B5%8F%E8%A7%88%E5%99%A8%E4%BB%A3%E7%90%86
也可以在这个在git上下载