之前一直没有使用到Rule , Link Extractors,最近在读scrapy-redis给的example的时候遇到了,才发现自己之前都没有用过。Rule , Link Extractors多用于全站的爬取,学习一下。
Rule
Rule是在定义抽取链接的规则
class scrapy.contrib.spiders.
Rule
(link_extractor,callback=None,cb_kwargs=None,follow=None,process_links=None,process_request=None)- link_extractor 是一个Link Extractor对象。 是从response中提取链接的方式。在下面详细解释
- follow是一个布尔值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback 为None,follow 默认设置为True,否则默认为False。
当follow为True时,爬虫会从获取的response中取出符合规则的url,再次进行爬取,如果这次爬取的response中还存在符合规则的url,则再次爬取,无限循环,直到不存在符合规则的url。
当follow为False是,爬虫只从start_urls 的response中取出符合规则的url,并请求。
具体使用可以看下面的例子
———————————-分割线———————————-
Link Extractors
官方解释是:
Link Extractors 是用于从网页(scrapy.http.Response )中抽取会被follow的链接的对象。简单的理解就是:
用于从网页返回的response里抽取url,用以进行之后的操作。我们用豆瓣top250写一个小例子
from scrapy.spiders.crawl import Rule, CrawlSpider
from scrapy.linkextractors import LinkExtractor
class DoubanSpider(CrawlSpider):
name = "test"
allowed_domains = ["book.douban.com"]
start_urls = ['https://book.douban.com/top250']
rules = (
Rule(LinkExtractor(allow=('subject/\d+/$',)),callback='parse_items'),
)
def parse_items(self, response):
pass
需要注意的点:
- import
- DoubanSpider继承的是CrawlSpider,并不是之前的scrapy.Spider
- Rule中使用的就是 Link Extractors 了
运行爬虫,效果如下:
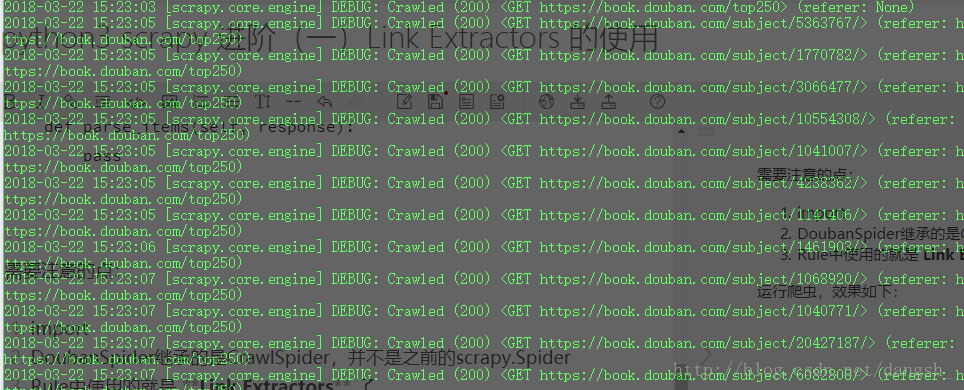
可见爬取了很多url,这些url是怎么获得的呢?
就是Link Extractors 提取出来的。
我们在上面的rule中定义了Link Extractors,LinkExtractors接收的一个参数是allow=(‘subject/\d+/$’,) ,是一个正则表达式。
运行流程是
1.scrapy 请求 start_urls , 获取到response
2.使用LinkExtractors中allow的内容去匹配response,获取到url
3.请求这个url , response交给,callback指向的方法处理Scrapy默认提供2种可用的 Link Extractor,可以通过实现一个简单的接口创建自己定制的Link Extractor来满足需求。
如果不自定义的话,默认的link extractor 是 LinkExtractor ,其实就是 LxmlLinkExtractor:
LinkExtractor的参数有:
class scrapy.contrib.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), tags=('a', 'area'), attrs=('href', ), canonicalize=True, unique=True, process_value=None)- allow
一个正则表达式(或一个正则表达式的列表),即要提取的url。如果没有(或空),它将匹配所有链接。 - deny
一个正则表达式(或一个正则表达式的列表),即不需要提取的url。它优先于允许参数。如果没有(或空),它不会排除任何链接。 - allow_domains
允许的域名 - deny_domains
不允许的域名 - deny_extensions
不允许的扩展名(参考http://www.xuebuyuan.com/296698.html) - restrict_xpaths
是XPath(或XPath的列表),该XPath定义了应该从何处提取链接的响应区域。如果给定,只有那些XPath选择的文本将被扫描到链接。 - tags
在提取链接时要考虑的标签或标签列表
默认为(‘a’, ‘area’). - attrs
在查找提取链接时应该考虑的属性或属性列表(仅针对标记参数中指定的标记)。默认为(“href”) - canonicalize
每个url(使用scrapy.utils.url.canonicalize_url)提取规范化。默认值为True。 - unique
是否应将重复过滤应用于提取的链接。 - process_value
它接收来自扫描标签和属性提取每个值, 可以修改该值, 并返回一个新的, 或返回 None
以上参考链接http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/link-extractors.html
以上是follow没有设置(默认为False的情况),在爬取到25个url的时候程序终止了。而如果将follow设置为True,将程序改成如下:
from scrapy.spiders.crawl import Rule, CrawlSpider
from scrapy.linkextractors import LinkExtractor
class DoubanSpider(CrawlSpider):
name = "test"
allowed_domains = ["book.douban.com"]
start_urls = ['https://book.douban.com/top250']
rules = (
Rule(LinkExtractor(allow=('subject/\d+/$',)),callback='parse_items',follow=True),
)
def parse_items(self, response):
pass
再次运行爬虫,发现爬虫(不被反爬的话)会跑很久不停下。因为在页面中有这样的地方:

他们的url也符合规则,就会被不断的爬下来。
项目代码地址:https://github.com/dangsh/hive/tree/master/scrapySpider/ruleTest