以下操作基于Windows平台。
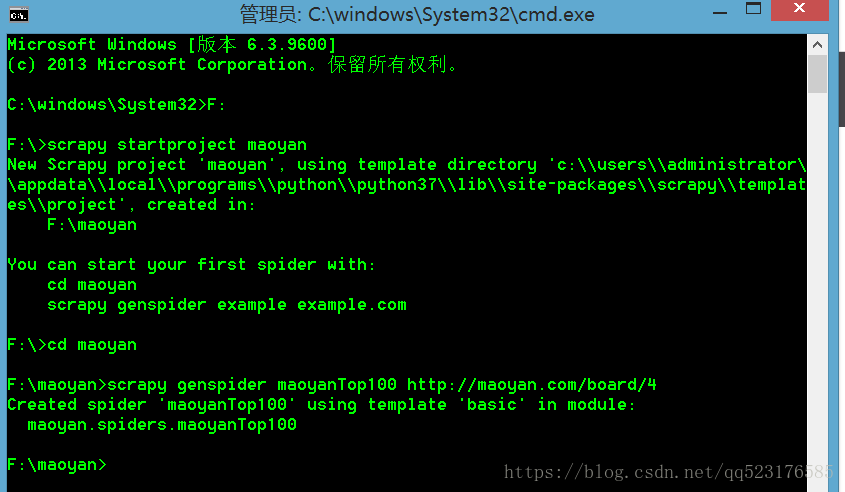
打开CMD命令提示框:
输入 如下命令:
打开项目里的items.py文件,定义如下变量,用于存储。
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
movie = scrapy.Field()
actor = scrapy.Field()
release = scrapy.Field()
score = scrapy.Field()然后打开项目里的spiders文件夹内的maoyanTop100.py文件。
# -*- coding: utf-8 -*-
import time
import scrapy
from scrapy.http import Request
from maoyan.items import MaoyanItem
class Maoyantop100Spider(scrapy.Spider):
name = 'maoyanTop100'
#allowed_domains = ['maoyan.com/board/4']
#start_urls = ['http://maoyan.com/board/4']
def start_requests(self):
for offset in range(0,100,10):
self.url = 'http://maoyan.com/board/4?offset={}'.format(offset)
yield Request(self.url,callback = self.parse)
time.sleep(1)
def parse(self, response):
context = response.css('dd') #分析得知所有的电影item均在该标签内
for info in context:
item = MaoyanItem()
item['movie'] = info.css('p.name a::text').extract_first().strip()
item['actor'] = info.css('.star::text').extract_first().strip()
item['release'] = info.css('.releasetime::text').extract_first().strip()
score = info.css('i.integer::text').extract_first().strip()
score += info.css('i.fraction::text').extract_first().strip()
item['score'] = score
yield item打开settings.py文件,加入如下两行代码:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
FEED_EXPORT_ENCODING = 'gbk'然后在命令提示符输入:
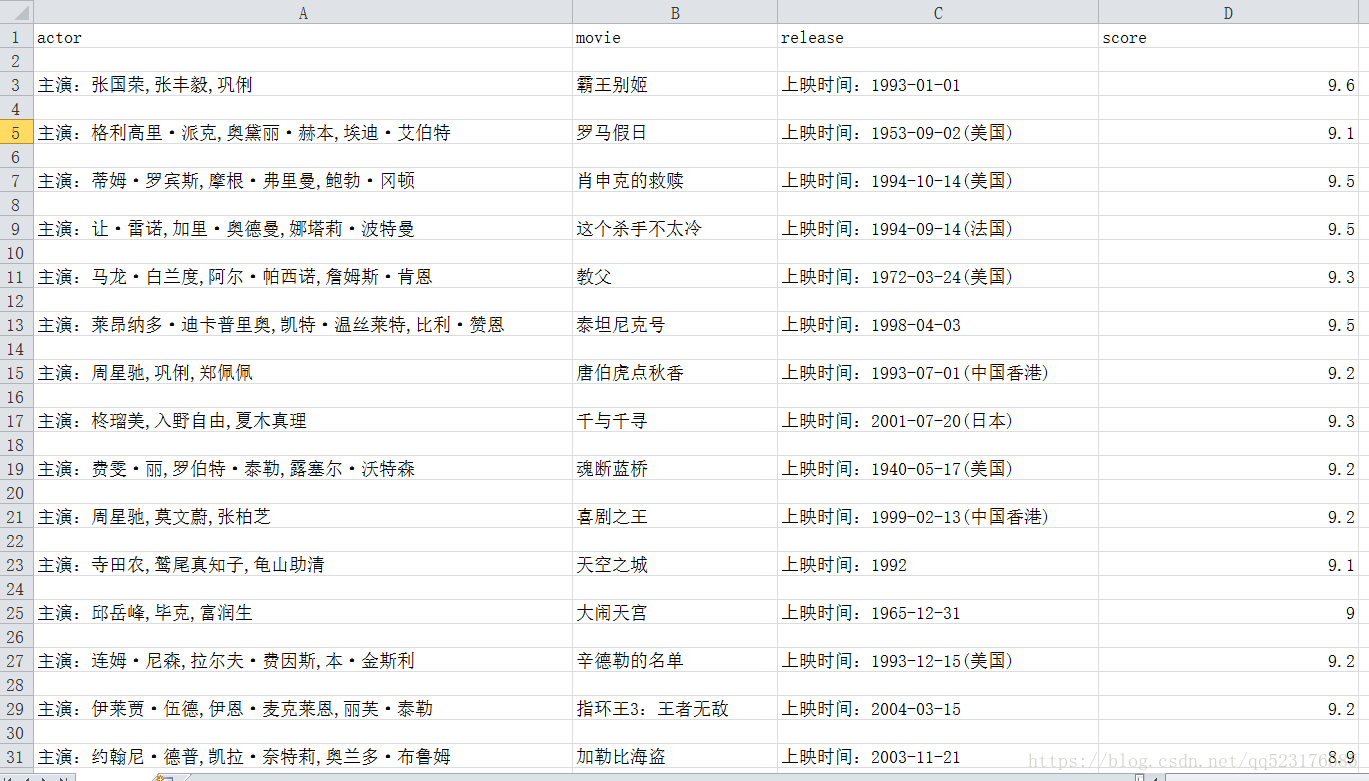
scrapy crawl maoyanTop100 -o maoyan.csv爬取结束后会生成一个csv文件,效果图如下: