一、Scrapy安装
1. 通过pycharm安装
依次打开pycharm->setting->Project:python->Poject Interpreter,可以看到安装的所有第三方包,点击+号添加包。
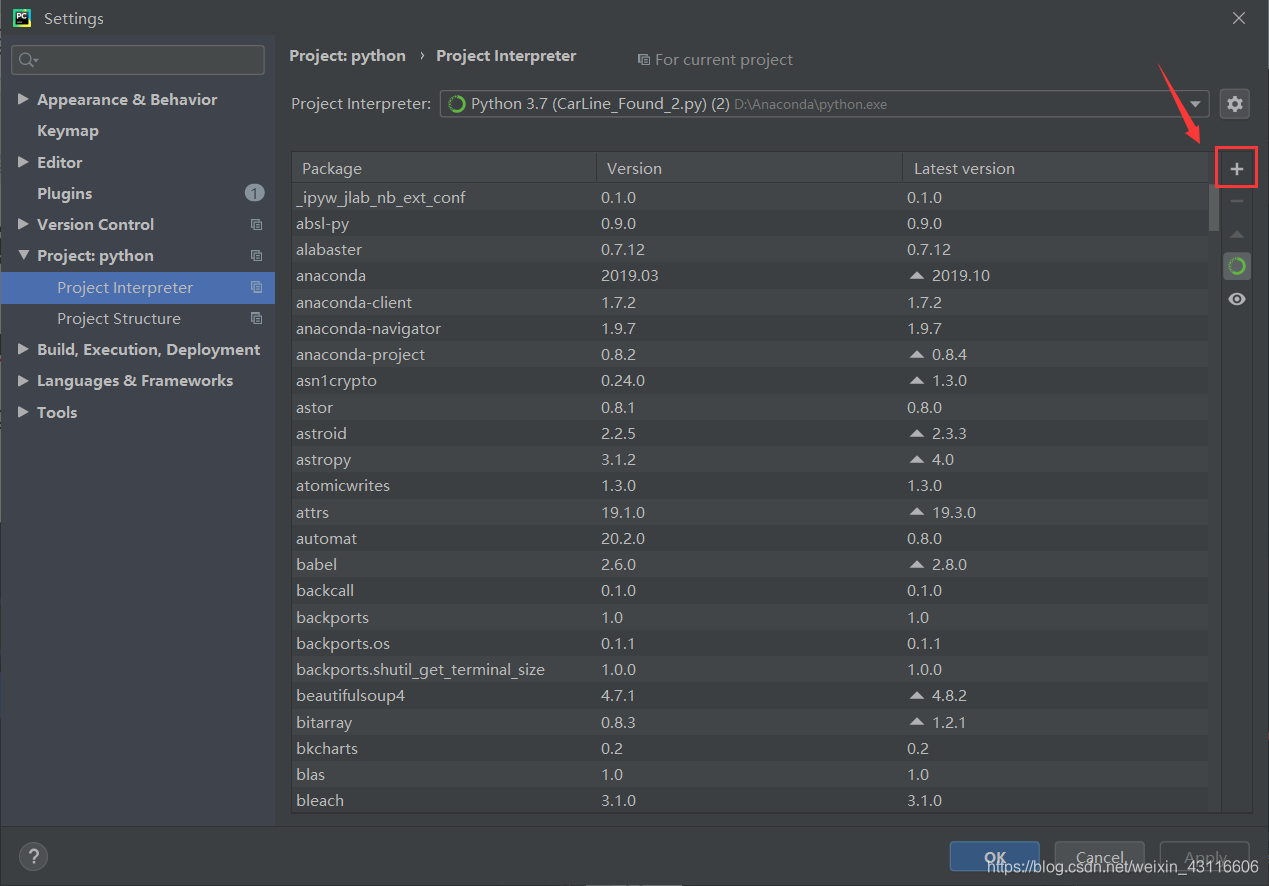
搜索框搜索scrapy,点击左下角安装: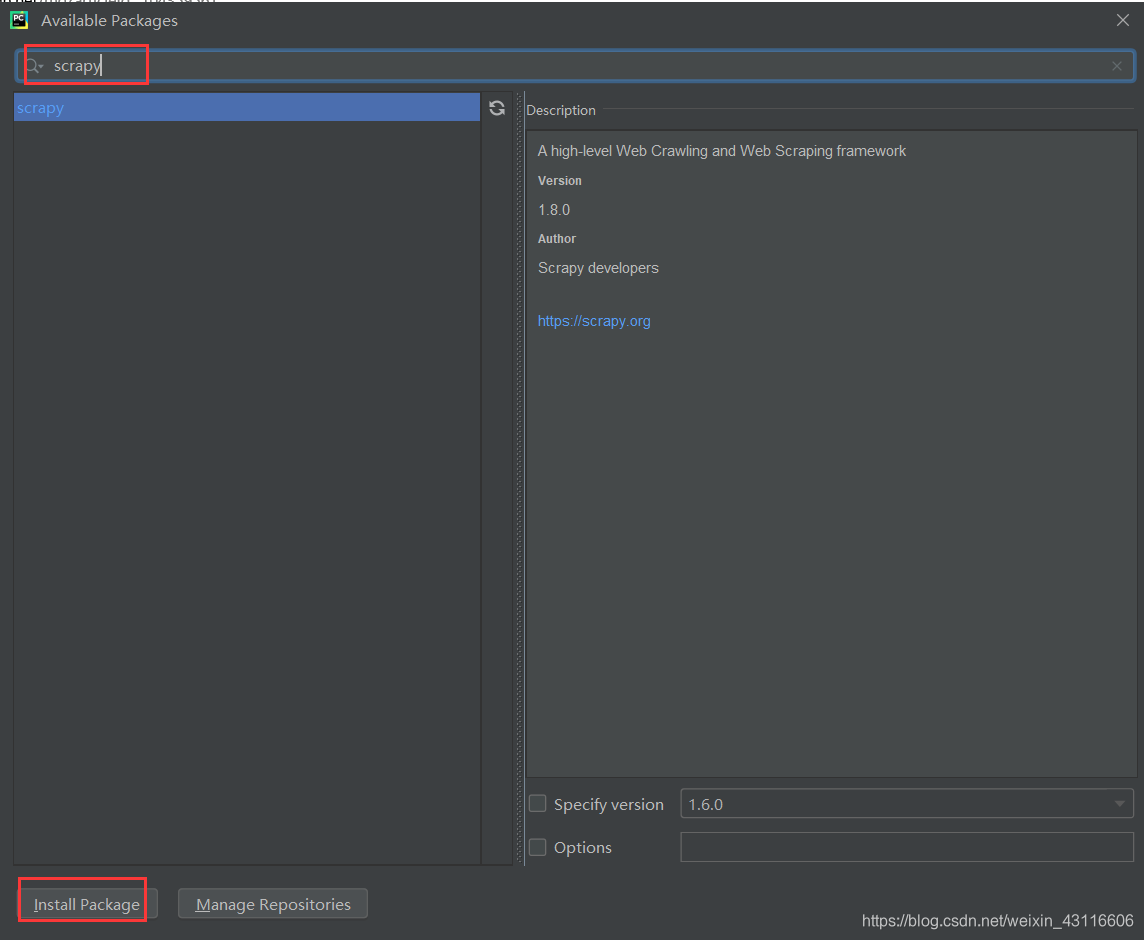
稍等片刻,发现安装失败,再次尝试,依然失败。我们使用pip安装!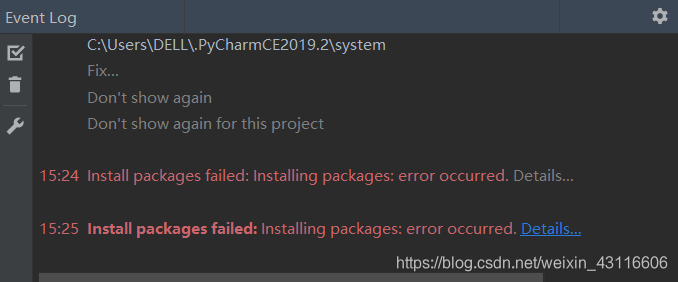
2. pip命令行安装
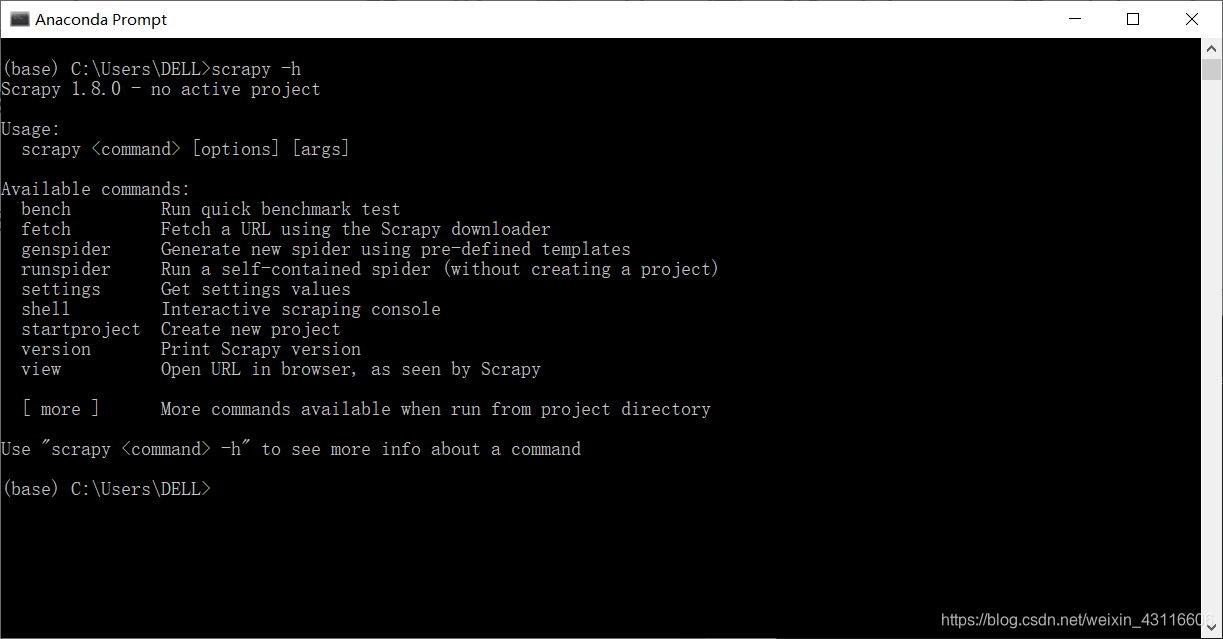
win+R打开命令行窗口,输入pip install scrapy即可。安装成功以后可以键入scrapy -h查看安装信息。
二、Scrapy基本使用
1.Scrapy工程创建
通过cd /d 文件夹路径到达自己想要保存工程的文件夹,然后键入命令scrapy startproject ScrapyDemo创建一个名为ScrapyDemo的爬虫工程。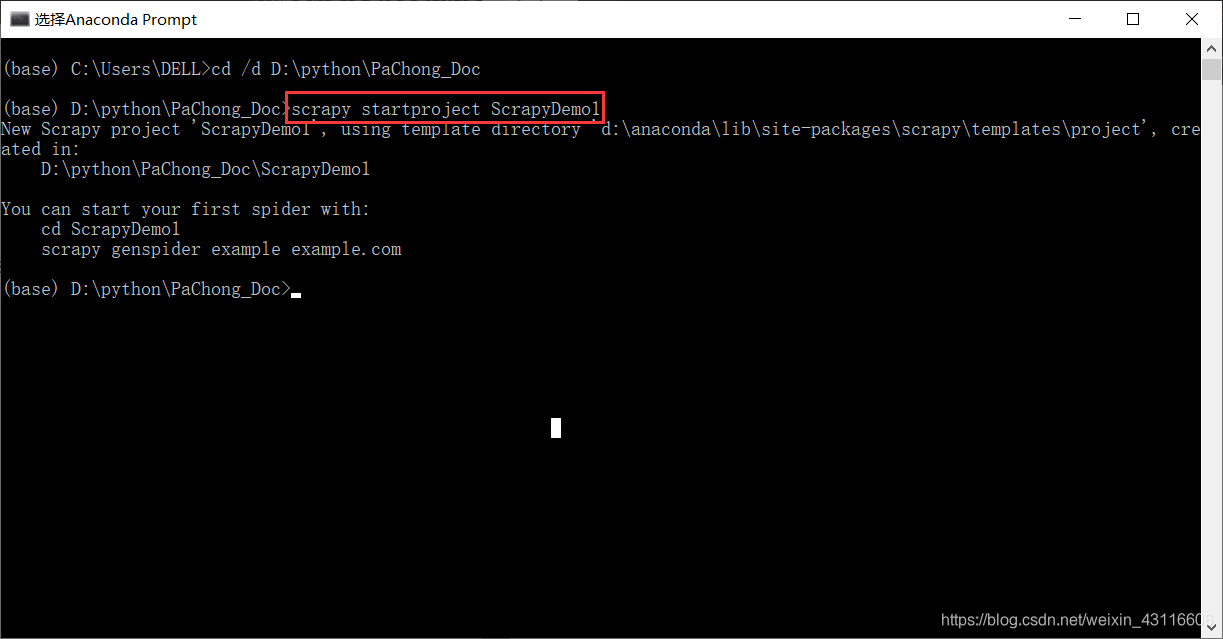
然后打开保存工程的文件夹,就可以看到创建好的工程文件。
2. 生成一个爬虫
在之前创建爬虫工程的文件目录下键入scrapy命令:scrapy genspider demo1 www.baidu.com,就生成了一个名为demo1.py的爬虫文件。
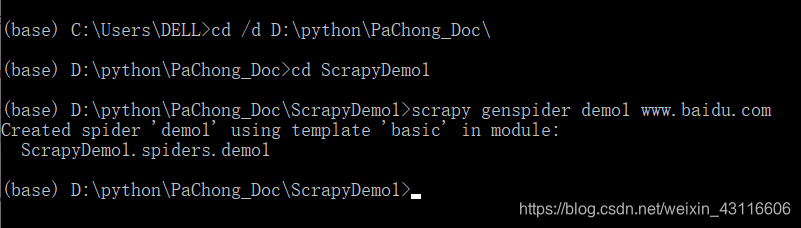
打开demo1.py,可以看到生成了一个继承自scrapy.Spider的名为Demo1Spider类,它包括名称、url,以及一个parse的方法。parse()用于处理响应,解析内容形成字典,发现新的url爬取请求。
# -*- coding: utf-8 -*-
import scrapy
class Demo1Spider(scrapy.Spider):
name = 'demo1'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
pass我们也可以直接在文件目录下创建一个py文件,然后敲入代码,与上述命令行生成爬虫的方式等价。接下来就通过完善demo1.py来完成爬取。
3. 修改爬虫文件demo1.py
# -*- coding: utf-8 -*-
import scrapy
class Demo1Spider(scrapy.Spider):
name = 'demo1'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
pass4. 运行爬虫,获取网页
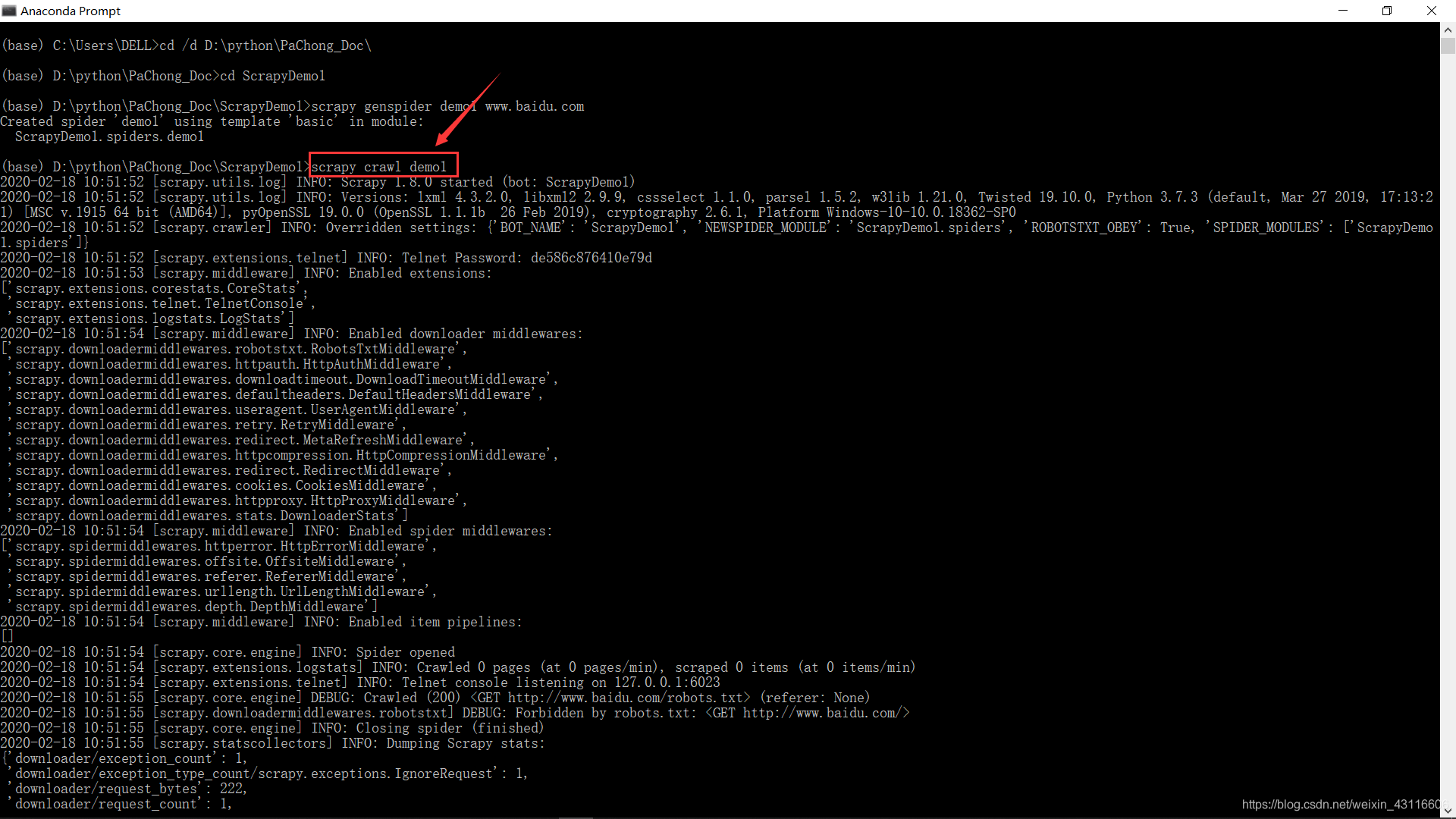
打开命令行,执行scrapy crawl demo1命令爬取网页。下面的捕获信息表示爬取成功。