软件环境:Pycharm 2018 python:3.6
1.首先我们需要安装scrapy模块,pip install scrapy ,不过这种方式经常会遇到许多未知的bug
建议参考这篇博客:https://blog.csdn.net/liuweiyuxiang/article/details/68929999
2.新建scrapy项目,cmd 进入工作区间目录,比如我们新建项目名称为scrapydemo的项目:
scrapy startproject scrapydemo
3.使用Pycharm打开新建的scrapy项目,项目目录如下:
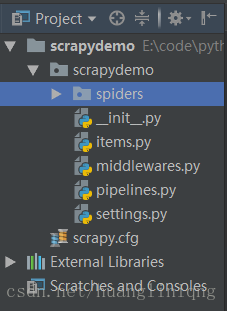
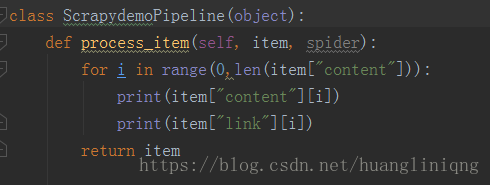
pipelines.py主要对爬取得结果进行处理,比如我们可以再次将爬取结果插入数据库
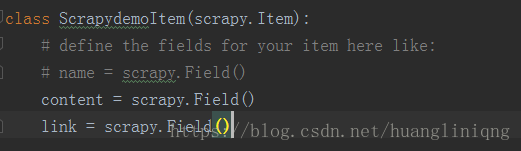
items.py在这里我们可以理解为java中的实体类,定义我们要抓取的字段等信息
setting.py中主要是一些配置信息,ITEM_PIPELINES = {
'scrapydemo.pipelines.ScrapydemoPipeline': 300,
}我们需要将这个修改成自己的pipelline
4.在spiders中新建一个scrapy的py文件,可以手动新建但需要自己写代码,我们使用命令:
scrapy genspider --t basic baidu baidu.com

在parse函数中进行爬虫部分的代码,将爬取结果赋值给item中对应别的字段,使用yield 返回item
5.在cmd命令行使用scrapy crawl 名字(不是项目名字是 name)
