版权声明:转载请注明出处 https://blog.csdn.net/zhouchen1998/article/details/89046700
逻辑回归
- 简介
- 在一元回归和多元回归模型中,处理的因变量都是数值型区间变量,建立的模型描述的是因变量的期望与自变量之间的线性关系。然而,在实际的问题分析时,所研究的变量往往不全是区间变量而是顺序变量或者属性变量,如二项分布的问题。
- 例如,在医疗诊断中,可以通过分析病人的年龄、性别、体质指数、平均血压、疾病指数等指标,判断这个人是否有糖尿病,假设y=0表示未患病,y=1表示患病,这里的因变量就是一个;两点(0或1)的分布变量,它就不能用之前回归模型中因变量连续的值来预测这种情况下因变量y的值(0或1)。
- 总之,线性回归模型通常处理因变量是连续变量的问题,如果因变量是定性变量,线性回归不再适用,需要采用逻辑回归模型解决。逻辑回归(LR)是用于处理因变量为分类变量的回归问题,常见的是二分类或者二项分布问题,也可以处理多分类问题,逻辑回归实际上是一种分类方法。
- 原理
- 二分类问题的概率与自变量之间的关系图形往往是一个S形曲线,常采用Sigmoid函数实现,其函数定义如下: 。
- 对于0-1型变量,y=1的概率分布公式定义如下: ,对于y=0概率为1-p。
- 如果采用线性模型分析,变换公式如下: 。实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,可以引入logit变换,使logit§与自变量之间存在线性相关的关系,逻辑回归模型如下: 。
- 通过推导概率p变换如下式,这与Sigmoid函数相符,也体现了概率p与因变量之间的非线性关系。以0.5为界限,预测p大于0.5时,判断此时y为1,否则为0。
- 。在回归模型建立中,主要需要拟合公式中n个参数θ即可。
- 实战
- 鸢尾花数据集逻辑回归分类
- 代码
-
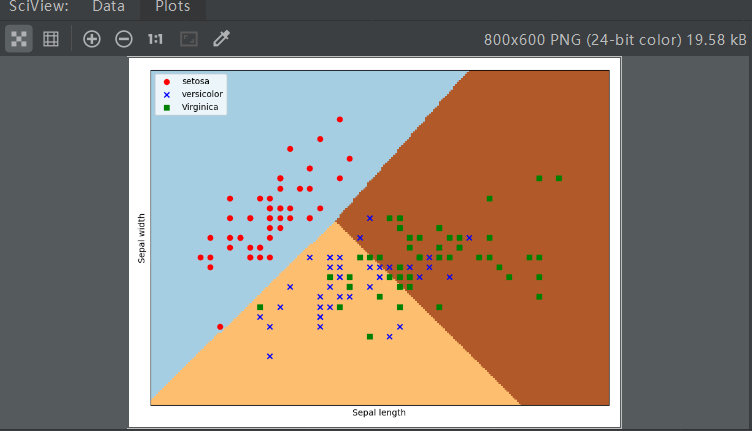
# -*-coding:utf-8-*- # 导入模块 import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression # 读入数据 iris = load_iris() X = iris.data[:, :2] Y = iris.target # 建立模型 lr = LogisticRegression(C=1e5, solver='liblinear') lr.fit(X, Y) # 生成两个网格矩阵 h = .02 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 预测 Z = lr.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # 绘制 plt.figure(1, figsize=(8, 6)) plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa') plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor') plt.scatter(X[100:, 0], X[100:, 1], color='green', marker='s', label='Virginica') plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.xticks(()) plt.yticks(()) plt.legend(loc=2) plt.show()
-
- 运行结果
- 补充说明
- 参考书为《Python3数据分析与机器学习实战》,对部分错误修改
- 具体数据集和代码见我的Github,欢迎Star或者Fork