基于骨骼的人体动作识别由于其易于获取人体骨骼数据而引起了人们的极大兴趣。近年来,在不考虑计算效率的情况下,利用深度前馈神经网络对关节三维坐标进行建模成为一种趋势。在本文中,我们提出一种简单而有效的基于骨架的动作识别神经网络(SGN),我们在网络中明确地引入了关节的高级语义(关节类型和框架索引),以增强特征表示能力。此外,我们还通过两个模块对节点之间的关系进行了层次化的开发。,为同一框架内各节点的相互关系建模的关节级模块,为将同一框架内各节点作为一个整体建模的框架立面模块。为促进这一领域的研究,提出了一个强有力的基线。与一个数量级较小的模型尺寸比大多数以前的工作,SGN实现了最先进的性能在NTU60, NTU120,和SYSU数据集。
人类动作识别具有广泛的应用场景,如人机交互、视频检索等[35,50,1]。近年来,基于skeleton的行为识别[56,7,36,58]受到越来越多的关注。骨架是一种结构良好的数据类型,人体的每个关节通过关节类型、框架索引和三维位置来识别。使用骨架进行动作识别有几个优点。首先,骨骼是人体的高级表现形式,抽象了人体的姿态和动作。从生物学上讲,即使没有外观信息[17],人类也可以通过观察关节的运动来识别动作类别。
其次,性价比高的深度摄像机[61]和位姿估计技术[38,4,43]的发展使得骨骼的获取更加容易。第三,与RGB视频相比,骨架表示对视点和外观的变化具有较好的鲁棒性。第四,由于低维数表示,它在计算上也是高效的。此外,基于骨架的动作识别也是对基于rgb[42]的动作识别的补充。在这项工作中,我们专注于基于骨架的动作识别。
在基于骨架的动作识别中,深度学习被广泛用于建模骨骼序列的时空演化[11,47]。各种网络结构已被开发,如递归神经网络(RNN)。[7, 63, 36, 41, 57, 40],卷积神经网络(CNN)[18,58,30,51],以及图卷积网络(GCN)[54,40,44]。在早期,RNN/LSTM是开发短期和长期时间动态的首选网络。最近,有一种趋势使用前馈(即。用于语音、语言序列建模的卷积神经网络[34, 10, 53, 48]和骨架[18,58,30,51]。大多数基于骨架的方法将关节的坐标组织成2D地图,并将地图调整为适合CNN输入的大小(例如224×224)(例如ResNet50 [12])。它的行/列对应于不同类型的关节/框架索引。在这些方法[18, 58, 30, 51],长期依赖和语义信息有望被深度网络的大接受域捕获。这看起来很残酷,通常会导致模型的高度复杂性。

图2:提出的端到端语义引导神经网络(SGN)的框架。它由联合级模块和框架级模块组成。在DR中,我们通过融合关节的位置和速度信息来学习关节的动力学表示。两种类型的语义,即。分别将关节类型和框架索引纳入关节级模块和框架级模块。在联合级模块中,我们使用了三个GCN层来建模关节的依赖关系。为了建模帧之间的依赖关系,我们使用了两个CNN层。
直观上,语义信息,即。关节类型和帧索引对于动作识别是非常重要的。语义和动力学(例如。(三维坐标)揭示了人体关节的时空结构。我们知道,两个坐标相同但语义不同的关节会传递非常不同的信息。例如,对于头部上方的关节,如果这个关节是手关节,动作很可能是举起手;如果是脚关节,动作可能是踢腿。此外,时间信息对动作识别也很重要。以坐下和站起这两个动作为例,它们只是在画面的出现顺序上有所不同。然而,大多数方法[11,47]忽视了语义信息的重要性,对其探索不足。
为了解决当前方法的上述局限性,我们提出了一种语义引导的神经网络(SGN),它明确地利用语义和动力学来高效地基于骨架的动作识别。图2给出了总体框架。通过对框架序列的联合级和框架级依赖关系的逐次探索,我们构建了一个层次网络。为了更好的建立联合水平的相关模型,除了我们将关节类型的语义(例如,' head '和' hip ')合并到GCN层,从而实现内容自适应图的构造和在每一帧内的关节之间有效的消息传递。为了更好的帧级关联建模,我们将时域帧索引的语义融入到网络中。特别是,我们对同一个框架内的所有节点的特征执行空间MaxPooling (SMP)操作,以获得框架级特征表示结合嵌入的帧索引信息,利用两个卷积神经网络层学习特征表示进行分类。此外,我们制定了一个强大的基准,这是高性能和效率。由于语义信息的有效探索,层次建模和强基线,我们的建议SGN以较少的参数实现了最先进的性能。
我们将我们的三大贡献总结如下:
•我们建议显式地探索联合语义(框架索引和关节类型)用于基于骨架的动作识别。以往的研究忽视了语义的重要性,依赖于高度复杂的深度网络进行动作识别。
•我们提出了一个语义引导的神经网络(SGN),以在联合层次和框架层次上开发空间和时间的相关性。
•我们开发了一个轻量级的强基线,它比以前的大多数方法更强大。我们希望这个强基线能对基于骨架的动作识别研究有所帮助
通过以上技术的贡献,我们获得了一种高性能、计算效率高的基于骨架的动作识别模型。广泛的烧蚀研究证明了模型设计的有效性。在三大基准上对于基于骨架的动作识别,我们提出的模型在模型尺寸比许多算法小一个数量级的情况下,始终能够取得优于许多竞争算法的性能(见图1)。

图1:不同方法在NTU60 (CS设置)上的精度和参数数量的比较所提出的SGN模型在模型尺寸小一个数量级的情况下获得最佳性能。
基于骨架的动作识别近年来受到越来越多的关注。最近使用神经网络的作品[11]大大超过了使用手工特性的传统方法。基于递归神经网络的。递归神经网络,如LSTM[14]和GRU[5],常用于建模骨骼序列的时间动力学将框架中所有关节的三维坐标按一定顺序串联起来,成为一个时隙的输入向量。它们没有明确地告诉网络哪个维度属于哪个关节。其他一些基于神经网络的研究倾向于在神经网络中设计特殊的结构,使其能够感知空间结构信息。Shahroudy et al。将LSTM的细胞分为五个亚细胞,分别对应五个身体部位,即,躯干,两只手臂,两条腿,分别[36]。Liu等人提出了一种时空LSTM模型,利用[27]时空域中节点的上下文相关性,在每个步骤中提供不同类型的节点。在某种程度上,它们区分了不同的关节。
基于卷积神经网络的。近年来,在语音、语言序列建模领域,卷积神经网络在准确性和并行性方面都表现出了优势。基于骨架的动作识别也是如此。这些基于cnn的作品将骨架序列转换为目标大小的骨架图,然后使用流行的网络如ResNet[12]来探索其时空动态。有些作品能改变骨架通过将关节坐标(x,y,z)处理为一个像素的R, G, B通道[6,22],对图像进行量化。Ke等人将骨架序列转换为四个二维数组,通过选择四个参考关节(即参考关节)之间的相对位置来表示。如左/右肩、左/右髋关节)和其他关节[18]。骨架是具有显式高级语义的结构良好的数据。、框架索引和节点类型。但是CNNs的内核/过滤器是翻译不变量[32],不能直接从输入骨架图中感知语义。cnn被认为是通过深度网络的大接受域来感知这些语义的,这并不是很有效。
基于图形卷积网络。图卷积网络[21]在结构化数据处理方面被证明是有效的,它也被用于结构化骨架数据的建模。Yan等人提出了一种时空图卷积网络[54]。它们把每个关节当作图的一个节点。edge denot的存在联合关系是人类基于先验知识预先定义的。为了增强预定义的图,Tang等人定义了物理上不连通和连接的关节对的边,以便更好地构造图[44]。提出了一种SR-TSL模型[40],该模型使用datadriven方法来学习人体各部分的图边缘,而不是使用人体定义。双流GCN模型[37]学习了一个基于非本地块的内容自适应图,并使用它在GCN层中传递消息。但是,信息语义并没有用于图的边缘学习和消息传递GCN,这会降低网络的效率。
语义信息的显式探索。语义的显式探索已被开发在其他领域,如机器翻译[45]和图像识别[62]。Ashish等人显式地对令牌在序列中的位置进行编码,以利用机器翻译任务[45]中序列的顺序。Zheng等人将组索引编码为卷积信道表示,以保存组序信息[62]。而基于骨架的动作识别中,尽管关节类型和框架索引语义非常重要,但却被忽略了。在我们的工作中,我们提出显式编码关节类型和帧索引,以保存重要的时空体结构信息。作为探索这种语义的初步尝试,我们希望它能激发社区中更多的调查和探索。
Semantics-Guided神经网络
对于一个骨架序列,我们通过关节的语义(关节类型和框架索引)来识别关节,并通过关节的动力学(位置/三维坐标和速度)来表示关节。没有语义,骨架数据将失去重要的空间和时间结构。然而,以前基于cnn的研究[18,6,58]通常忽略了语义,将它们隐式地隐藏在2D骨架映射中(例如。(行对应不同类型的节点,列对应框架索引)。
我们提出了一种基于骨架的动作识别的语义引导神经网络(SGN),并在图2中展示了整体的端到端框架。它由联合级模块和框架级模块组成。我们将在下面的小节中详细描述该框架。具体来说,对于一个骨架序列,我们将所有的关节表示为一个集合S = {Xk t
t = 1,2,…T;k = 1,2,…, J},其中Xk t为t时刻类型k的关节,t为骨架序列的帧数,J为人体在框架内的关节总数。对于给定的k型关节在时间t时,可以通过动力学和语义进行识别。动力学与关节的三维位置。语义是指框架索引t和关节类型k。
动态表示
对于给定的关节xkt通过位置pt,k = (xt,k, yt,k, zt,k)来定义它的动力学T∈R3在三维坐标系中,速度vt,k = pt,k−pt−1,k。我们将位置和速度编码/嵌入到相同的高维空间中。, pgt,k, vgt,k,相加融合为:

其中C1为关节表示的维数。以位置的嵌入为例,我们使用两个全连通(FC)层对位置pt,k编码为

其中W1∈RC1×3,W2∈RC1×C1为权重矩阵,b1、b2为偏置向量,素养表示ReLU激活函数[33]。同样,我们得到速度的嵌入为vgt,k。
Joint-level模块
我们设计了一个联合层次的模块来开发在同一框架下各关节的相关性。我们采用图卷积网络(GCN)来探索结构骨架数据的相关性。以往一些基于gcc的方法将节点作为节点,基于先验知识[54]预定义图连接(边)或学习内容自适应图[37]。我们还学习了内容自适应图,但不同的是,我们将联合类型的语义合并到GCN层中,以便更有效地学习。
我们从两个方面充分利用语义来增强GCN层的功能。首先,我们使用关节类型的语义和动力学来学习一个框架内的节点(不同的关节)之间的图形连接。关节类型信息有助于学习合适的相邻矩阵。,以连接权重表示的关节之间的关系)。以脚和手两个源关节和一个目标关节头部为例,直观地看,在脚和手的动力学相同的情况下,脚到头部的连接权重值与手到头部的连接权重值应该是不同的。第二,作为连接信息的一部分,连接类型的语义参与了GCN层中的消息传递过程。
我们用一个热向量jk∈R dj表示第k个关节的类型(也称为类型k),其中第k维是1,其他都是0。类似于Equ中的位置编码。(2),得到第k个关节类型的嵌入为jek∈RC1。给定一个骨架框架的J个关节,我们建立一个图J节点。我们将关节类型k在坐标系t处的关节表示,关节类型的动力学和语义表示为zt,k = [zt,k,jek]∈R2 c₁。则t坐标系的所有关节表示为Zt = (Zt,1;···;zt,J)∈RJ×2 c₁。
与[49,48,37]类似,同一坐标系t中第i个关节到第j个关节的边缘权值由其在嵌入空间中的相似性/亲和力来建模

式中,和表示两个转换函数,每一个都由FC层实现,即。式中,3x = W3x+b3∈RC2和算得(x) = W4x + b4∈RC2。基于(3)计算同一帧内所有关节对的亲和力,得到邻接矩阵对St的每一行进行SoftMax as归一化[45,48],使连接到目标节点的所有边值之和为1。我们用Gt表示归一化邻接矩阵,利用残差图卷积层实现节点间的消息传递为:

其中Wy和Wz是变换矩阵。对不同的时间帧共享权重矩阵。Zt是输出。请注意,可以堆叠多个剩余图卷积层,以使信息在具有相同邻接矩阵Gt的节点之间进一步传递
我们设计了一个框架级的模块来利用框架之间的关联。为了使网络知道帧的顺序,我们引入了帧索引的语义来增强帧的表示能力。我们用单热向量ft∈R df表示帧索引。类似于Equ中的位置编码。(2),我们得到帧索引的嵌入为fet∈RC3。我们用框架索引的语义和学习特征z表示在坐标系t处对应的关节类型k的关节表示t,k = zt,k +场效应晶体管∈RC3,zt,k = Z′t:,(k)。
为了合并框架中所有节点的信息,我们应用一个空间MaxPooling层来跨节点聚合它们。序列的特征维数为
T乘以1乘以C3。两个CNN层被应用。第一层是时间卷积层,用于建模帧之间的依赖关系。利用CNN的第二层,将学习到的特征映射到核大小为的高维空间,增强其表示能力1. 在两个CNN层之后,我们使用一个时间MaxPooling层来聚合所有帧的信息,得到C4维的序列级特征表示。接下来是一个使用Softmax完全连接的层来执行分类。
数据集
数据集(NTU60)该数据集由Kinect摄像头收集,用于56,880个骨骼序列的3D动作识别。它包含60个动作类,由40个不同的主体执行。每个人体骨骼由25个关节三维坐标表示(J = 25)。对于设置[36]的交叉受试者(CS), 40名受试者中有一半用于培训,其余用于测试。对于Cross-View (CV)设置[36],三个摄像机中的两个捕捉到的序列用于训练,另一个摄像机捕捉到的序列用于测试。
在[36]之后,我们随机选择10%的训练序列进行CS和CV设置的验证。RGB+D数据集(NTU120)这个数据集是NTU60的扩展。它是最大的RGB+D数据集3D动作识别与114,480骨架序列。它包含120个动作类,由106个不同的人类主体执行。在交叉受试者(c -受试者)设置中,106名受试者中有一半用于培训,其余用于测试。对于交叉设置(C-Setup)设置,一半设置用于培训,另一半用于测试。三维人机交互数据集(SYSU)[15]。它包含480个骨架序列,由40个不同的主体执行12个动作。每个人的骨骼都有20个关节(J = 20)。我们使用相同的评估方案[15]。在交叉科目设置中,一半的科目用于训练,另一半用于测试。同样的主题设置,每个活动的一半样本用于培训,另一半用于测试。我们使用30倍交叉验证,并显示了每个设置[15]的平均精度。
实现细节
网络设置。来获得动态表示(DR),每个FC层设置为64个神经元(即。, c = 64)。注意,FC层的重量没有共享位置和速度。为了编码关节类型,将两个FC层的神经元数目都设置为64。为了编码帧索引,将两个FC层的神经元数目分别设置为64和256,C3 = 256。对于(3)中的变换函数,将FC层的神经元数量设置为256个,即:C2 = 256。对于联合级模块,我们将三层GCN的神经元数量分别设置为128,256和256。对于fame-level模块,我们将CNN第一层的神经元数设置为256个,沿时间维度设置kernel size为3;将CNN第二层的神经元数设置为512个,设置kernel size为1(即。, C4 = 512)。在每个GCN或CNN层之后,使用批量归一化[16]和ReLU非线性激活函数。
培训。所有实验均在Pytorch平台上进行,使用一张P100 GPU卡。我们使用Adam[20]优化器,初始学习率为0.001。在第六十纪元时,学习率衰减了十倍分别是90世纪和110世纪。训练在120年代结束。我们使用重量衰减为0.0001。NTU60、NTU120和
SYSU数据集分别设置为64、64和16。所有实验都使用标签平滑[13],我们将平滑因子设为0.1。采用交叉熵损失进行分类训练。
数据处理。与[57]相似,基于第一帧进行序列级平移,使其不受初始位置的影响。如果一个框架包含两个人,我们通过使每个框架包含一个人的骨架,将该框架分割成两个框架。在培训期间,据[27],我们将整个骨架序列平均分割为20个片段,并从每个片段中随机选择一帧,得到一个20帧的新序列。在测试期间,类似于[2],我们以类似的方式随机创建5个新序列,并使用平均分数来预测类。
在训练过程中,我们通过在序列层次上随机旋转三维骨架来进行数据论证,以增强对视图变化的鲁棒性。为NTU60 (CS设置),NTU120,和SYSU数据集,我们随机选择三个度(分别在X, Y, Z轴)之间[−17◦,17◦]的一个序列。考虑到NTU60的大视角变化(CV设置),我们在[- 30◦之间随机选择3度,30◦]。
烧蚀研究
4.3.1挖掘语义的有效性
语义包含骨架序列的重要结构信息,这对基于骨架的动作识别至关重要。通过引用我们的框架(参见图2),我们构建了8个神经网络,并对NTU60数据集进行了各种实验。表1显示了这些比较。其中,JT为关节类型语义,FI为框架索引语义,G为图(邻接矩阵)的学习, P表示支持消息传递的图形卷积操作。T-Conv表示时间卷积层,即,帧级模块的第一层CNN。三个GCN层和两个CNN层分别用于联合层(JL)模块和框架层(FL)模块。w和w/o分别表示“with”和“without”。联合开采的有效性。我们研究了四个设计的模型(表1中的第1行到第4行),以验证联合级模块上联合类型的有效性四种模型都不包含时态索引的语义。我们在这里解释一个模型,其他三个模型可以用类似的方式理解。“杰(G w / oJT & P w/o JT) & FL”表示不将关节类型语义用于学习图(G)的方案(即:
G w/o JT),不参与按摩传递(P)的图形卷积操作(即, P w/o JT)。
我们主要有以下三点看法
1)对于骨架序列图的学习,通过引入关节类型语义“JL(G w JT & P w/o)”JT) & FL "优于" JL(G w/o JT & P w/o JT) & FL
CS和CV设置分别为0.6%和0.9%。直观上,如果模型不知道关节的类型,即使它们的语义不同,也无法区分坐标相同的关节。关节型的语义有利于图的边的学习。
2)联合类型信息有利于GCN层中的消息传递。在CS和CV设置上,“JL(G w/o JT & P w JT) & FL”分别比“JL(G w/o JT & P w/o JT) & FL”优越1.7%和1.3%。原因是GCN本身不知道关节的顺序(类型),这使得它很难了解具有高结构信息的骨架数据的特征。例如,即使在信息传递过程中,足关节和腕关节的三维坐标是相同的,但它们提供给目标关节的信息也应该是不同的。引入联合类型信息可以提高GCN的效率。
3)学习图和消息同时传递的联合类型语义(“JL(G w JT & P w JT) & FL”相比“JL(G w/o JT & P w JT) & FL”并没有带来更多的好处。为消息传递= GtZtW in Equ。(4)、向Gt反向传播的梯度也会受到含有关节类型信息的Zt的影响。实际上,即使我们在相似性/亲和学习中没有包含联合类型信息,Gt仍然隐含地知道联合类型信息。利用帧索引的有效性。我们研究了两个模型(表1中的第5行和第6行),以研究通过设置its来降低时间卷积时帧索引对帧级模块(FL)的影响内核大小为1。“JL & FL(w/o T-Conv) w FI”表示使用帧索引语义的模型。这两个模型都包含了联合类型的语义。此外,我们研究了两个模型(第7行和第8行)表1)研究核大小为3的时域卷积对帧指数的影响。“杰和FL (w - conv) w FI”表示使用帧索引语义的模型。这两个模型都包含了联合类型的语义。

表1:在联合级模块(JL)和框架级模块(FL)上开发语义的有效性NTU60数据集的准确性(%)。JT为关节类型,FI为框架指标。
这里我们有两个主要的观察结果。
1)当时域卷积被禁用时(即对于CS和CV设置,“JL & FL(w/o T-Conv) w/o FI”的性能分别比“JL & FL(w/o T-Conv) w/o FI”的性能好1.0%和0.9%。框架索引信息“告诉”网络骨架序列的框架顺序,有利于动作识别。
2)帧索引有助于时间卷积。“杰在CS和CV设置上,& FL (w - conv) w FI”比“JL & FL (w - conv) w/o FI”分别好0.3%和0.4%。帧索引在语义上的好处要小于那些没有时间卷积的模型(filter kernel size为1),主要原因是时间卷积层使得网络通过较大的kernel大小在一定程度上知道骨架序列的帧序。然而,显式地“告诉”网络帧索引的语义进一步提高了性能,而代价可以忽略不计。我们采取“JL”计划作为我们最终的方案,它也被称为“SGN”。
总之,联合类型信息的显式建模有利于学习相邻矩阵和在GCN层中传递的消息。框架索引信息使模型能够有效地利用序列顺序信息。
4.3.2层次模型的有效性
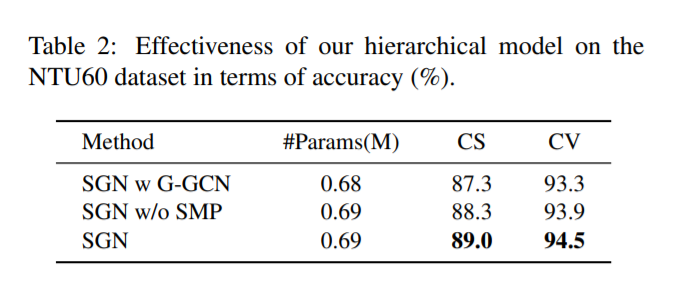
我们对联合级模块和框架级模块中的节点之间的关联进行分层建模。为了证明其有效性,我们将我们的SGN与两种不同的模型进行比较,并在表2中显示结果。“SGN w G-GCN”表示一种非分层模式,其中我们删除空间MaxPooling层(SMP),并使用组合语义(即。以及GCN层中的动力学(位置和速度)。我们不是为每一帧构造一个图,而是用所有帧中的所有节点构造一个全局自适应图,并在所有节点之间进行消息传递。“SGN w/o SMP”表示在我们的方案“SGN”中删除了空间MaxPooling层(SMP)。我们有两点看法。
1)通过对同一框架各节点的关联关系进行建模GCN比建立关联模型更有效所有框架的所有关节。在CS和CV设置上,“SGN w/o SMP”比“SGN w G-GCN”分别高出1.0%和0.6%。学习全局内容自适应图更加复杂和困难。
2)在CS和CV设置上,“SGN”的表现分别比“SGN w/o SMP”高出0.7%和0.6%。通过MaxPooing (SMP)方法将一帧中所有关节的信息聚合,起到提取一帧中具有代表性的判别信息(具有较大的激活值)的作用。此外,空间MaxPooling层减少了后续的计算负担。
强大的基线
以往的工作通常采用重网络来建模低维的骨架序列[40,39,37,58]。我们开发了一些在以前的工作中被证明非常有效的技术,并构建了一个轻量级强基线,它已经取得了与大多数其他最先进的方法相当的性能[40,57,54,8]。我们希望这能为未来基于骨架的动作识别领域的研究提供一个强有力的基础。在本节中,并不是所有的模型都使用语义。
我们首先构建一个基本的基线(“基线”),整个管道类似于图2。有三个不同之处。1)没有使用速度、关节类型、帧索引信息。2)数据增加(DA)(见数据)在培训期间不采用。3)使用AveragePooling而不是像[54,37]中的Maxpooling。表3显示了构建强基线所采用的技术的影响。我们有三点看法。1)数据的增加提高了CV设置的性能显著。通过增加观察到的视图,可以在训练过程中“看到”一些“看不见的”视图。2)两种流网络(同时使用位置和速度)[40]已被证明是有效的,但两个独立网络的参数数翻倍。我们在早期阶段(在输入中)融合了这两种类型的信息,并且只需要少量的附加参数(即输入)就可以显著提高性能。,0.01)。3) MaxPooling比AveragePooling强大得多。原因是MaxPooling就像一个注意力模块,驱动着学习和选择有区别的特征。


图3:空间MaxPooling层对三个操作的响应的可视化,即鼓掌、踢腿和敬礼。将SMP选择的前5个关节用较大的蓝色圆圈绘制出来。
SMP的可视化
空间Maxpooling (SMP)扮演着与注意机制类似的角色。我们用SMP对三种动作的选择关节进行可视化。如图3所示,鼓掌、踢腿和敬礼。响应的尺寸为256,每个尺寸对应一个选定的关节。我们计算SMP选择每个关节的次数。选择的前五个关节用蓝色大圆圈表示,其余的用蓝色小圆圈表示。我们观察到,不同的动作对应着不同的信息关节。踢腿时左脚很重要。行礼时左手是最重要的,拍手时左手和右手都是必不可少的。这与人类的感知是一致的。
胡志明市的复杂性
通过与八种最先进的基于骨架的动作识别方法的比较,我们讨论了SGN的复杂性。如图1所示,VA-RNN[58]的参数个数最少,但精度最差。VA-CNN[58]和2s-AGCN[37]的精度都很好,但是参数数量太大。与基于rn、基于gcn和基于cnn的方法相比,我们所提出的SGN以更少的参数实现了略微更好的性能,这使得SGN在许多计算能力有限的实际应用中具有吸引力。
与现状的比较
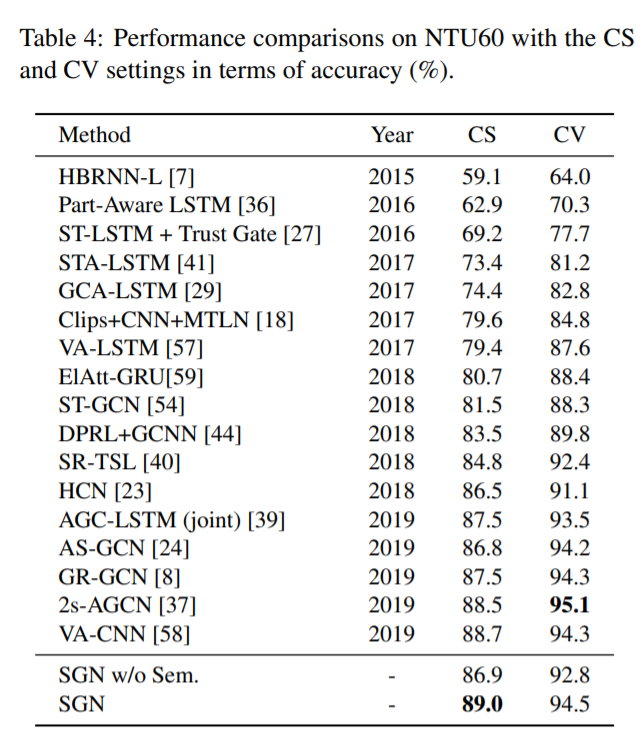
我们分别在表4、表5和表6中的NTU60、NTU 120和SYSU数据集上将所提出的SGN与其他最新方法进行了比较。“胡志明市w / o
扫描电镜。表示不使用语义的强基线。如表4所示,语义的介绍(Sem.)带来了2.1%的性能提升CS和CV设置的准确率分别为1.7%。“elat - gru”[59]和“Clips+CNN+MTLN”[18]分别是基于rnn和基于CNN的两种方法的代表。SGN的表现比他们好准确率分别为8.3%和9.4%,一些方法[54,40]混合了CNN和GCN,或者LSTM和政府通讯联系在一起。在CS设置方面,我们提出的SGN比[54]和[40]的准确率高5.5%和4.2%。与[37]和[58]相比,所提出的SGN实现了具有竞争力的性能,但仅使用了它们的10%的参数,如图1所示。
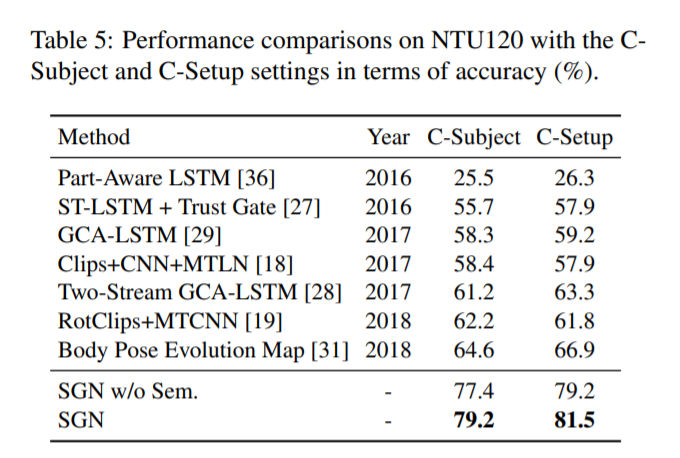
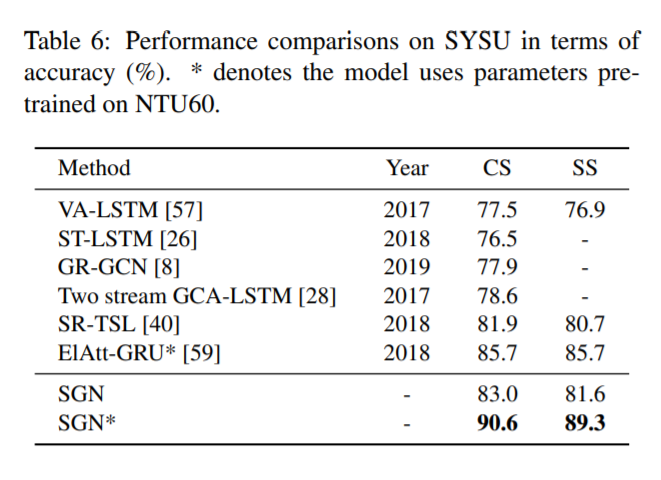
如表5和表6所示,本文提出的SGN在NTU120和SYSU上取得了最好的精度。的NTU120数据集是一个新发布的数据集,我们与[25]报告的结果进行比较。语义学(sem.)为C-Subject和C-Setup设置分别带来1.8%和2.3%的准确率提高

结论
在这项工作中,我们提出了一个简单而有效的端到端语义导向神经网络,用于高性能的基于骨架的人类识别。我们显式地引入了高级语义,即。、节点类型和框架索引,作为网络输入的一部分。为了对节点间的相关性进行建模,我们提出了一个用于获取同一框架内节点间相关性的关节级模块和一个用于将同一框架内的所有节点作为一个整体的框架级模块。语义帮助改进GCN和CNN的功能。此外,我们已经开发了一个强大的基线,这比大多数以前的方法更好。与之前的一些工作相比,我们提出的模型以一个数量级的小尺寸,在三个基准数据集上达到了最新的结果。