版权声明:添加我的微信wlagooble,开启一段不一样的旅程 https://blog.csdn.net/nineship/article/details/86155127
论文:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
期刊:CVPR2017
papar:https://arxiv.org/pdf/1705.07750v1.pdf
相关工作:
相关工作就是下面这个图
文章两个重大贡献:1 提出了kinetics数据集。2 提出了双流3D卷积模型
3D ConvNet
模型细节:是原论文中C3D的变种。8层卷积、5层pooling、2层全连接。与C3D的区别在于这里的卷积和全连接层后面加BN;且在第一个pooling层使用stride=2,这样使得batch_size可以更大。输入是16帧,每帧112*112。
Two-Stream Networks
LSTM缺点:能model高层变化却不能捕捉低层运动(因为在低层,每个帧都是独立地被CNN提取特征),有些低层运动可能是重要的;训练很昂贵
Two-Stream Networks: 将单独的一张RGB图片和一叠计算得到的光流帧分别送入在ImageNet上预训练的ConvNet中,再把两个通道的score取平均
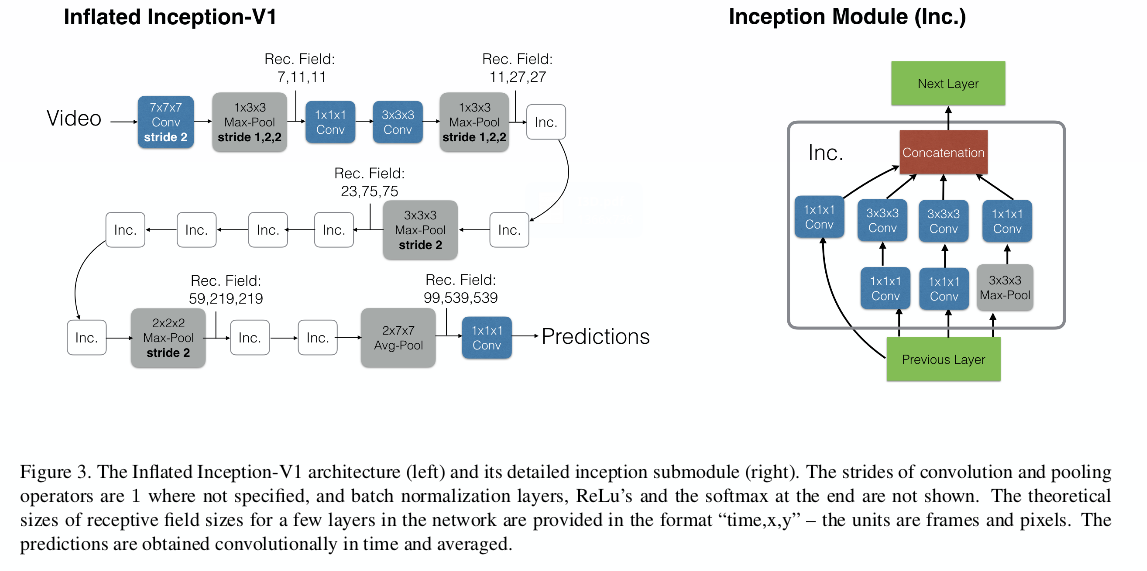
New*: Two-Stream Inflated 3D ConvNets
Implementation Details

模型:
实验结果,可以看到I3D的准确率提高了许多:

参考文章:
https://blog.csdn.net/paranoid_cnn/article/details/77933316