这篇文章开篇就指出,我们的模型是要从人体动作的序列中选取出最informative的那些帧,而丢弃掉用处不大的部分。但是由于对于不同的视频序列,挑出最有代表性的帧的方法是不同的,因此,本文提出用深度增强学习来将帧的选择模拟为一个不断进步的progressive process。
这篇文章处理的问题是skeleton based action recognition,提出的模型的示意图如下:
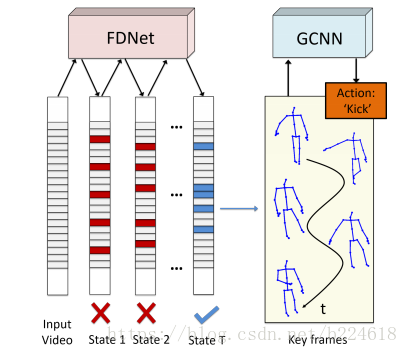
可以看出整个模型大体分为两个部分,FDNet和GCNN。其中FDNet指的是frame distillation network,帧蒸馏网络,形象的将选取最有用的帧的过程用蒸馏来形容。FDNet得到有用的帧之后就要输入到GCNN,也就是graph convolutional neural network里面进行graph convolution,完成动作识别。
强化学习是通过优化选择actions的policy来最大化agent从environment所获得的rewards。文章中说至今为止,在动作识别领域,增强学习的应用还不多。
做skeleton based action recognition会用到人体关节的邻接矩阵,之前做skeleton based action recognition基本都是有骨骼相连的关节对才会在邻接矩阵的相应位置标记一个1,没有连接的位置就标记为0,但本文不同,本文考虑到不相连的关节之间的相互关系也是很重要的,比如两只手不是直接相连的,但是两只手的相互位置关系在识别‘拍手’这个动作时就尤为重要。因此,本文的人体关节邻接矩阵是这么设计的:如果两个关节有连接,就在邻接矩阵相应位置标记为α,称之为intrinsic dependencies,否则标记为β,称之为extrinsic dependencies。此外关节没有self connection,是邻接矩阵对角元素全是0.
本文的卷积操作如下:首先,人体骨架序列是表示成graph 的序列,也就是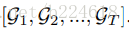
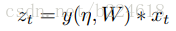
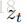
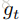
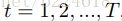


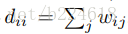
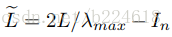
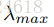
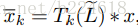
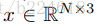
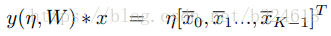
接着介绍FDNet,它的大体过程如下图所示
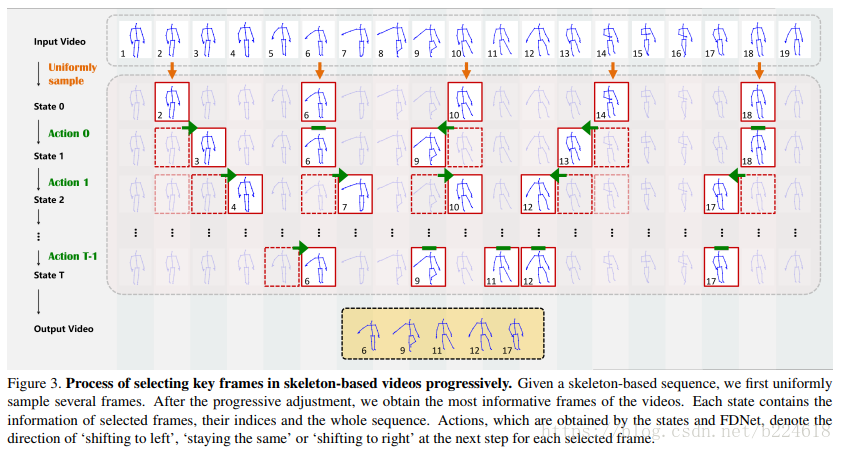
本文将帧的选择过程描述为一个马尔可夫决策过程(Markov decision process,MDP)。有几个概念要先介绍:States,状态,MDP的状态S包含两个部分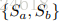
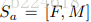
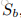
第二个概念,Actions,action指的是调整选取哪些帧所进行的动作,本文模型中有三种action,‘向左移动’、‘向右移动’、‘原地不动’三种,分别记作0、2、1.并且移动的步长定位一帧。这个actions是DFNet的输出,每一次迭代,FDNet都输出一个vector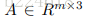
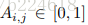

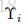

最终,第i帧的调整范围确定为
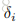

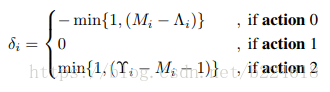
这里面用了min,要达到的效果也就是,如果调整量
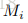


接下来是Rewards的概念,记作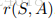
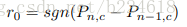


这个Ω是一个较大的数字,这个reward表达式的含义是,如果预测结果从错误跳变到正确,就给一个stimulation,也就是一个大的Ω,如果预测结果从正确跳变到错误,就给一个大的惩罚,就是-Ω,而没有正确错误跳变的时候,就按照r0的表达式给reward。
整个FDNet就是产生action用的,将FDNet所有参数表示为θ,那么FDNet表示为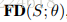
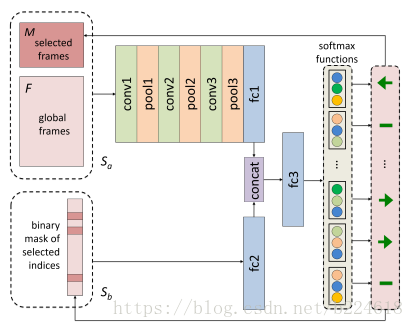
Sa经过卷积层,pooling层,全连接层之后,和经过全连接层的Sb合并起来,输入到同一个全连接层中,经过这层全连接层的线性变换,由softmax层得到action。
接着,文章阐述了一下关于训练网络的内容,首先,目的是要最大化“discounted reward R”,也就是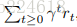
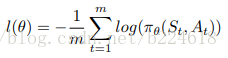
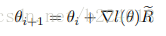


最后作者讲了如何将FDNet和GCNN结合起来,首先,从graph的序列中均匀的选出一些frames,用它们来训练GCNN,之后将GCNN的参数固定,再来训练FDNet,而训练过的FDNet又能够精细调节GCNN, 就这样两者互帮互助。