Tensorflow:一个用于计算的框架。Tensorflow架构中分为设备管理和通信层、数据操作层、图计算层、API接口层、应用层。Tensorflow使用的符号编程而不是一般的命令编程,符号式编程将计算过程抽象为计算图,计算流图可以方便的描述计算过程,所有输入节点、运算节点、输出节点均符号化处理。计算图通过建立输入节点到输出节点的传递闭包,从输入节点出发,沿着传递闭包完成数值计算和数据流动,直到达到输出节点。这个过程经过计算图优化,以数据(计算)流方式完成,节省内存空间使用,计算速度快,但不适合程序调试。tf也引入mutation中,可以在计算的过程更改一个变量的值,而这个变量在计算的过程中会被带入到下一轮迭代里面去。tensorflow更加适用于大型的神经网络运行,对于小型的网络实际网络计算的时间可能占用少数时间而其他诸如检测启动部署等任务的时间占用大部分.
TensorFlow基本使用策略是构建图之后训练然后检测。“tensor”意为数据,参数使用Variable来表示,占位符使用placeholder用来接受输入数据,真正执行是在Session中。构建阶段主要是定义参数变量、常量和占位符,定义各个参数之间的计算,定义损失函数和训练方法,定义测试方法。实际训练阶段采用Session的run方法借助于feed机制和fetch机制,传入数据数据,训练工作由tensorflow完成,就是改变参数的过程。之后进行测试。
tensorflow中定义变量必须附初值,可以直接附,可以由另外变量赋值,但是必须在所有训练代码之前执行tf.global_all_variables()操作并且session.run()。tf.train.Saver类的save()方法和restore()方法实现模型的存储和恢复。使用tensor.eval()函数等价于使用tf.get_default_session().run(tensor),sess.run()在同一步获取多个tensor中的值,他们都会执行计算图。
tensorflow支持分布式训练,模式是固定的, 可变的只有graph的构建和执行训练的代码,其他都是按部就班:
# 第1步:命令行参数解析,获取集群的信息ps_hosts和worker_hosts,以及当前节点的角色信息job_name和task_index
# 第2步:创建当前task结点的Server
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
# 第3步:如果当前节点是ps,则调用server.join()无休止等待;如果是worker,则执行第4步。
if FLAGS.job_name == "ps":
server.join()
# 第4步:则构建要训练的模型
# build tensorflow graph model
# 第5步:创建tf.train.Supervisor来管理模型的训练过程
# Create a "supervisor", which oversees the training process.
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), logdir="/tmp/train_logs")
# The supervisor takes care of session initialization and restoring from a checkpoint.
sess = sv.prepare_or_wait_for_session(server.target)
# Loop until the supervisor shuts down
while not sv.should_stop()
# train model
tensorflow中的tf.nn.conv2d(input,filter,strides,padding,name)简要原理:input中的四个参数为[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],而filter参数意为
[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数即卷积层的层数],由于图片的二维性所以strides一般取[1,a,a,1]。padding取值SAME或者VALID值,VALID根据输入
数据的宽度和filter的宽度以及步长来决定是否丢弃图片最右侧的数据,不合适就丢弃,而SAME则适当的填充0。tf.nn.max_pool(value,ksize,striders,padding),其中value: 一个
4D张量,格式为[batch, height, width, channels],与conv2d中input格式一样;ksize: 长为4的list,表示池化窗口的尺寸; strides: 窗口的滑动值,与conv2d中的一样; padding:
与conv2d中用法一样。
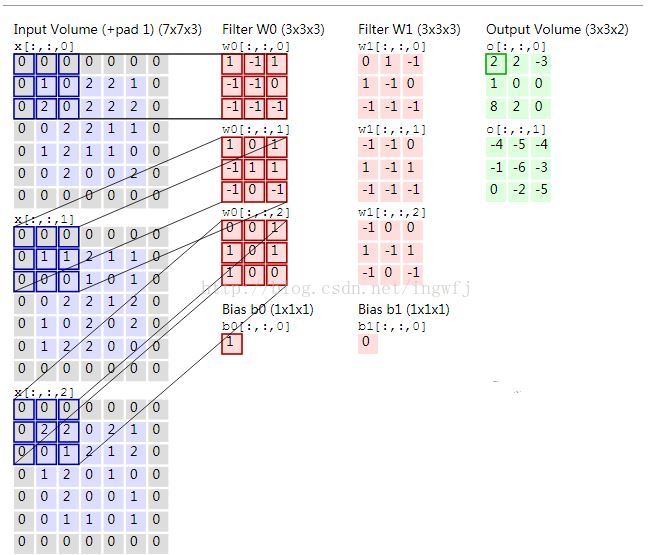
tensorflow常用方法:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)而且卷积层:input:待卷积的数据。格式要求为一个张量,[batch, in_height, in_width, in_channels]. 分别表示 批次数,图像高度,宽度,输入通道数。 filter: 卷积核。格式要求为[filter_height, filter_width, in_channels, out_channels]. 分别表示 卷积核的高度,宽度,输入通道数,输出通道数。 strides :一个长为4的list. 表示每次卷积以后卷积窗口在input中滑动的距离 padding :有SAME和VALID两种选项,表示是否要保留图像边上那一圈不完全卷积的部分。如果是SAME,则保留 。
tf.nn.max_pool(value, ksize, strides, padding, data_format="NHWC", name=None)最大池化操作:value: 一个4D张量,格式为[batch, height, width, channels]。其他同上。
tf.ones()或tf.zeros(shape,type=tf.float32,name=None)全1或全0
tf.ones_like(tensor,dype=None,name=None) 或tf.zeros_like()新建一个与给定的tensor类型大小一致tensor,其所有元素为1和0;
tf.fill(shape,value,name)创建一个形状大小为shape的tensor,其初始值为value;
tf.constant(value,dtype,shape,name)创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状。value可以是一个数,也可以是一个list。 如果是一个数,那么这个常亮中所有值的按该数来赋值。 如果是list,那么len(value)一定要小于等于shape展开后的长度。赋值时,先将value中的值逐个存入。不够的部分,则全部存入value的最后一个值;
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None) 、tf.truncated_norm()和tf.random_uniiform(),生成正态分布和均匀分布,参数分别代表着形状、均值、标准差、类型、种子和名称;
tf.shape(Tensor)返回Tensor的shape;
tf.expand_dims(Tensor, dim)在dim轴处增加一维;
tf.pack(values,axis,name)将一个R维张量列表沿着axis轴组合成一个R+1维的张量。
tf.concat(concat_dim, values, name=”concat”)将张量沿着指定维数拼接起来。
tf.sparse_to_dense()稀疏矩阵转为密集矩阵;
tf.random_shuffle(value,seed,name)沿着value的第一维随机打乱再排列;
tf.get_variable(name,shape,dtype,initializer)按照指定的初始化方法初始化变量;
tf.argmax(tensor,axis)或tf.argmin()找到给定的张量tensor中在指定轴axis上的最大值/最小值的位置。
tf.equal(x, y, name=None): 判断两个tensor是否每个元素都相等。
tf.cast(x, dtype, name=None) 将x的数据格式转化成dtype;
tf.matmul(a, b, transpose_a=False, transpose_b=False, a_is_sparse=False, b_is_sparse=False, name=None):矩阵乘法
tf.reshape(tensor, shape, name=None) 将tensor按照新的shape重新排列。如果 shape=[-1], 表示要将tensor展开成一个list 如果 shape=[a,b,c,…] 其中每个a,b,c,..均>0,那么就是常规用法 如果 shape=[a,-1,c,…] 此时b=-1,a,c,..依然>0。这表示tf会根据tensor的原尺寸,自动计算b的值。
tf.nn.enmbedding_lookup
tf.trainable_variables()返回所有可训练的变量,默认variable是trainable的,而constant不是。
tf.gradients(ys,xs,...)返回ys中国每个值对xs[i]求导的结果。
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)梯度修建方法
tf.nn.dropout(x,keep_prob,noise_shape,seed,name)即为dropout技术。
tf.linespac(start,stop,num,name)和tf.range(start,limit,delta,name)用于产生等差数列。
tf.assign(ref,value,validate-shape,use_locking,name)复制操作
tensorflow中处理图像的函数:
tf.image.resize_images(images, size, method=ResizeMethod.BILINEAR, align_corners=False),根据method取值0、1、2、3采用不同的调整方法。
tf.image.resize_image_with_crop_or_pad(images,height,width)裁剪或填充图片。
图像反转函数:tf.image.flip_up_down()/flip_left_right()/transpose_image()/random_flip_up_down/random_flip_left_right(img_data) ;
tensorflow还支持调整图像的亮度、对比度、色相、饱和度和标准化函数。
tensorflow加载数据的方式:使用constant或Variable来保存变量等待使用;使用占位符来填充数据;从TFRecords数据文件中读取。
tensorflow通过在运行tf.app.run() 之前可以通过tf.app.flags来设置所需要的参数,它支持应用从命令行接受参数,可以用来指定集群配置等。tf.app.flags可以定义各种变量值和变量名。
reshape()方法中传参shape中的-1代表由系统计算该维的维度而不去实际指定。
tensorflow中不是只有placehloder才能feed_dict的,只要是feedable的tensor都可以。
用另一个Variable初始化一个Variable时,要注意使用initialized_value()。
Tensorflow提供的数学运算包括tf.add/mul/sub/div/mod/abs/neg/sign/inv/square/round/pow/sqrt/exp/log/cos/sin/maximum/minimum,以及tf.diag/transpose/matmul/matrix_determinant/matrix_inverse。
tensorflow中提供的按照tensor某个axis进行计算的方法包括tf.reduce_mean()/tf.reduce_sum()/tf.reduce_all()/tf.reduce_sum()/tf.reduce_max()/tf.reduce_min()/tf.reduce_any()等,按照设定的axis求该轴的某个统计量值。axis=0表示列,axis=1表示行。
tf.slice(inputs,begin ,size,name)代表从inputs抽取部分内容,inputs是输入数据,tensor或者list或者array,begin则是n维列表,begin[i]代表第i维是从begin[i]开始抽取数据,size[i]表示要抽取的第i维元素的数目;tf.slice(input,axis,name,dim)在axis轴增加一个维度,而在tf.squeeze()是压缩维度。
tensorflow中提供的对tensor变换的方法有tf.shape()/tf.rank()/tf.size()/tf.reshape()/tf.squeeze()/tf.expand_dims()/tf.slice()/tf.split()/tf.tile()/tf.concat()/tf.reverse()/tf.transpose()/tf.gather()等。生成tensor的方式由tf.fill()/tf.zeros_like()/tf.ones_like()/tf.constant()/tf.Variable()等。按照某种分布生成数据的方式有tf.random_normal()/tf.random_uniform()/tf.truncated_normal()/tf.random_shuffle()/tf.set_random_seed()。
Tensorflow中的队列(FIFOQueue,RandomShuffleQueue)在一部计算中发挥作用,队列也是图中的一个节点,可以dequeue()也可以enqueue(),他的状态可以由其他节点改变。可以在填入输入数据时使用多线程将数据推入队列中,之后一个线程来训练,而Tensorflow中的tf.train.Coordinator类可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常。QueueRunner类用来协调多个工作线程同时将多个张量推入同一个队列中。同时Session是支持多线程的。
tensorflow对RNN的支持:主要的几个类为tf.nn.rnn_cell.RNNCell(BasicRNNCell / BasicLSTMCell子类),tf.nn.dynamic_rnn,tf.nn.rnn_cell.MultiRNNCell。RNNCell是一个抽象类,代表RNN的细胞,传入参数主要是隐藏层神经元数和激活函数,最主要的方法是(output, next_state) = call(input, state),参数是该时刻的输入数据和上一个时刻的隐藏层状态,返回值是该时刻输出值和该时刻的隐藏层状态,对于BasicRNNCell的call返回参数next_state是一个状态变量h,对于BasicLSTMCell的call返回参数next_state是h和c,调用一次call方法相当于在时刻上前进一步,当然前提是已经对输入数据进行了预处理使其能够满足tensorflow的要求并且各个变量已经初始化。outputs, state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state),outputs就是time_steps步里所有的输出, 它的形状为(batch_size, time_steps, cell.output_size)。state是最后一步的隐状态,它的形状为(batch_size, cell.state_size)。tf.nn.rnn_cell.MultiRNNCell函数对RNNCell进行堆叠从而形成多层的RNN结构,MultiRNNCell得到的也是RNNCell类,一般RNN最好的是三层隐藏层加上一个输出层。实际通过RNNCell.call()方法返回的output和next_state一样的,所以给output_size就能够输出,所以该output是没有经过变换的输出也就不是真正的每一时刻的输出。如果想要实际训练一个rnn模型需要的工作量要比仅仅构建模型多得多。
tf.contrib.layers.embed_sequence(idx,vocab_size, embed_dim)可完成对输入序列数据的嵌入工作,ids: 形状为[batch_size, doc_length]的int32或int64张量,也就是经过预处理的输入数据。vocab_size: 输入数据的总词汇量,指的是总共有多少类词汇,不是总个数;embed_dim:想要得到的嵌入矩阵的维度。
tensorflow中的with与python中的with作用不同,在该with域内的变量一定是属于该域的,但是离开该with之后该域仍然存在。在 TensorFlow 中,我们定义一个变量,相当于往 Graph 中添加了一个节点。和普通的 python 函数不一样,在一般的函数中,我们对输入进行处理,然后返回一个结果,而函数里边定义的一些局部变量我们就不管了。但是在 TensorFlow 中,我们在函数里边创建了一个变量,就是往 Graph 中添加了一个节点。出了这个函数后,这个节点还是存在于 Graph 中的。
tensorflow中的name_scope和variable_scope:name_scope是为了更好的管理变量名形成树形的层状结构,variable_scope是为了与get_variable()共同使用来实现参数共享。tf.name_scope() 并不会对 tf.get_variable() 创建的变量有任何影响。。因为tensorflow中创建的变量有placeholder/Variable/get_variable三种,包括操作在内都有自己的name,之所以有name是为了实现图节点的管理。name_scope()的name会附加到Variable和placeholder的name作为该变量的名字,但是不会附加到get_variable()变量的名称上。当一个函数中的变量来源于tf.Variable()时结果是调用多少次该函数则创建多少遍这个变量,但是使用tf.get_variable()配合tf.variable_scope()来使用则实现参数共享:
# 下面是定义一个卷积层的通用方式
def conv_relu(kernel_shape, bias_shape):
# Create variable named "weights".
weights = tf.get_variable("weights", kernel_shape, initializer=tf.random_normal_initializer())
# Create variable named "biases".
biases = tf.get_variable("biases", bias_shape, initializer=tf.constant_initializer(0.0))
return ......
def my_image_filter():
# 按照下面的方式定义卷积层,非常直观,而且富有层次感
with tf.variable_scope("conv1"):
# Variables created here will be named "conv1/weights", "conv1/biases".
relu1 = conv_relu([5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# Variables created here will be named "conv2/weights", "conv2/biases".
return conv_relu( [5, 5, 32, 32], [32])
with tf.variable_scope("image_filters") as scope:
# 下面我们两次调用 my_image_filter 函数,但是由于引入了 变量共享机制,只是创建了一遍网络结构。
result1 = my_image_filter()
scope.reuse_variables()
result2 = my_image_filter()
# 实现了变量共享
vs = tf.trainable_variables()
print 'There are %d train_able_variables in the Graph: ' % len(vs)
for v in vs:
print vTensor("image_filters/conv1/weights/read:0", shape=(5, 5, 32, 32), dtype=float32)
Tensor("image_filters/conv1/biases/read:0", shape=(32,), dtype=float32)
Tensor("image_filters/conv2/weights/read:0", shape=(5, 5, 32, 32), dtype=float32)
Tensor("image_filters/conv2/biases/read:0", shape=(32,), dtype=float32tensorflow中张量操作:http://blog.csdn.net/qq_15807167/article/details/63686855
tensorflow中函数操作集合:http://www.jianshu.com/p/5184802ff646
tensor中nn模块函数:http://www.tensorfly.cn/tfdoc/api_docs/python/nn.html,http://www.jianshu.com/p/e3a79eac554f
tensorflow中的train模块和Graph模块:http://blog.csdn.net/tingxueyou/article/details/52782016,http://blog.csdn.net/tingxueyou/article/details/52861799
tensorflow改进:http://blog.csdn.net/marsjhao/article/details/72831021